
Architectural Innovation with Diffusion Model Grafting
A Powerful New Tool
Exploring Diffusion Transformer Designs via Grafting
Authors: Keshigeyan Chandrasegaran, Michael Poli, Daniel Y. Fu, Dongjun Kim, Lea M. Hadzic, Manling Li, Agrim Gupta, Stefano Massaroli, Azalia Mirhoseini, Juan Carlos Niebles, Stefano Ermon, Li Fei-Fei
Paper: https://arxiv.org/abs/2506.05340
Site: https://grafting.stanford.edu/
TL;DR
WHAT was done? The paper introduces "grafting," a novel two-stage methodology for editing pretrained Diffusion Transformers (DiTs) to explore new architectures with minimal compute. The process involves: 1) Activation Distillation, where a new operator (e.g., a gated convolution) is initialized by training it to mimic the output activations of an existing operator (e.g., MHA) from the pretrained model. 2) Lightweight Finetuning, where the entire modified model is finetuned on a small fraction of the original data (e.g., 10%) to mitigate cumulative error and recover performance. The authors demonstrate this by replacing MHA and MLP blocks with various efficient alternatives and even by fundamentally restructuring a model's topology, converting sequential depth into parallel width.
WHY it matters? This work presents a paradigm shift for architectural research in the era of foundation models. By circumventing the prohibitive cost of training models from scratch for every design change, grafting dramatically lowers the barrier to architectural exploration, making it more accessible and agile. The method is shown to be highly effective, producing efficient hybrid models for high-resolution text-to-image generation with a 1.43x speedup at a minimal quality trade-off. More strikingly, it enables deep architectural restructuring, such as converting a 28-layer DiT into a 14-layer parallel version that outperforms other models of comparable depth. This opens the door to post-training, hardware-aware optimization and a more dynamic, iterative approach to AI model design.

Details
The High Cost of Architectural Curiosity
In the age of large-scale foundation models, architectural innovation is a high-stakes game. While new architectures promise greater efficiency and capability, the immense computational cost of training them from scratch creates a formidable barrier. This bottleneck effectively slows down the pace of research and concentrates it in the hands of a few.
A new paper from a team of researchers asks a powerful question: what if we could build on what we already have? The work introduces grafting, a compelling methodology that treats powerful, pretrained models not as immutable artifacts, but as malleable scaffolds for creating and testing new designs.
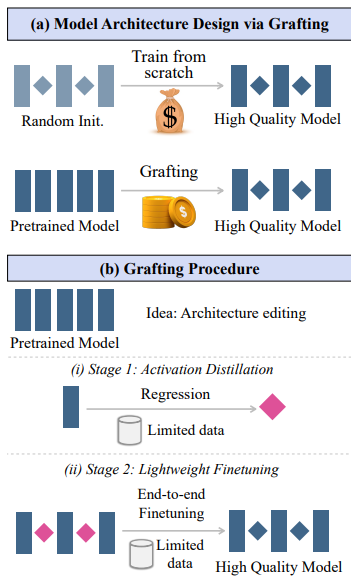
Methodology: The Art and Science of Model Grafting
Drawing an analogy from software engineering, grafting reuses and modifies existing models rather than starting from scratch. The proposed method is a clean, two-stage process for integrating new components into a pretrained Diffusion Transformer (DiT).
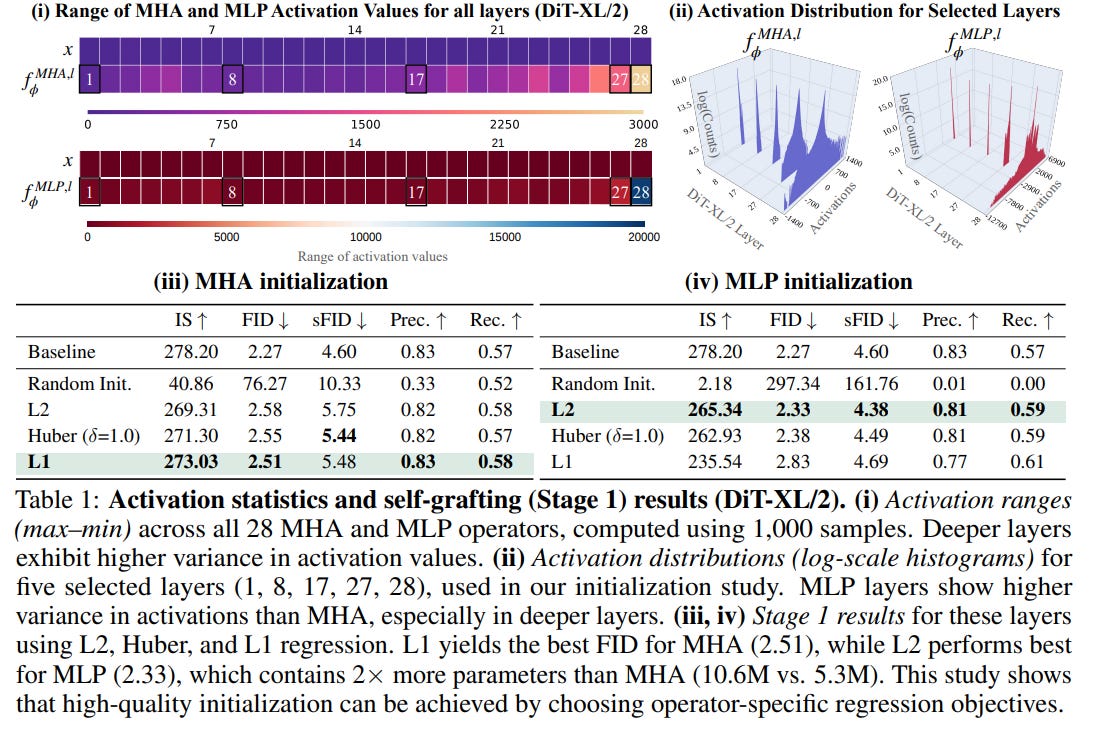
Stage 1: Activation Distillation. To replace a component, its substitute must first be initialized to be functionally similar. Grafting treats this as a regression problem: a new operator is trained to match the output activations of the original. This clever distillation step requires very little data—as few as 8,000 samples—to achieve a strong initialization. This isn't a one-size-fits-all process; the authors found that the best initialization strategy is operator-specific, with L1 regression being optimal for MHA blocks and L2 for MLPs, a key insight derived from their analysis of activation distributions in Table 1.
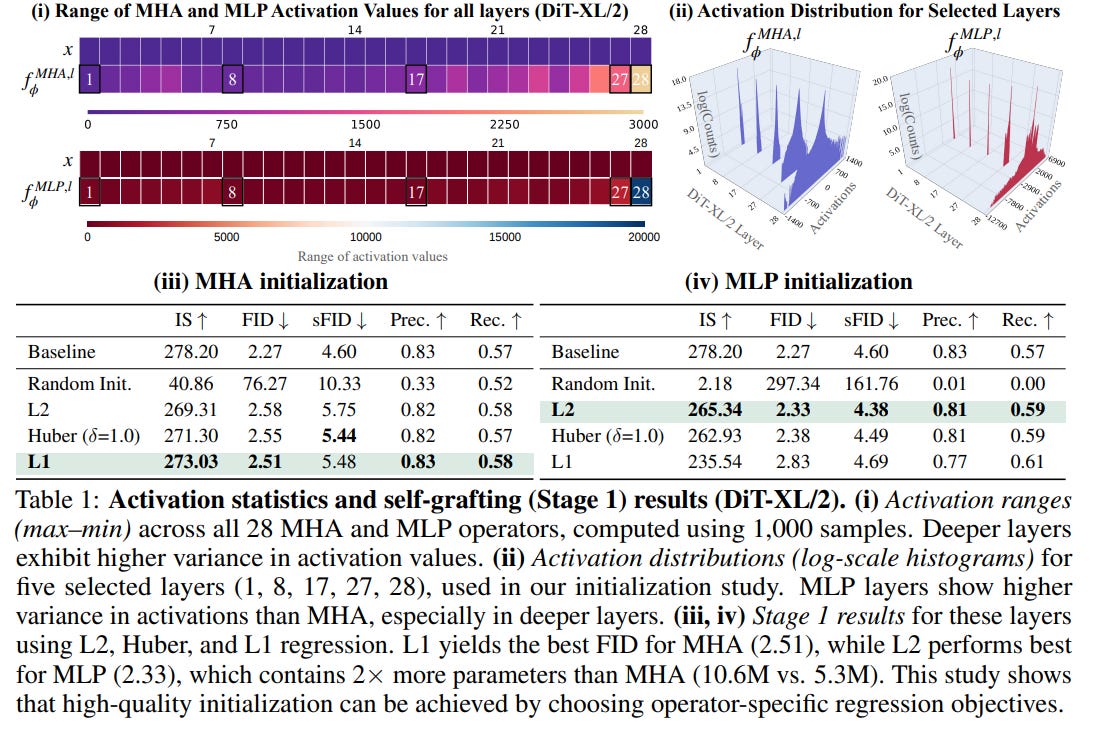
Stage 2: Lightweight Finetuning. Even with good initialization, swapping multiple components can cause errors to accumulate. The second stage addresses this by finetuning the entire grafted model on the standard diffusion loss, but with only a small fraction (e.g., 10%) of the original training data. This "systems integration" phase harmonizes the new components and recovers performance with minimal compute.
This methodology is guided by empirical analysis. For instance, the authors' analysis of attention patterns in a DiT-XL/2 revealed that many layers are surprisingly local. Their analysis showed that in 15 of the 28 attention layers, over 50% of the attention mass is concentrated within a local window of 32 tokens, as shown in Figure 2.
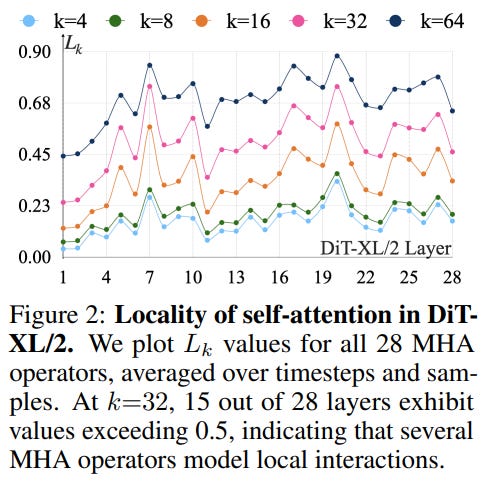
This provided a strong rationale for experimenting with local operators like gated convolutions and sliding window attention as replacements for global multi-head attention (MHA).
From Theory to Practice: A Trio of Compelling Results
The authors systematically validate grafting in a thoughtful progression of experiments, moving from a controlled testbed to a real-world application and finally to a radical restructuring.
1. Proof of Concept: A Testbed for Hybrid Architectures First, using a DiT-XL/2 on ImageNet, they created a suite of hybrid architectures by grafting in various replacements for MHA and MLP blocks—including novel gated convolutions (Hyena-X/Y), the structured state-space model Mamba-2, and MLPs with different widths. The results are impressive: many hybrids achieve FID scores remarkably close to the baseline (e.g., 2.38–2.64 vs. 2.27), all while using less than 2% of the original pretraining compute, as detailed in Table 4.
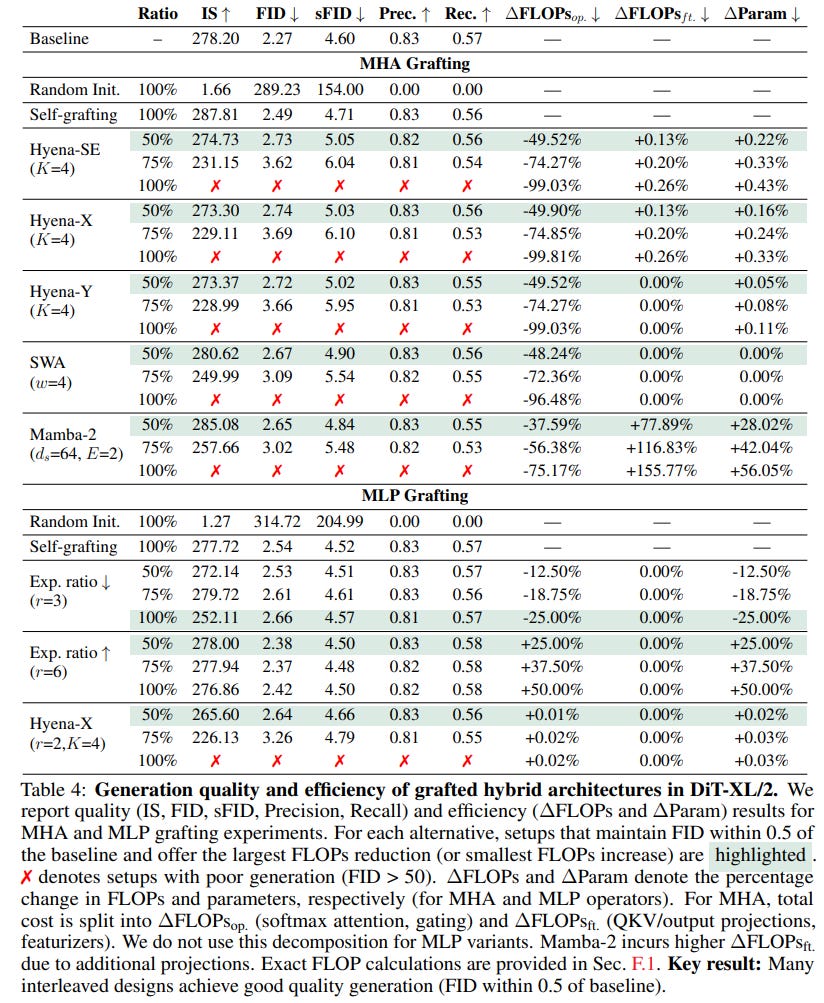
The high-quality images generated from these diverse models, seen in Figure 1c, validate the approach.

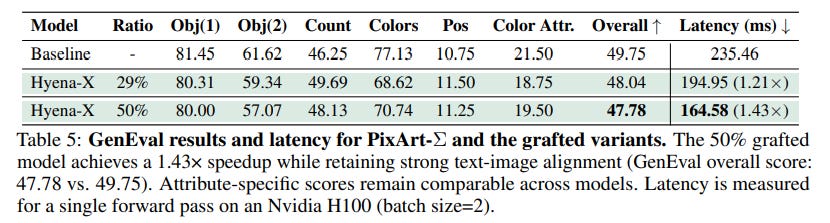
2. Real-World Value: Speeding Up Text-to-Image Generation Next, to prove its utility, the method was applied to the high-resolution text-to-image model, PixArt-Σ. By replacing MHA operators with the efficient Hyena-X operator (using LoRA for memory-efficient finetuning), the grafted model achieved a 1.43x inference speedup with less than a 2% drop in the GenEval score, a significant result detailed in Table 5. This demonstrates that grafting delivers tangible performance gains on complex, multimodal tasks where latency is critical.
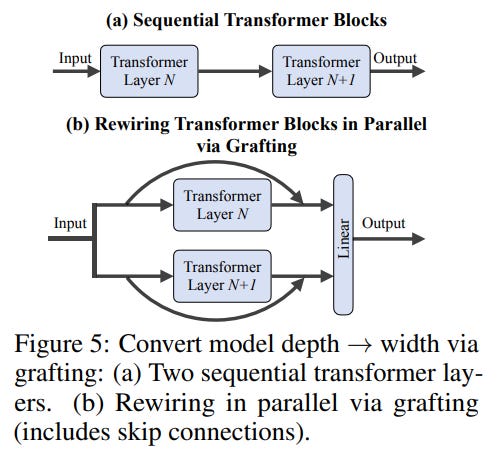
3. Pushing the Boundaries: Trading Depth for Width Perhaps the most forward-looking result is the demonstration of deep architectural restructuring. The authors took a 28-layer DiT-XL/2 and, via grafting, converted every pair of sequential transformer blocks into parallel blocks, as illustrated in Figure 5.
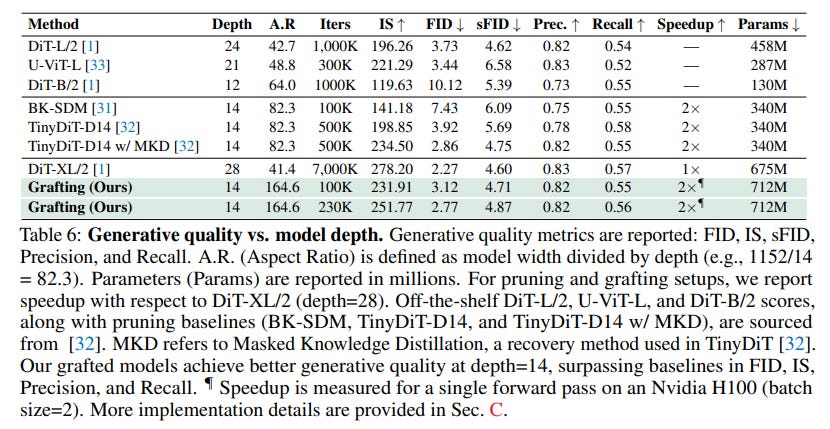
This halved the model's depth to 14 layers, trading sequential computation for parallelism favored by modern GPUs. The resulting model not only worked but achieved an FID of 2.77, outperforming deeper models trained from scratch like DiT-L/2 (24 layers) and U-ViT-L (21 layers), as well as pruning baselines like TinyDiT-D14, as shown in Table 6. This finding suggests grafting can be used to fundamentally rewire pretrained models for hardware-specific optimization.
Limitations and the Path Forward
The paper is commendably transparent about limitations. The experiments are primarily on DiTs, so generalizability to other architectures like autoregressive models is an open question. The reliance on synthetic data for the PixArt-Σ experiment also highlights a challenge: data quality is crucial, as artifacts can propagate to the final model. Finally, grafting requires a high-quality pretrained model to start with, and it remains an open question whether the successful grafted architectures would perform as well if trained from scratch.
However, these points illuminate clear paths for future research. Grafting provides not just a method but a new research paradigm, encouraging a move beyond the monolithic "train-from-scratch" mindset toward a more dynamic, iterative approach to architectural design.
Conclusion
"Exploring Diffusion Transformer Designs via Grafting" is a significant and timely contribution. It presents a well-conceived, rigorously validated, and highly practical methodology for architectural exploration that directly addresses a key bottleneck in modern AI. By demonstrating that pretrained models can be efficiently and effectively edited—from operator swaps to fundamental restructuring—the authors have given the community a powerful new tool. This paper is a must-read for anyone involved in designing and optimizing large-scale AI models.