
A Survey of Reinforcement Learning for Large Reasoning Models
Authors: Kaiyan Zhang, Yuxin Zuo, Bingxiang He, Youbang Sun, Runze Liu, Che Jiang, Yuchen Fan, Kai Tian, Guoli Jia, Pengfei Li, Yu Fu, Xingtai Lv, Yuchen Zhang, Sihang Zeng, Shang Qu, Haozhan Li, Shijie Wang, Yuru Wang, Xinwei Long, Fangfu Liu, Xiang Xu, Jiaze Ma, Xuekai Zhu, Ermo Hua, Yihao Liu, Zonglin Li, Huayu Chen, Xiaoye Qu, Yafu Li, Weize Chen, Zhenzhao Yuan, Junqi Gao, Dong Li, Zhiyuan Ma, Ganqu Cui, Zhiyuan Liu, Biqing Qi, Ning Ding, Bowen Zhou
Paper: https://arxiv.org/abs/2509.08827
Code: https://github.com/TsinghuaC3I/Awesome-RL-for-LRMs
TL;DR
WHAT was done? This paper provides a comprehensive and systematic survey of Reinforcement Learning (RL) as a foundational methodology for transforming Large Language Models (LLMs) into Large Reasoning Models (LRMs). It charts the field's evolution from using RL for human alignment (e.g., RLHF, DPO) to leveraging it to directly incentivize and scale complex reasoning capabilities. The survey meticulously reviews the core pillars of this new paradigm: foundational components like reward design and policy optimization, critical unresolved problems such as the "sharpening vs. discovery" debate, the ecosystem of training resources including datasets and dynamic environments, and a wide array of downstream applications from coding to robotics.
WHY it matters? This work is crucial because it consolidates the scattered progress in a rapidly evolving field and frames RL as a new, critical scaling axis for AI capabilities, complementary to traditional pre-training. By enabling models to learn from verifiable outcomes and self-generated data, RL offers a path to overcoming data annotation bottlenecks and fostering more robust, generalizable reasoning. For researchers and practitioners, this survey serves as an essential roadmap, clarifying the state of the art, highlighting key intellectual debates, and outlining a clear vision for future research aimed at achieving Artificial SuperIntelligence (ASI) through more capable and autonomous reasoning systems.

Details
Introduction: From Aligned Behavior to Incentivized Reasoning
For the past several years, Reinforcement Learning (RL) has been instrumental in shaping the behavior of Large Language Models (LLMs). Techniques like Reinforcement Learning from Human Feedback (RLHF) (https://arxiv.org/abs/1706.03741) and Direct Preference Optimization (DPO) (https://arxiv.org/abs/2305.18290) have become standard practice for aligning models with human preferences, making them more helpful, honest, and harmless. However, a new and transformative trend has emerged, one that uses RL not just to align behavior, but to directly incentivize and scale reasoning itself. This comprehensive survey meticulously charts this evolution, providing a structured overview of how RL is being used to create what the authors term Large Reasoning Models (LRMs).
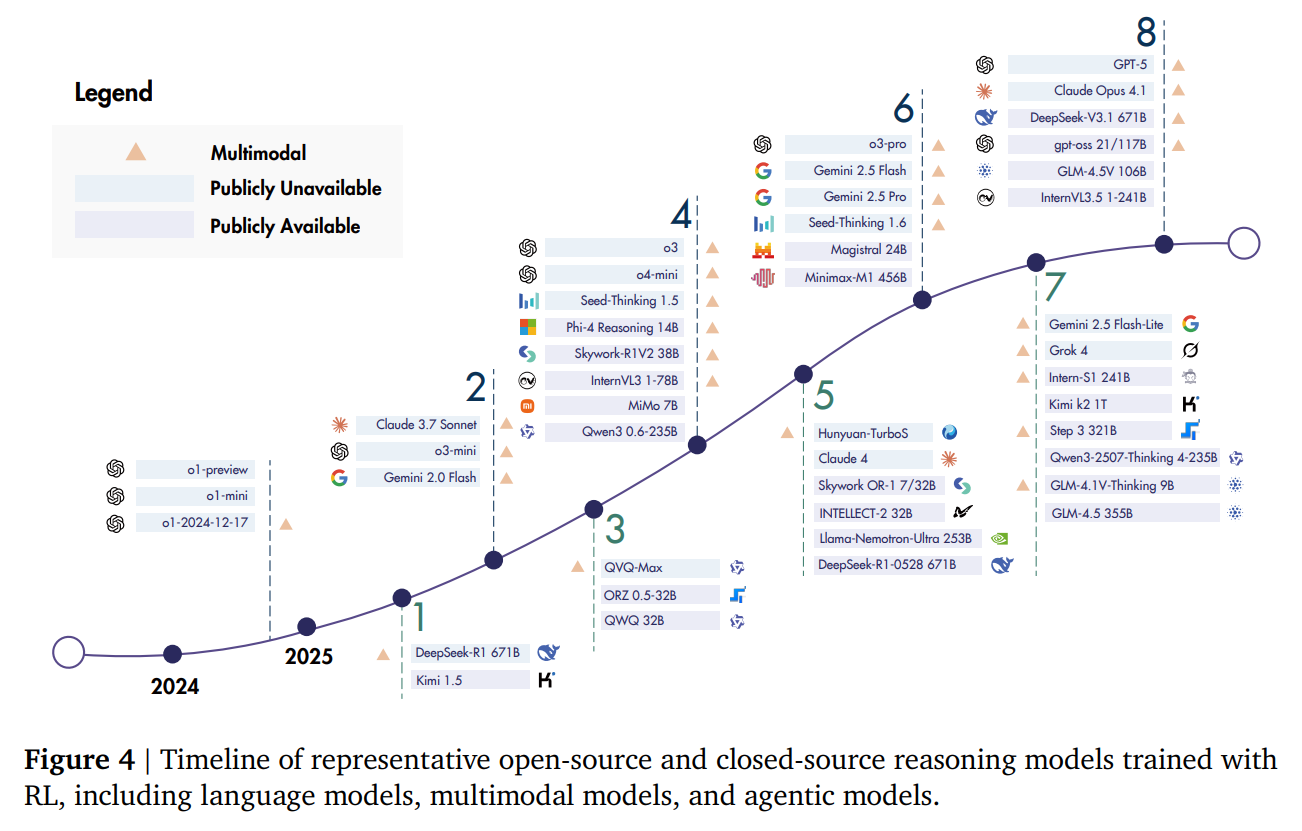
This shift represents a natural evolution in the field. As models mastered conversational fluency through alignment, the next grand challenge became deep, multi-step reasoning. The authors of this survey argue that for these complex domains, the old playbook of supervised fine-tuning on human data is reaching its limits. Reinforcement Learning, with its ability to learn from sparse, outcome-based rewards, offers a powerful new path forward—a way to teach models not just what to say, but how to think. Landmark models like OpenAI's o1 (https://arxiv.org/abs/2412.16720) and DeepSeek-R1 (https://arxiv.org/abs/2501.12948) signal this paradigm shift. These models demonstrate that by applying RL with objective, verifiable rewards, it's possible to unlock long-form reasoning, planning, reflection, and self-correction. This introduces a new scaling axis for AI—one where performance improves with more computational effort dedicated to RL training and inference-time "thinking"—which is complementary to scaling data and parameters during pre-training (Figure 2).

A Systematic Framework for RL in Reasoning Models
The survey's primary strength lies in its systematic and comprehensive structure, which organizes the vast landscape of recent work into a coherent taxonomy (Figure 1). It deconstructs the application of RL for LRMs into four key areas: foundational components, foundational problems, training resources, and applications.
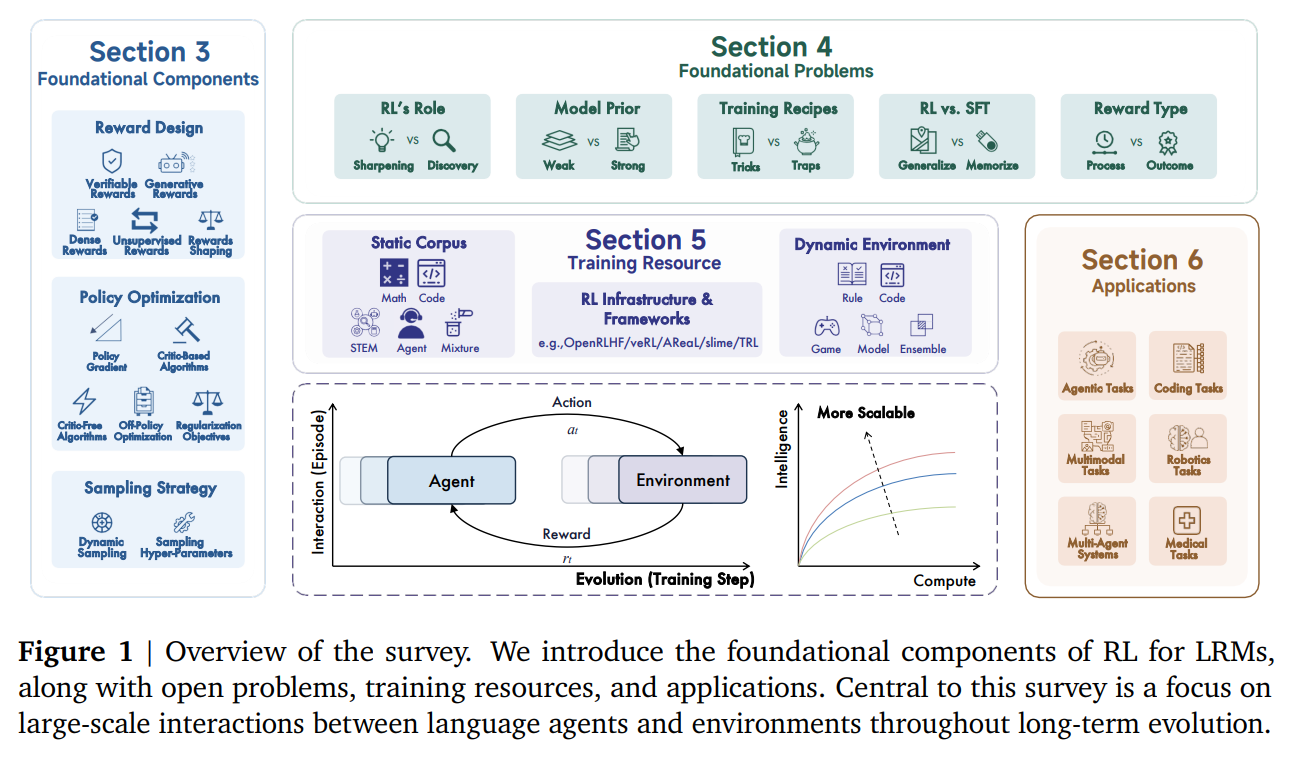
Foundational Components: The Building Blocks of RL for LRMs
The authors provide a deep dive into the core technical elements required to train LRMs with RL (see Figure 5 in the paper).
1. Reward Design: The nature of the reward signal is paramount. The survey identifies a clear trend moving away from sparse, subjective signals towards more robust and scalable alternatives:
Verifiable Rewards (RLVR): For tasks like math and coding where correctness can be automatically checked, rule-based rewards provide a reliable and scalable training signal. This principle is encapsulated in "Verifier's Law," which suggests that a task's amenability to AI improvement is proportional to its verifiability.
Generative Reward Models (GenRMs): To tackle subjective domains, GenRMs are trained to produce nuanced, text-based critiques and rationales, effectively learning to "think" before judging.
Dense and Process Rewards: To guide long chains of thought, dense rewards provide step-by-step feedback. While challenging to scale, they offer fine-grained credit assignment and improve training stability.
Unsupervised Rewards: To overcome the human annotation bottleneck, methods are emerging that derive rewards from the model's own internal consistency, confidence, or from large, unlabeled data corpora.
2. Policy Optimization: The survey contrasts different optimization strategies, highlighting a move towards greater efficiency and stability:
Critic-Based vs. Critic-Free: While traditional PPO with a learned critic is powerful, it carries significant computational overhead. For tasks with verifiable rewards, critic-free algorithms like Group Relative Policy Optimization (GRPO) have become dominant. GRPO normalizes rewards against a group of responses, reducing variance and simplifying the training process without a separate critic model. The advantage for a given response
y_iin a group of sizeGis calculated as: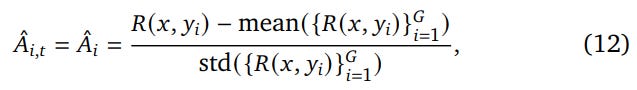
What makes this formula so effective is its ability to create a rich 'gradient' of feedback. Instead of treating all correct answers as equally good (a reward of +1), GRPO scores each response relative to the average quality of other attempts on the same problem. This pushes the model not just to find a correct answer, but to discover better, more efficient, or more elegant correct answers, providing a far more stable and informative learning signal.
Off-Policy Learning and Regularization: To improve sample efficiency, modern methods increasingly mix on-policy RL with off-policy data from historical rollouts or supervised datasets. Stability is further enhanced through regularization techniques like KL divergence and entropy maximization, which prevent catastrophic policy drift and encourage exploration.
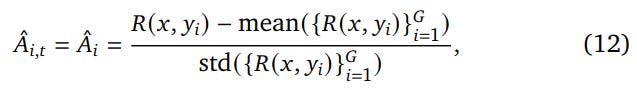
3. Sampling Strategy: Effective RL depends on actively curating high-quality training data. The survey covers dynamic and structured sampling techniques that focus computational resources on informative examples and align the generation process with the underlying structure of the problem.
Foundational Problems: The Field's Core Debates
A standout section of the survey addresses the critical, unresolved debates that define the research frontier:
Sharpening vs. Discovery: Does RL merely refine and re-weight correct reasoning paths already latent within a pre-trained model ("sharpening"), or can it facilitate the emergence of genuinely novel problem-solving strategies ("discovery")? The paper presents evidence for both views but proposes a unified perspective: the debate is not about what RL can do, but about how it navigates the exploration-exploitation trade-off. RL's tendency to concentrate on high-reward strategies provides a powerful mechanism for sharpening pre-existing knowledge. Simultaneously, its framework for sequential decision-making allows it to compose existing skills into genuinely novel solutions, enabling discovery when given enough time and the right incentives.
Generalization vs. Memorization (RL vs. SFT): The authors synthesize findings indicating that RL tends to promote better out-of-distribution generalization, whereas Supervised Fine-Tuning (SFT) can lead to memorization and catastrophic forgetting. The trend points towards hybrid paradigms that leverage the strengths of both.
The Influence of Model Priors: A crucial practical insight is that the base model's architecture and pre-training data significantly impact its responsiveness to RL. Some model families (e.g., Qwen) appear more "RL-friendly," while others may require careful "mid-training" with high-quality, in-domain data to unlock their reasoning potential.
The Ecosystem: An Actionable Toolkit for Practitioners
Beyond its conceptual framework, the survey provides immense practical value through its comprehensive catalog of training resources. For any team looking to enter this field, Tables 4, 5, and 6 are a goldmine, offering an actionable roadmap to the essential datasets, interactive training environments, and open-source software needed to build and train the next generation of LRMs. This is a paper that not only tells you what is happening but gives you the tools to get involved.
The survey details a growing list of static datasets tailored for RL across math, code, STEM, and agentic tasks (Table 4).
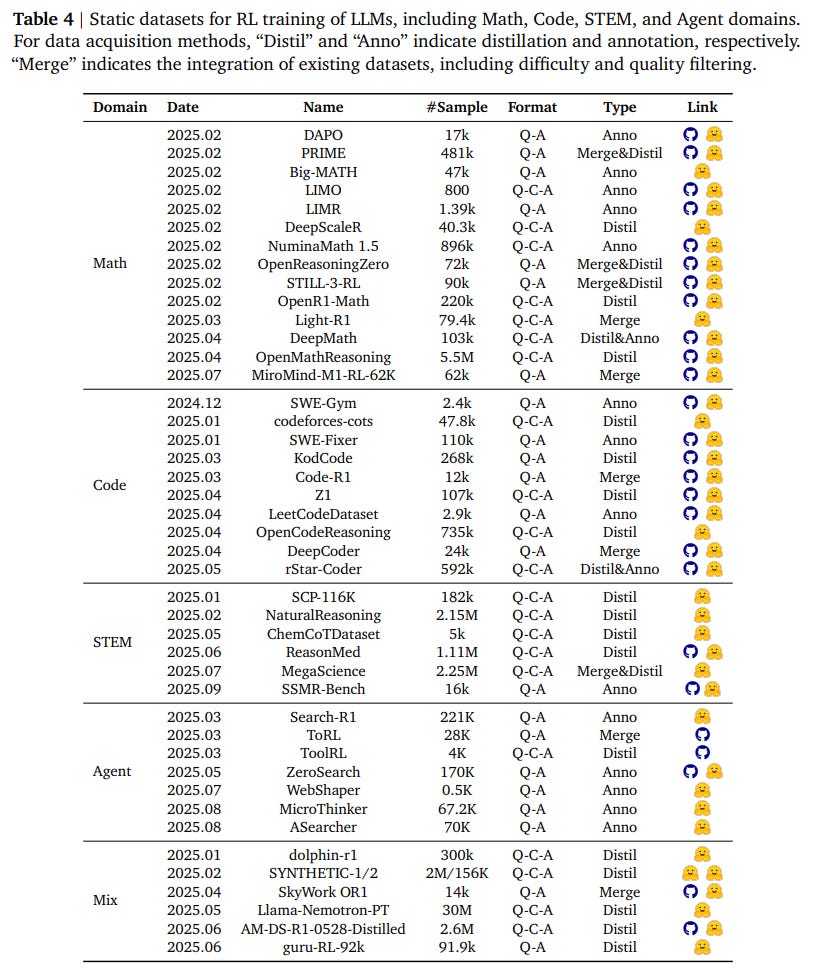
Recognizing the limitations of static data, it also maps out the expanding landscape of dynamic, interactive environments—from code compilers to game simulators—that allow for limitless data generation and more realistic agent training (Table 5).
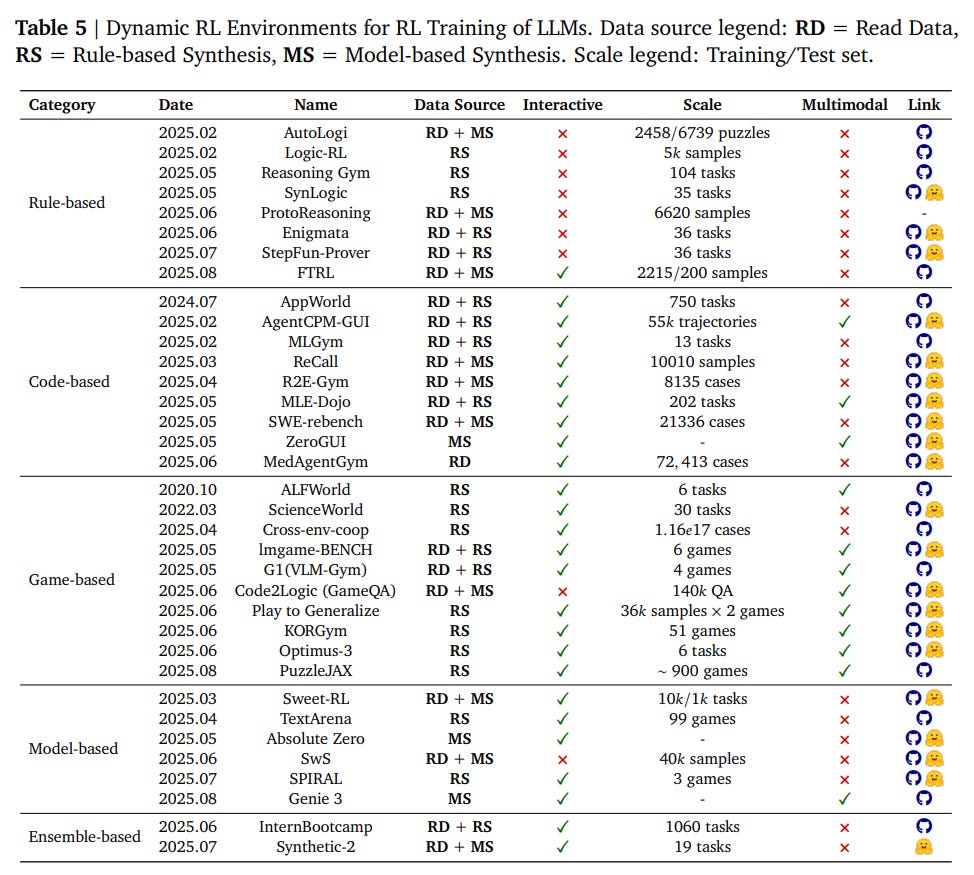
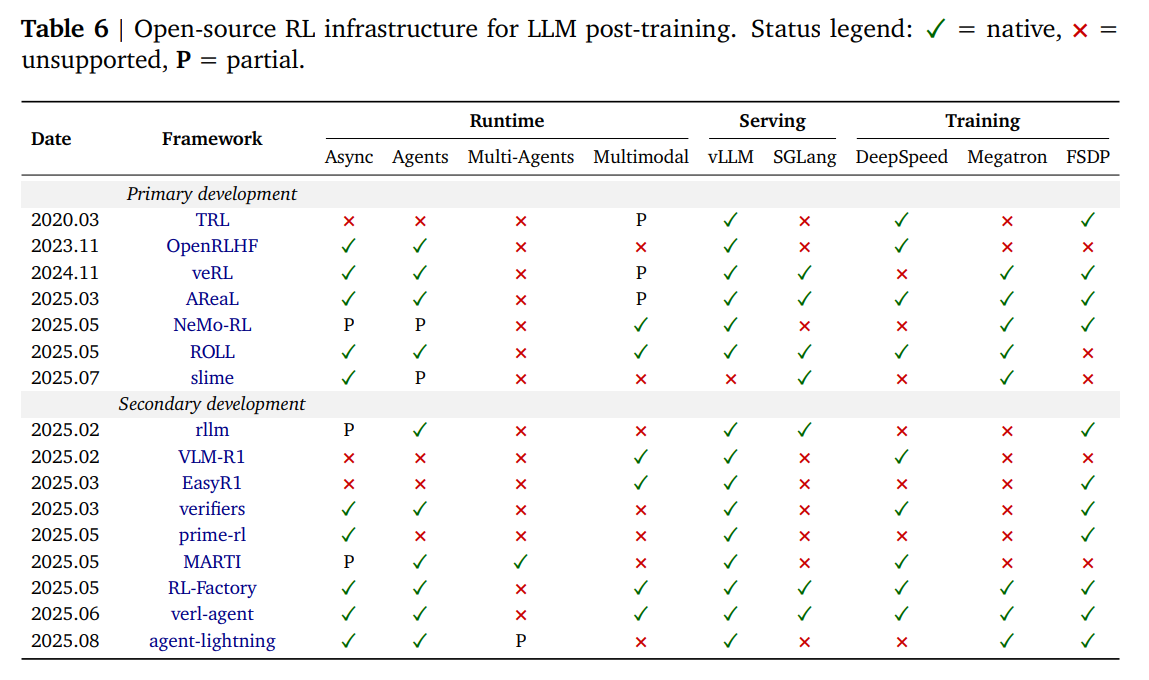
Finally, it reviews the open-source RL infrastructure (e.g., TRL, OpenRLHF, Verl, AReaL) that enables scalable, distributed training (Table 6).
Applications and the Path Forward
The practical impact of these advancements is demonstrated across a wide range of applications, including sophisticated code generation, autonomous agentic systems, multimodal reasoning, robotics, and medical diagnostics (see Figure 6 in the paper). The remarkable progress in Coding and Math is a direct result of the maturation of Verifiable Rewards. Conversely, the challenges in building robust Agentic Systems for open-ended tasks highlight precisely why the development of Generative and Unsupervised Rewards is such a critical research frontier.
Looking ahead, the authors outline several promising research directions. These include developing methods for continual and memory-based RL to create more adaptive agents, integrating model-based RL by building world models, teaching LRMs efficient and latent-space reasoning, and exploring the use of RL during pre-training. Perhaps most ambitiously, the paper calls for research into RL for architecture-algorithm co-design, where the RL agent learns not only to generate tokens but also to dynamically adapt the model's architecture for optimal performance and efficiency.
Conclusion
This survey is more than a simple literature review; it is a meticulously crafted synthesis that provides a clear narrative and a structured framework for understanding the pivotal role of Reinforcement Learning in advancing AI reasoning. It convincingly argues that the field is moving beyond aligning models with human preferences and is now squarely focused on building more fundamentally intelligent systems. By consolidating recent advances, articulating core challenges, and providing a visionary roadmap for the future, this work serves as an indispensable resource for any researcher or practitioner aiming to contribute to the development of the next generation of Large Reasoning Models.
Hey, great read as always. This survey realy frames RL as the critical scaling axis I've been thinking about for LRMs, much like your other insightful pieces.