
AlphaEarth Foundations: An embedding field model for accurate and efficient global mapping from sparse label data
Authors: Christopher F. Brown, Michal R. Kazmierski, Valerie J. Pasquarella, William J. Rucklidge, Masha Samsikova, Chenhui Zhang, Evan Shelhamer, Estefania Lahera, Olivia Wiles, Simon Ilyushchenko, Noel Gorelick, Lihui Lydia Zhang, Sophia Alj, Emily Schechter, Sean Askay, Oliver Guinan, Rebecca Moore, Alexis Boukouvalas and Pushmeet Kohli
Paper: https://arxiv.org/abs/2507.22291
Blog: https://deepmind.google/discover/blog/alphaearth-foundations-helps-map-our-planet-in-unprecedented-detail/
Data:
Satellite Embedding v1 (Annual Embeddings): https://developers.google.com/earth-engine/datasets/catalog/GOOGLE_SATELLITE_EMBEDDING_V1_ANNUAL
Supplemental Evaluation Datasets: https://doi.org/10.5281/zenodo.16585402
Supplemental Training Coordinates: https://doi.org/10.5281/zenodo.16585910
TL;DR
WHAT was done? The authors introduce AlphaEarth Foundations (AEF), a geospatial foundation model that creates a universal, time-continuous "embedding field" for the entire planet. AEF assimilates petabytes of data from diverse sources—including optical, radar (SAR), LiDAR, climate, and geotagged text—into a single, compact (64-byte), and high-resolution (10m) representation. The model is built on a novel Space Time Precision (STP) encoder and trained with a multi-objective loss that includes reconstruction, a teacher-student consistency objective for robustness to data sparsity, a batch uniformity objective to maximize embedding space utilization, and a CLIP-like loss for aligning with semantic text.
WHY it matters? AEF marks a paradigm shift in Earth Observation AI. It is the first task-agnostic model to consistently outperform all tested baselines—both engineered and learned—across a wide range of mapping applications without any re-training, reducing error by ~24% on average. By effectively translating sparse labels into detailed global maps, it tackles the dual challenges of data scarcity and volume. The public release of annual embedding fields from 2017-2024 democratizes access to high-performance geospatial analysis, enabling practitioners to build advanced monitoring systems for food security, conservation, and disaster response with unprecedented efficiency.

Details
For decades, the field of Earth Observation (EO) has faced a fundamental paradox: an unprecedented deluge of satellite and environmental data, yet a persistent drought of high-quality, ground-truth labels. This has led to a landscape of bespoke models, each tailored to a specific task, sensor, or region. While recent advances in learned featurizations have shown promise, no single approach has managed to consistently outperform others across the diverse spectrum of geospatial tasks. A new paper from Google DeepMind, "AlphaEarth Foundations," introduces a model that marks a significant shift in this paradigm, moving from fragmented solutions to a unified, foundational approach for understanding our planet.
The AlphaEarth Foundations Approach: A Universal Feature Space
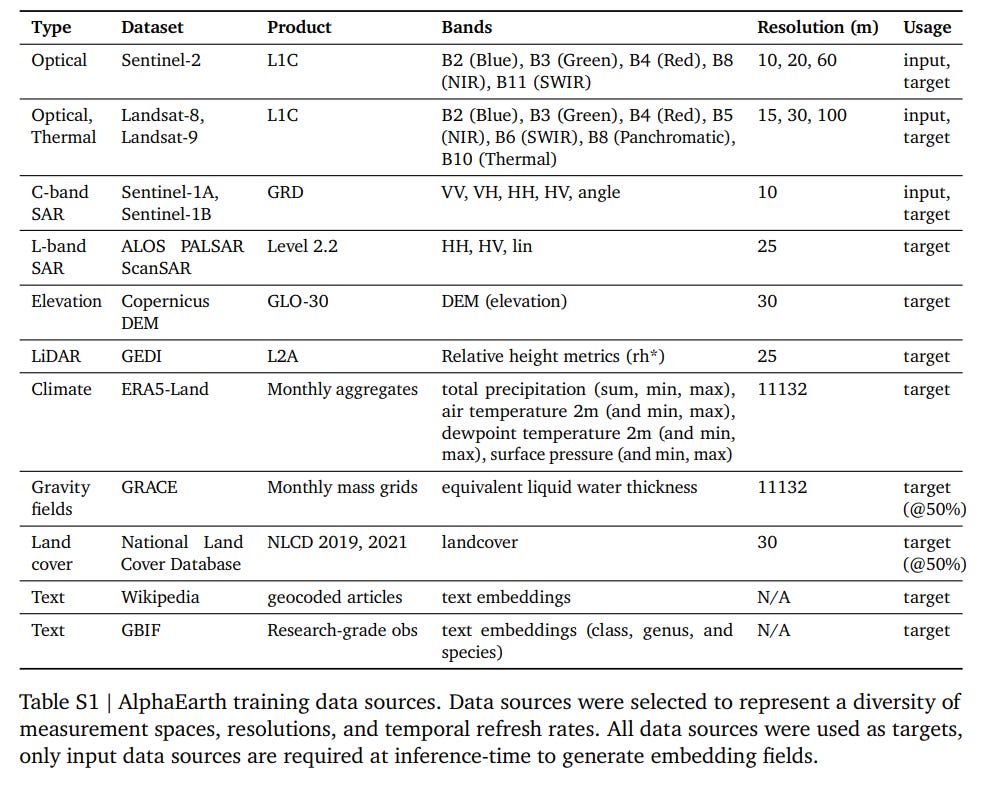
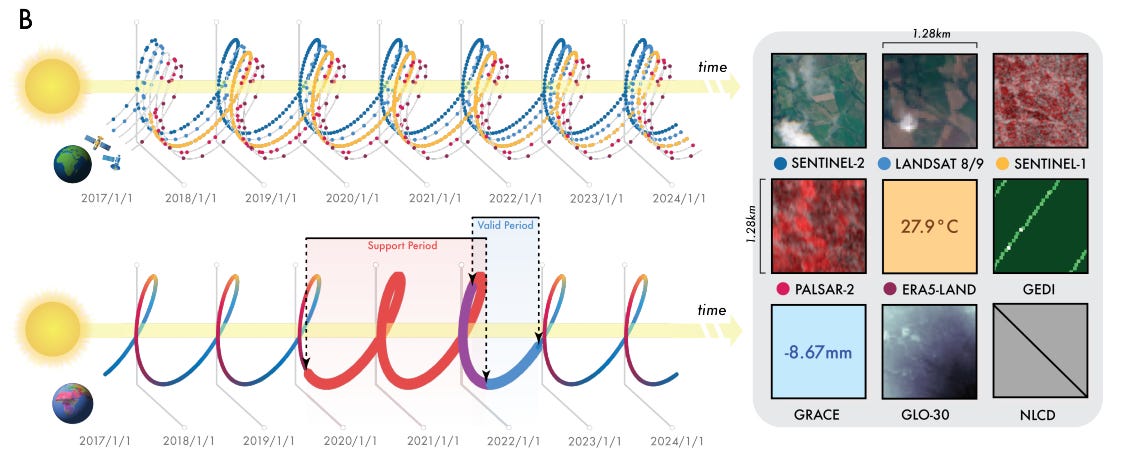
The core contribution of the paper is AlphaEarth Foundations (AEF), an embedding field model that generates a universal, task-agnostic representation of the Earth. Instead of creating bespoke features, AEF learns a single, rich embedding for any 10m² patch of the planet by assimilating information from a vast and diverse array of sources. These include optical (Sentinel-2, Landsat), radar (Sentinel-1, PALSAR-2), LiDAR (GEDI), and even unstructured geotagged text from Wikipedia and the Global Biodiversity Information Facility (GBIF) (Table S1).
This is achieved through a novel architecture and a sophisticated multi-objective training process.
Architecture and Training
The model's architecture (Figure 2) is designed to handle the unique challenges of EO data—its multimodality, spatial-temporal nature, and inherent sparsity.
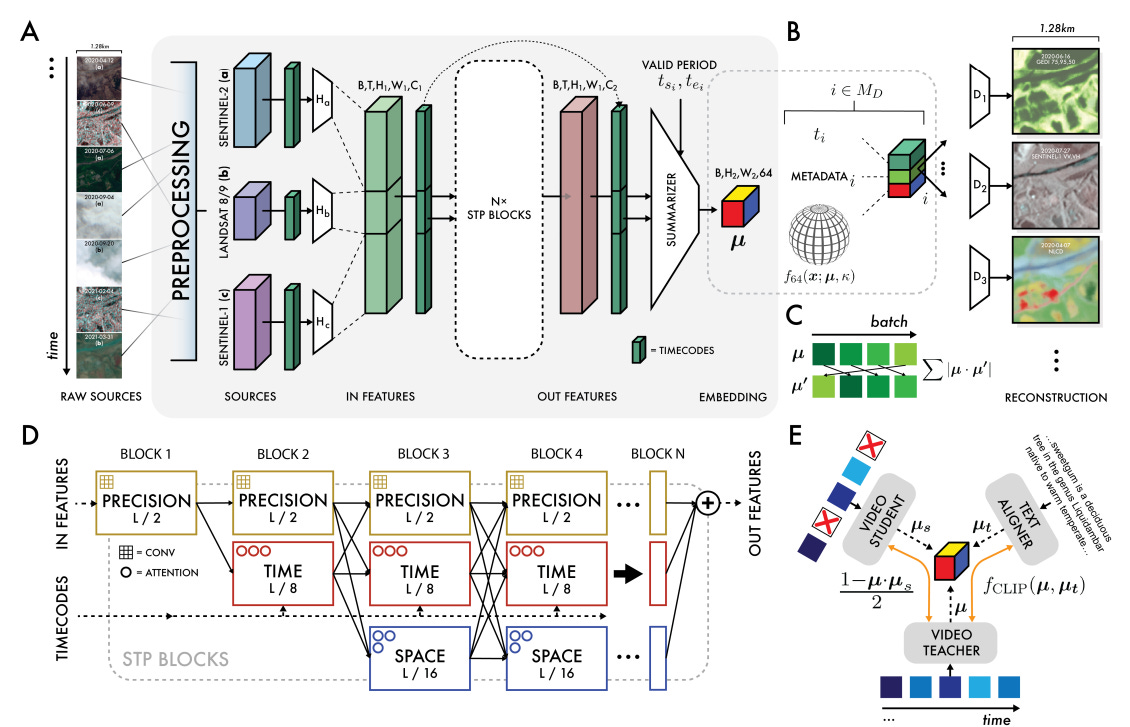
Space Time Precision (STP) Encoder: The input data is processed by a novel encoder architecture termed STP. It consists of 15 blocks, each featuring three simultaneous pathways operating at different scales: a "space" path with ViT-like self-attention (https://arxiv.org/abs/2010.11929), a "time" path with time-axial attention, and a "precision" path with 3x3 convolutions. This design allows the model to efficiently capture both fine-grained local details and long-range spatial and temporal dependencies.
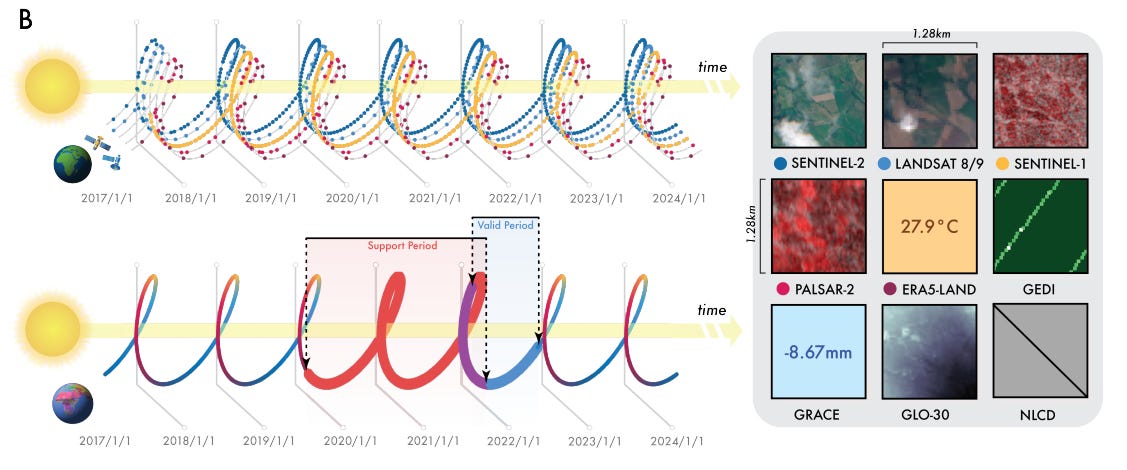
Continuous Time and Conditional Summarization: AEF is the first EO featurization approach to support continuous time. It can take a sparse, irregular time series of observations and produce a smooth, continuous embedding field (Figure 1B). This is accomplished through time-conditional summarization and an implicit decoder that treats time and sensor parameters as continuous variables, enabling reconstruction for any arbitrary timestamp.
Multi-Objective Training: The model is trained using a composite loss function designed to produce robust and generalizable embeddings. The full objective function is:
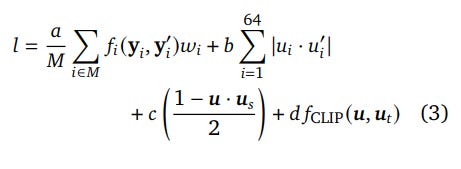
Reconstruction Loss (α=1.0): The primary objective is to reconstruct the original input data from the learned embedding. The loss function
f_iis adaptive, using L1 for continuous data and cross-entropy for categorical data.Batch Uniformity Loss (b=0.05): This term encourages the 64-dimensional embeddings to be uniformly distributed on the unit sphere (S63). By minimizing the absolute value of the dot product between an embedding and its batch-rotated counterpart, it effectively pushes the embedding vectors towards orthogonality. This prevents the model from clustering embeddings in one small part of the unit sphere, ensuring the entire representational space is utilized efficiently.
Consistency Loss (c=0.02): To handle data sparsity, AEF uses a teacher-student framework. The student model is fed perturbed inputs (e.g., with missing time-steps or entire data sources), and this loss forces its embeddings (u_S) to match the teacher's embeddings (u) [in the main text they are also called μ]. This ensures the model learns the underlying surface properties, not the artifacts of the measurement process.
Text Contrastive Loss (d=0.001): Using a standard CLIP loss (https://arxiv.org/abs/2103.00020), this objective aligns the geospatial embeddings (μ or u) with embeddings from a frozen text model (μ_t or u_t) processing geotagged descriptions, enriching the features with semantic meaning.
The model with ~480M was trained for 56 hours on 512 TPU v4 devices, demonstrating the significant computational investment required for such a foundational model. The authors trained ∼1B and ∼480M parameter variants of AEF, and ultimately proceeded with the smaller variant for improved inference efficiency.
Experimental Validation: A New State-of-the-Art
The authors conducted an exhaustive evaluation across a suite of 15 challenging mapping tasks, from land cover classification to biophysical variable estimation. The results are compelling.
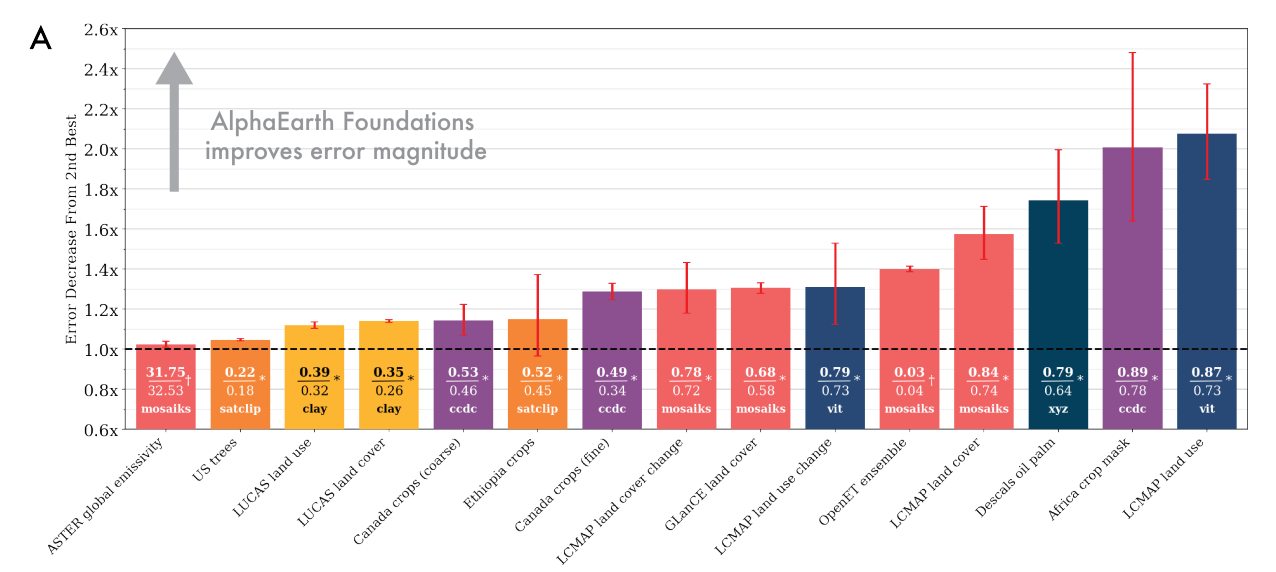
AEF consistently outperforms all baselines—including designed features like CCDC and learned models like SatCLIP, Prithvi, and Clay—without any task-specific re-training. As shown in Figure 1A, AEF achieves an average error magnitude reduction of ~23.9% (~1.4x) compared to the next-best method across all tasks.
Key findings include:
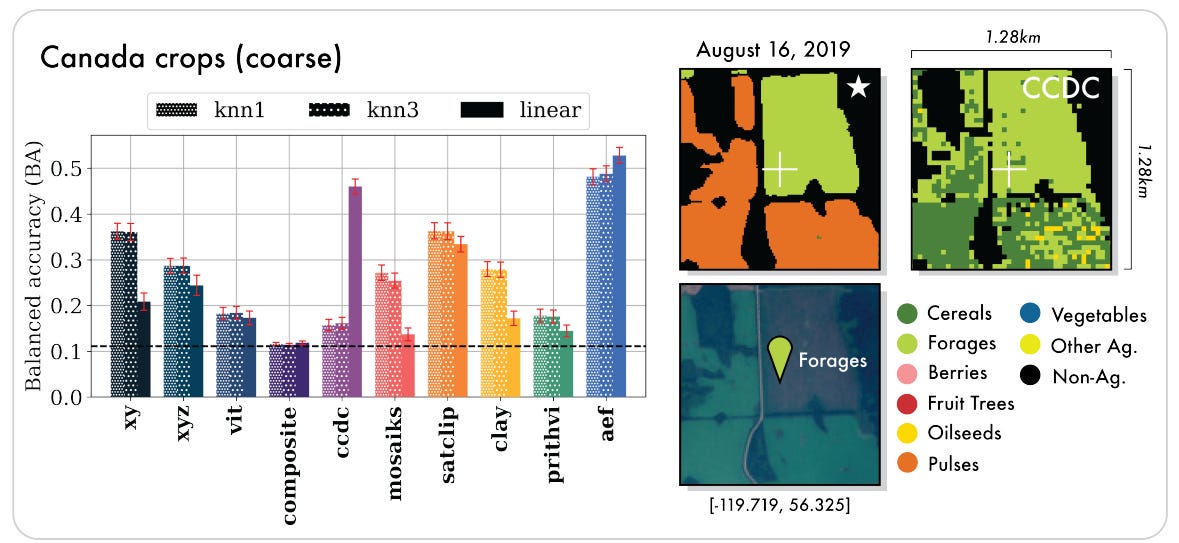
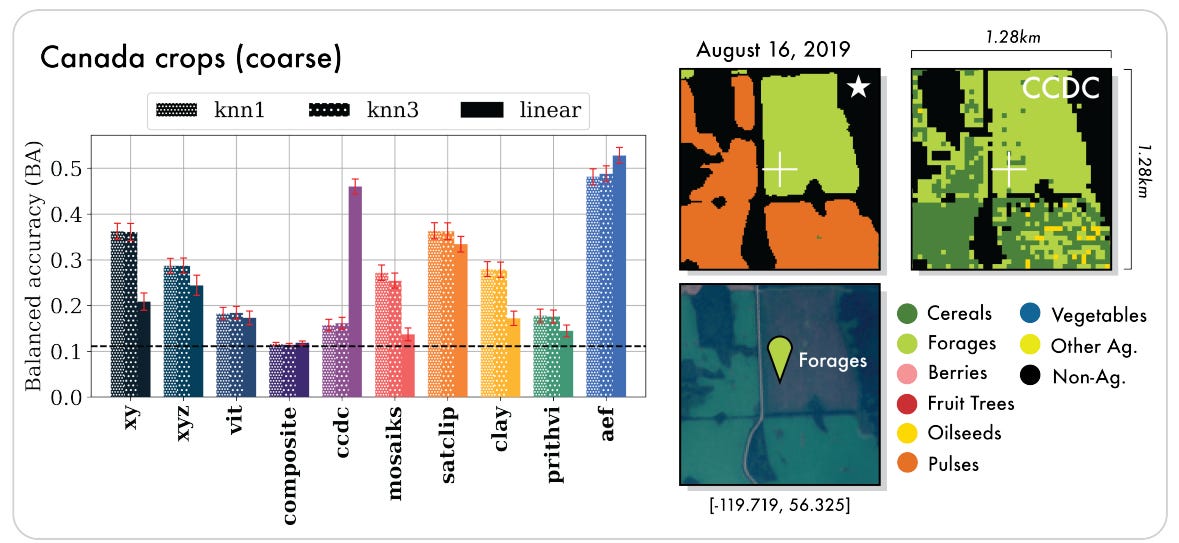
Thematic Mapping: AEF shows strong performance in land cover, land use, and crop mapping tasks, demonstrating its ability to capture complex semantics.
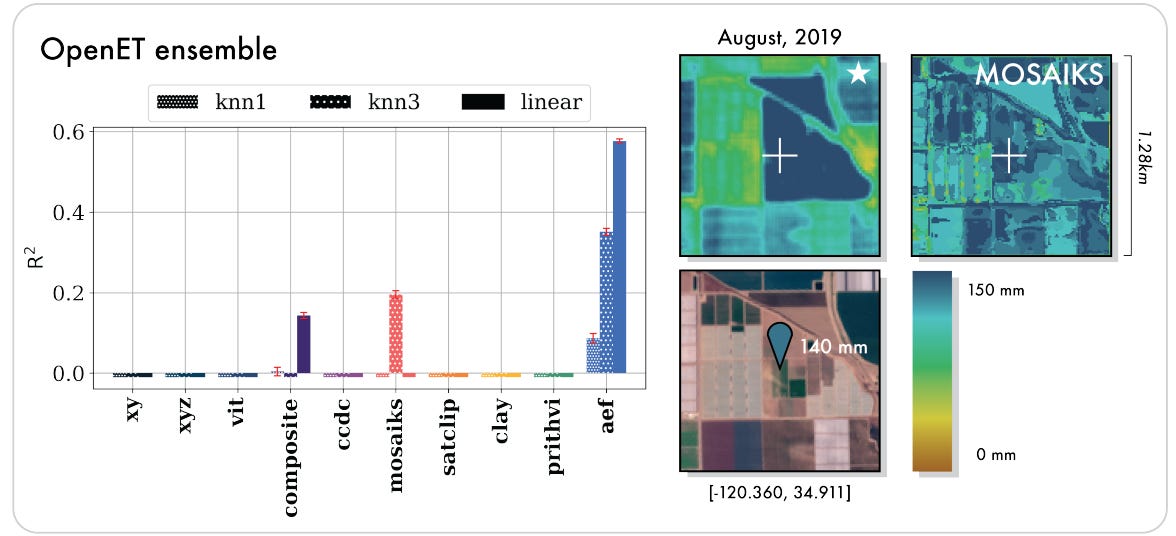
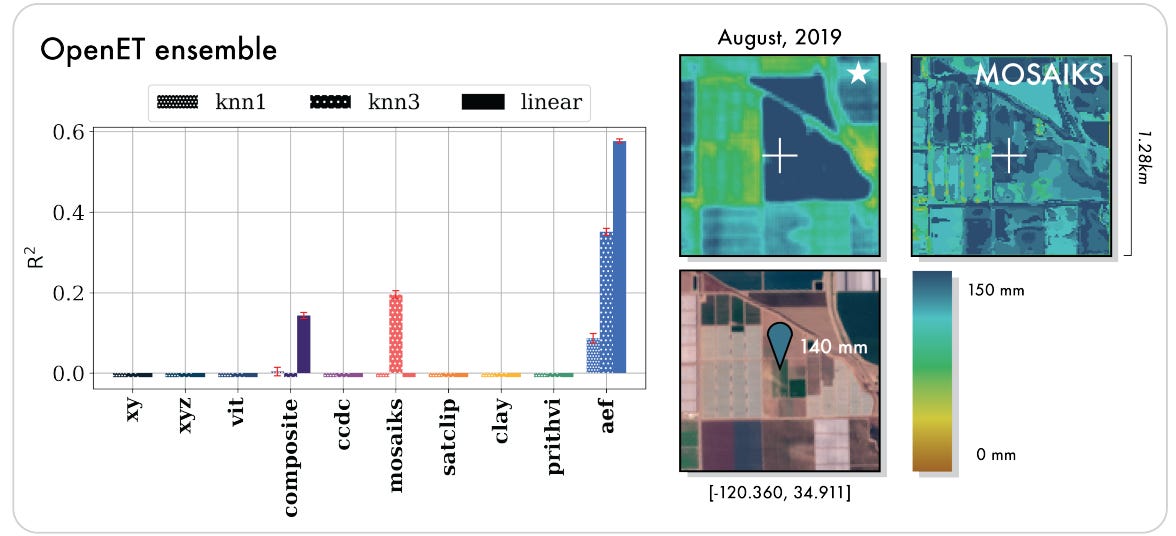
Biophysical Variables: The model shows a particularly significant leap in estimating evapotranspiration. While most baselines failed (achieving a negative R², meaning their predictions were worse than simply guessing the average), AEF achieved an R² of 0.58 (explaining 58% of the variance in the data), demonstrating its ability to model complex physical processes (Figure 3).
Data Scarcity: AEF maintains its performance advantage even in extreme low-shot settings (1 and 10 samples), a critical capability for a field where labeled data is a major bottleneck.
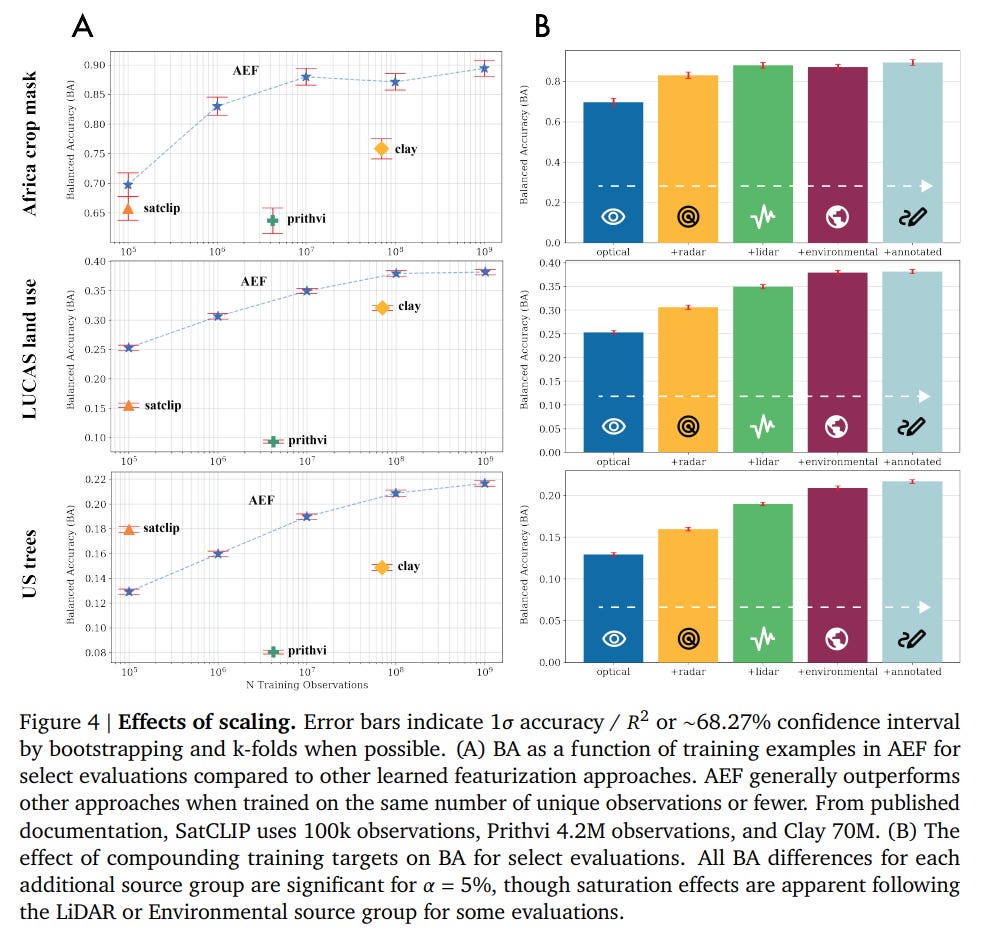
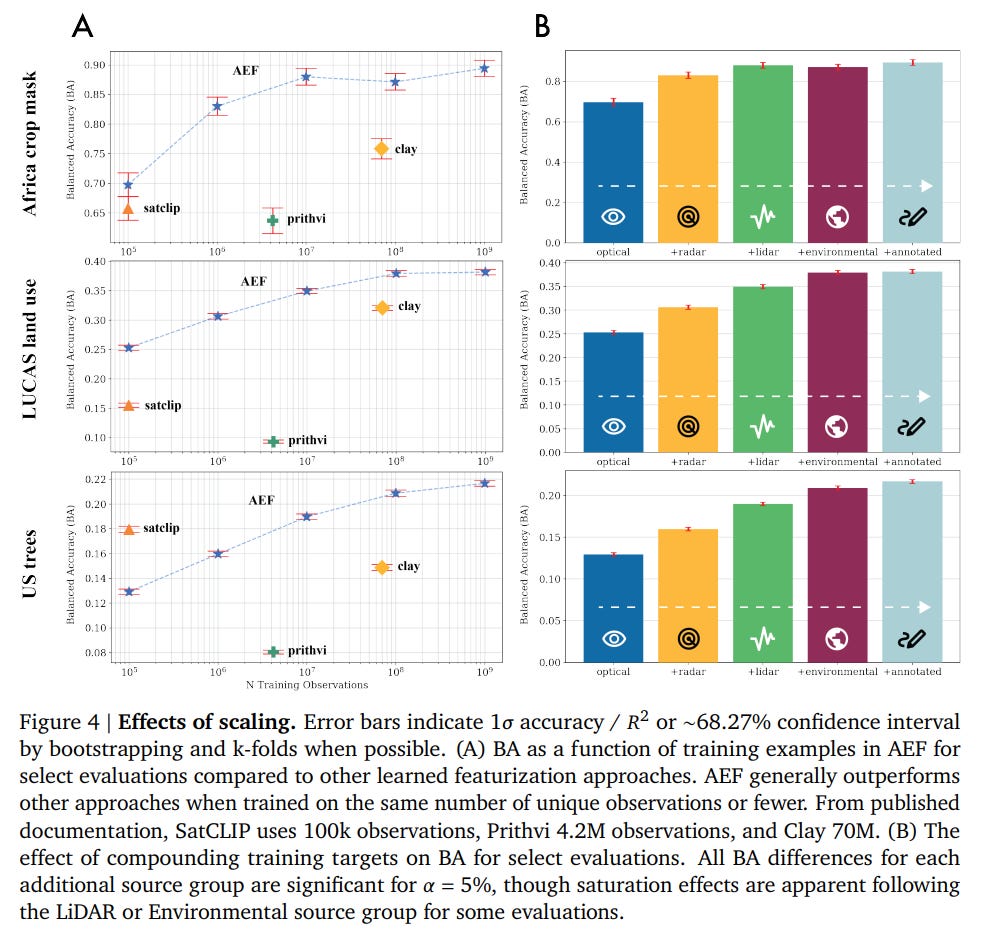
Scaling: The model's performance consistently improves with more training data and a greater diversity of source modalities, validating the foundational approach (Figure 4).
Impact and Broader Context
AlphaEarth Foundations is a flagship project within the broader "Google Earth AI" initiative, which aims to leverage AI for global challenges. The significance of this work extends beyond academic benchmarks. According to companion blog posts, the annual AEF embeddings are being released as a public dataset in Google Earth Engine and are already being used by organizations like the UN's Food and Agriculture Organization and MapBiomas for practical applications in conservation and agricultural monitoring.
By creating a compact, efficient (16x less storage than the next-best system), and analysis-ready feature space, AEF democratizes access to advanced geospatial intelligence. It allows scientists and practitioners to build powerful custom maps and monitoring systems without needing petabytes of raw data or expertise in deep learning, thereby accelerating progress on critical environmental and societal issues.
Limitations and Future Directions
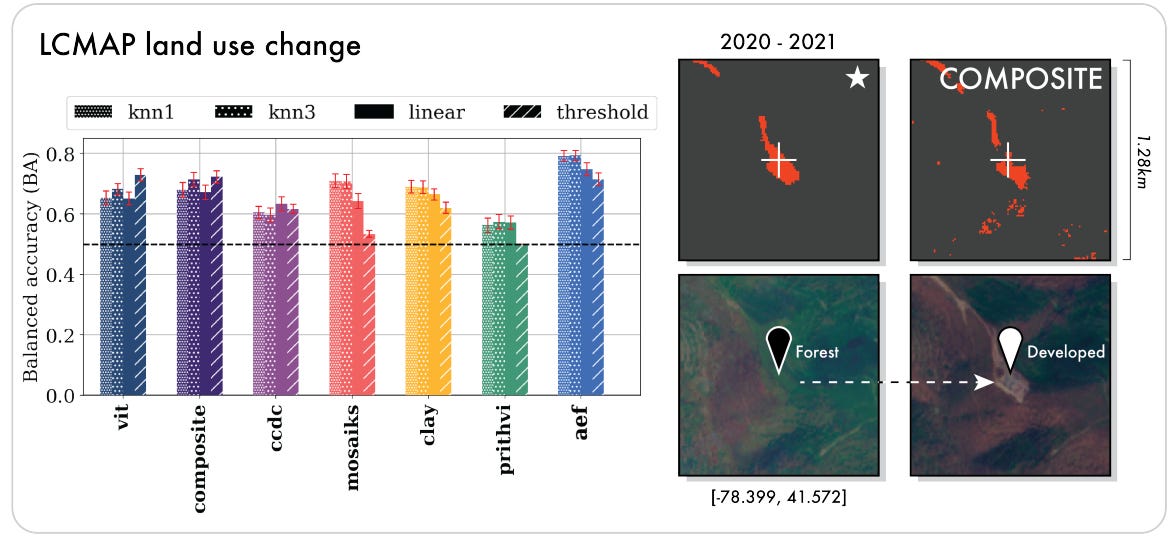
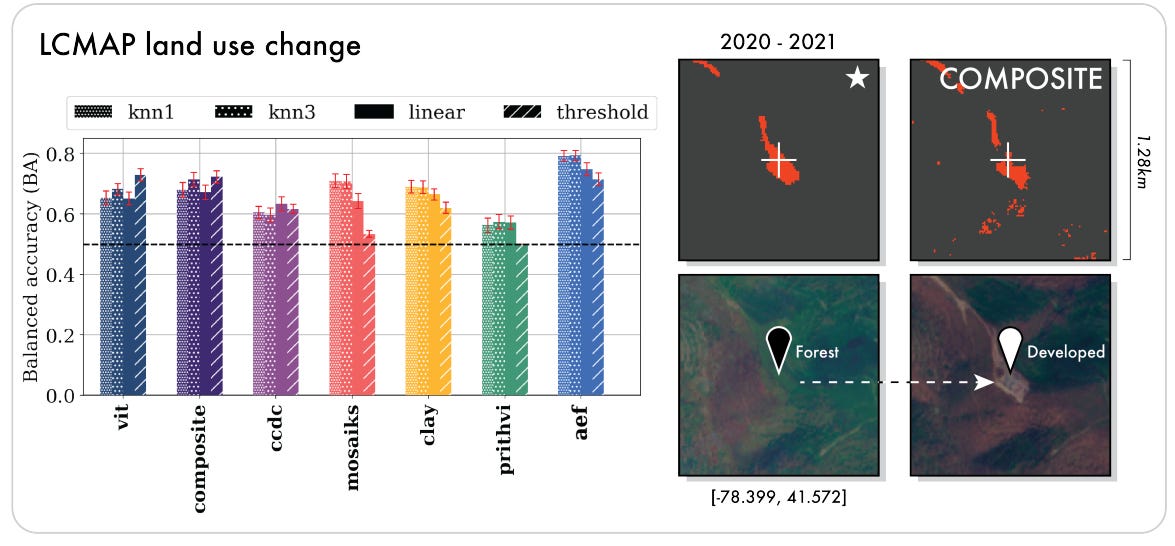
The paper is transparent about its limitations. While AEF establishes a new state-of-the-art, the performance gains are less pronounced in extreme one-shot and ten-shot scenarios, indicating this remains an open research frontier. The generated embedding fields also contain some visible "tile artifacts" resulting from irregularities in the input data, which the authors suggest could be addressed with a more aggressive consistency objective in future work. Finally, for the specific task of unsupervised land use change detection, AEF's performance was slightly exceeded by a simpler ViT baseline (71.4% vs. 72.9% BA). This is an important finding, suggesting that while AEF provides a powerful general foundation, its full complexity may not be perfectly optimized for every possible unsupervised task, and that direct supervision remains key to unlocking its best performance.
Conclusion
"AlphaEarth Foundations" presents a landmark achievement in the application of AI to Earth observation. By successfully creating a universal, task-agnostic feature space, the model provides a powerful solution to the long-standing challenges of data volume and label scarcity. It not only sets a new performance benchmark across a wide array of geospatial tasks but also delivers a practical, efficient, and scalable foundation for the next generation of planetary-scale monitoring systems. This work represents a significant step toward a future where AI helps us understand and protect our changing planet with unprecedented detail and accuracy.
Did you use BigQuery for this paper? From what I understand BQ's ability to handle very large datasets can come in very handy here. Would love to hear your thoughts