
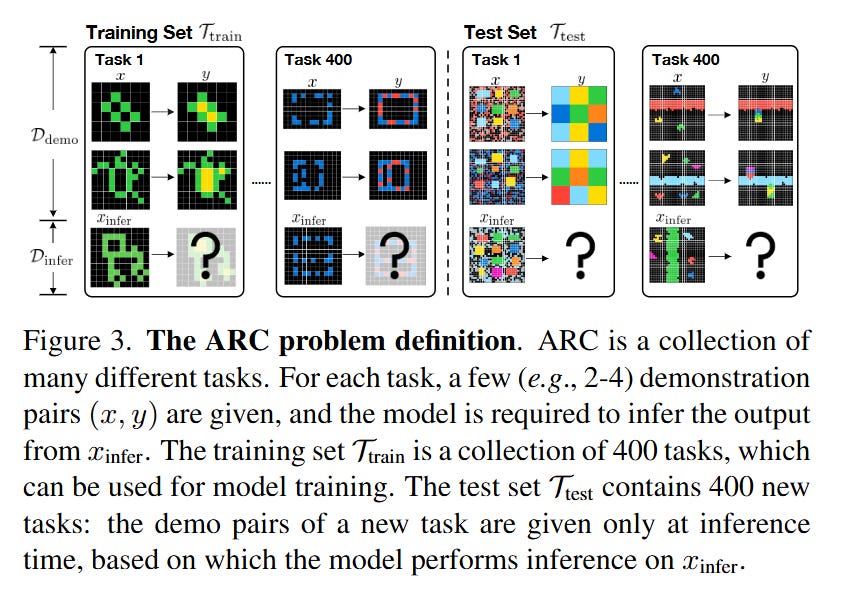
ARC Is a Vision Problem!
Authors: Keya Hu, Ali Cy, Linlu Qiu, Xiaoman Delores Ding, Runqian Wang, Yeyin Eva Zhu, Jacob Andreas, Kaiming He
Paper: https://arxiv.org/abs/2511.14761
Code: https://github.com/lillian039/VARC
TL;DR
WHAT was done? The authors propose VARC (Vision ARC), a framework that reframes the Abstraction and Reasoning Corpus (ARC) not as a language or program synthesis task, but as a direct image-to-image translation problem. By mapping ARC grids onto a high-resolution “canvas” and utilizing standard vision architectures (ViT and U-Net) combined with aggressive Test-Time Training (TTT), they achieve state-of-the-art results among models trained from scratch.
WHY it matters? This approach challenges the prevailing dominance of Large Language Models (LLMs) in abstract reasoning. With only 18 million parameters, VARC achieves 54.5% accuracy (60.4% with ensembling) on ARC-1, rivaling average human performance and outperforming massive LLMs like GPT-5 that lack visual grounding. It demonstrates that correct inductive biases—specifically 2D locality and scale invariance—can be far more efficient than scale.

Details
The Modality Mismatch in Abstract Reasoning
For the past few years, the ARC benchmark has served as a stubborn fortress against the progress of AI, specifically highlighting the gaps in Large Language Models.
The dominant strategy has been to treat ARC as a sequence modeling problem: flattening 2D grids into 1D token sequences or generating Python programs to solve the task. However, this introduces a fundamental modality mismatch. ARC tasks—involving symmetry, gravity, and object persistence—are inherently visual. Tokenization destroys the native 2D topology of the data, forcing models to relearn spatial adjacency from scratch. The authors of VARC posit that the bottleneck isn’t a lack of reasoning capability, but an incorrect representation. By shifting the paradigm from “reading” the grid to “seeing” it, they leverage decades of computer vision research to capture spatial priors that text-based models struggle to emulate.
VARC First Principles: The Canvas Abstraction
The theoretical substrate of VARC is the rejection of the discrete token in favor of the “Canvas.” In standard approaches, an ARC grid of size H×W is a matrix of integers. VARC redefines the input space by projecting these grids onto a fixed, larger pixel space—the Canvas (e.g., 64×64). This is not merely resizing; it is an embedding strategy that allows for continuous geometric transformations. The core assumption is that the underlying rules of ARC are invariant to translation and scale.
Mathematically, the input x is no longer a sequence of tokens t_1, ... t_n, but a tensor x∈RC×H_canvas×W_canvas. The discrete colors of ARC are mapped to learnable embeddings, but crucially, they are processed through mechanisms that respect Euclidean distance. By decoupling the grid size from the model’s input size via this canvas, the authors enable the use of visual priors—specifically scale invariance and translation invariance—which are enforced via data augmentation rather than architectural hard-coding alone.
From Grid to Canvas to Prediction
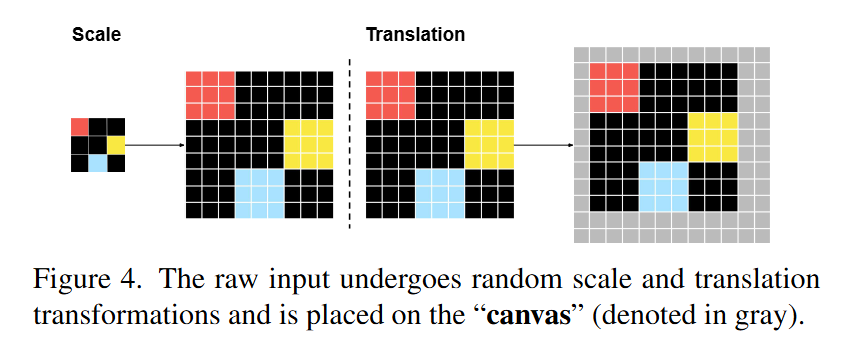
To understand the mechanics, consider a specific ARC task involving “gravity,” where colored pixels must “fall” to the bottom of the grid. In the VARC pipeline, the raw input grid (e.g., 10×10) is first subjected to a Scale Augmentation. Each logical pixel is replicated s×s times (analogous to nearest-neighbor upsampling) to occupy a larger footprint. This scaled grid is then placed randomly on the fixed 64×64 black background canvas, introducing Translation Augmentation as shown in (Figure 4).
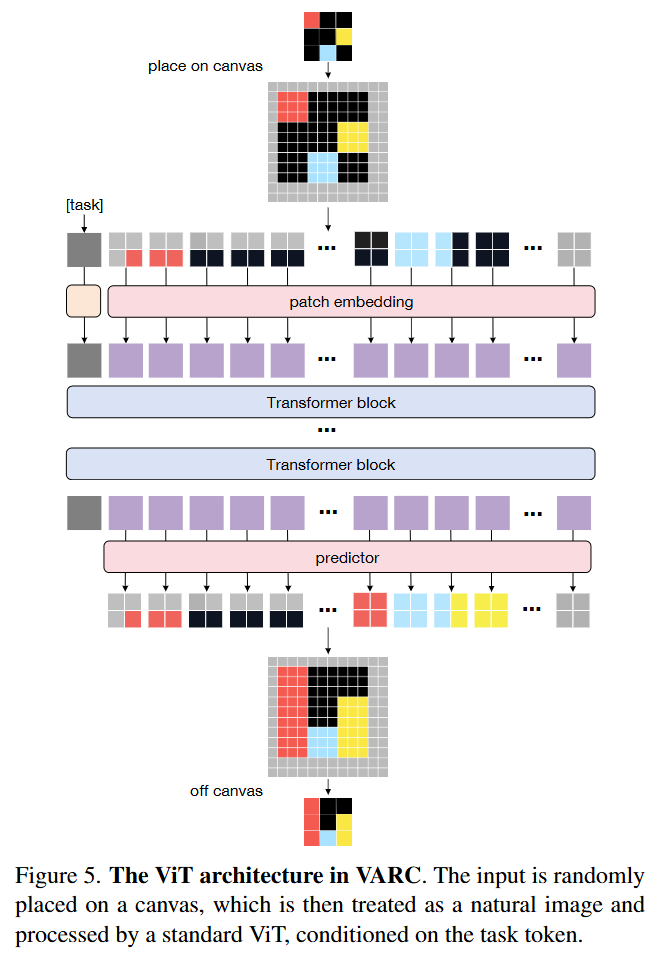
The architecture handling this canvas is a standard Vision Transformer (ViT) or U-Net. The canvas is divided into patches (e.g., 2×2). Unlike standard ViTs where a patch might be a mix of RGB values, here a patch represents a configuration of discrete ARC colors. The model f_θ(x_i ∣ T) processes this image conditioned on a learnable task embedding T. The process flows as a semantic segmentation task: the network predicts a categorical distribution over the 10 ARC colors for every pixel on the canvas. At inference, as visualized in (Figure 5), the model outputs a probability map which is then discretized back into the grid format. This visual formulation allows the model to “see” the gravity rule as a vertical translation of pixel patches, rather than a complex index manipulation in a sequence.
Test-Time Training and Optimization
A critical engineering component driving VARC’s performance is Test-Time Training (TTT). Since ARC is a few-shot problem (providing only 2-4 demonstration pairs per task), a static model often fails to generalize to the specific transformation rule of a new test task. The authors adopt a bi-level optimization strategy. First, the model is trained offline on the entire training set—augmented with RE-ARC synthetic data—to learn general visual priors.

Then, during inference for a specific unseen task T_test, the model undergoes rapid fine-tuning. The few demonstration pairs
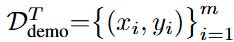
are augmented into a mini-dataset using geometric transformations (rotations, flips, color permutations). The model weights are updated to minimize the per-pixel cross-entropy loss on these augmented demos:
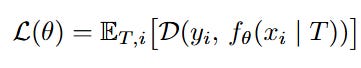
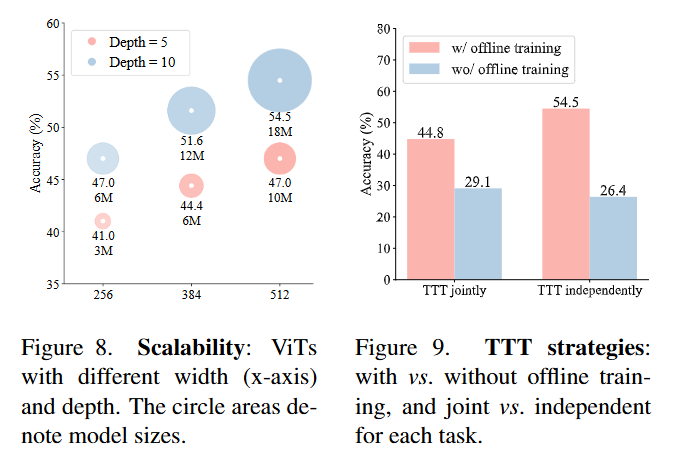
This essentially forces the model to “overfit” to the task-specific rule before making a prediction on the test input. As shown in (Figure 9), performing this TTT independently for each task yields significantly better results than joint training, preventing interference between distinct reasoning rules.
Analysis: The Source of Performance
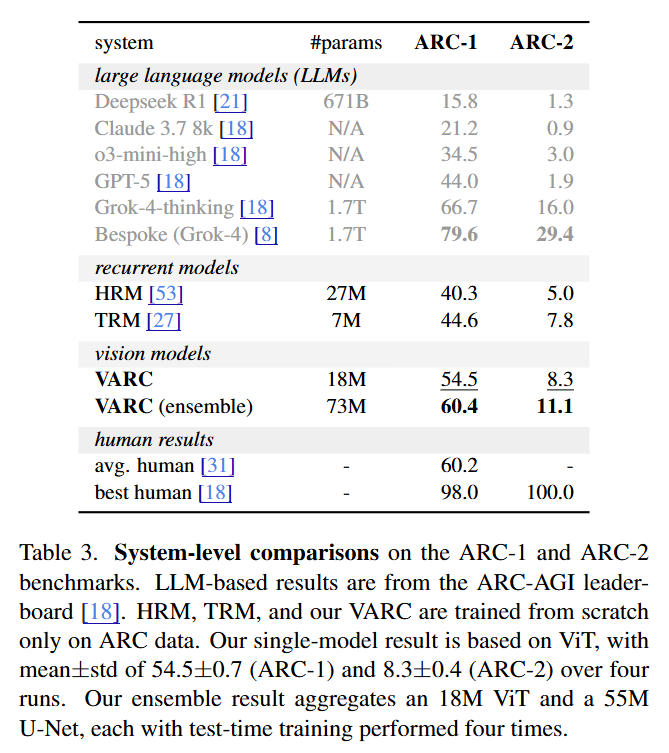
The validation results are strikingly high for a model of this size. VARC achieves 54.5% accuracy on ARC-1 with a single ViT-18M model, and 60.4% when ensembled with a U-Net. This substantially outperforms purely recurrent neural models like HRM (40.3%, review here) and TRM (44.6%, review here), which are also trained from scratch.
The ablation studies in (Figure 7) provide the “why.”

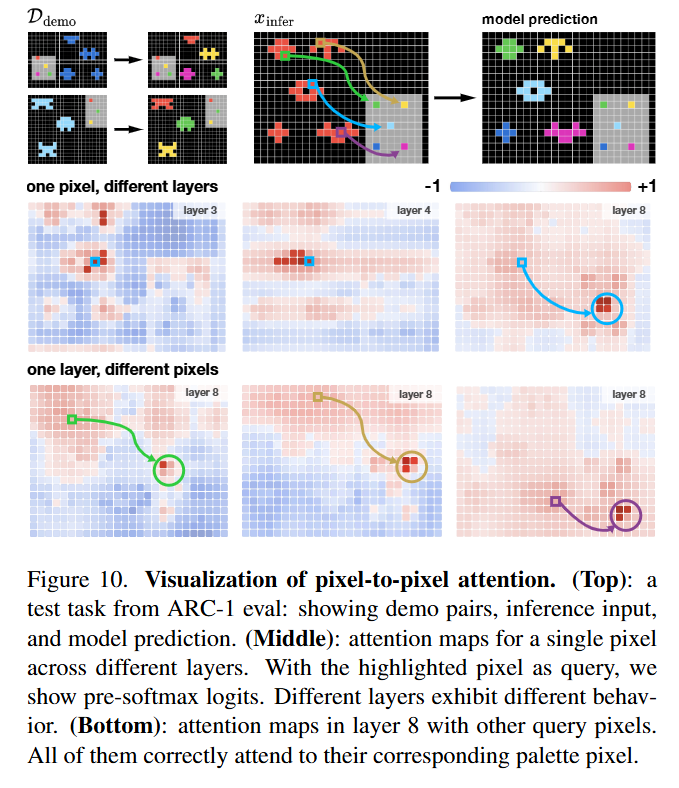
The shift from a naive baseline to the “Canvas” representation (enabling scale and translation augmentation) contributes a massive 11.5% gain in accuracy. This confirms that the difficulty in ARC is often not the logical reasoning itself, but the visual recognition of the objects being manipulated. Furthermore, the visualization of attention maps in (Figure 10) reveals that the model learns to attend to relevant source pixels—effectively learning a “copy” operation purely through attention mechanisms without explicit pointer networks.
Limitations
While VARC closes the gap to human performance, it is not without weaknesses. The reliance on TTT significantly increases the computational cost of inference (roughly 70 seconds per task on a GPU), as the model must be trained ad-hoc for every new puzzle. Additionally, while the vision paradigm excels at spatial transformations, it is unclear how well it scales to tasks requiring abstract counting or complex logical conditionals that have no direct visual analogue. The paper notes that while visual priors solve many tasks, the model effectively treats reasoning as “image-to-image translation,” which may hit a ceiling on tasks that are visually abstract but logically deep.
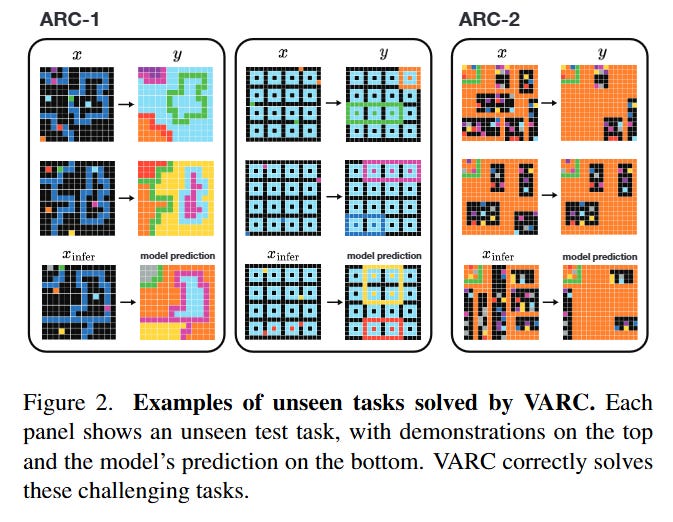
Impact & Conclusion
“ARC Is a Vision Problem!” is a strategic pivot in the field of abstract reasoning. It effectively argues that we have been over-complicating ARC by treating it as a language or code problem, when many of its core challenges are rooted in basic visual perception (objectness, symmetry, containment). By achieving 60% accuracy with a model orders of magnitude smaller than GPT-5 or DeepSeek-R1 (Table 3), the authors demonstrate that inductive bias is an efficiency multiplier. For researchers at the intersection of vision and reasoning, this paper suggests that the path to AGI might not just be “more tokens,” but better eyes.