
Attention Residuals
Authors: Guangyu Chen, Yu Zhang, Jianlin Su, Weixin Xu, Siyuan Pan, Yaoyu Wang, Yucheng Wang, Guanduo Chen, Bohong Yin, Yutian Chen, Junjie Yan, Ming Wei, Y. Zhang, Fanqing Meng, Chao Hong, Xiaotong Xie, Shaowei Liu, Enzhe Lu, Yunpeng Tai, Yanru Chen, Xin Men, Haiqing Guo, Y. Charles, Haoyu Lu, Lin Sui, Jinguo Zhu, Zaida Zhou, Weiran He, Weixiao Huang, Xinran Xu, Yuzhi Wang, Guokun Lai, Yulun Du, Yuxin Wu, Zhilin Yang, Xinyu Zhou
Paper: https://arxiv.org/abs/2603.15031
Code: https://github.com/MoonshotAI/Attention-Residuals
Model: N/A
Affiliation: Kimi Team / Moonshot AI
TL;DR
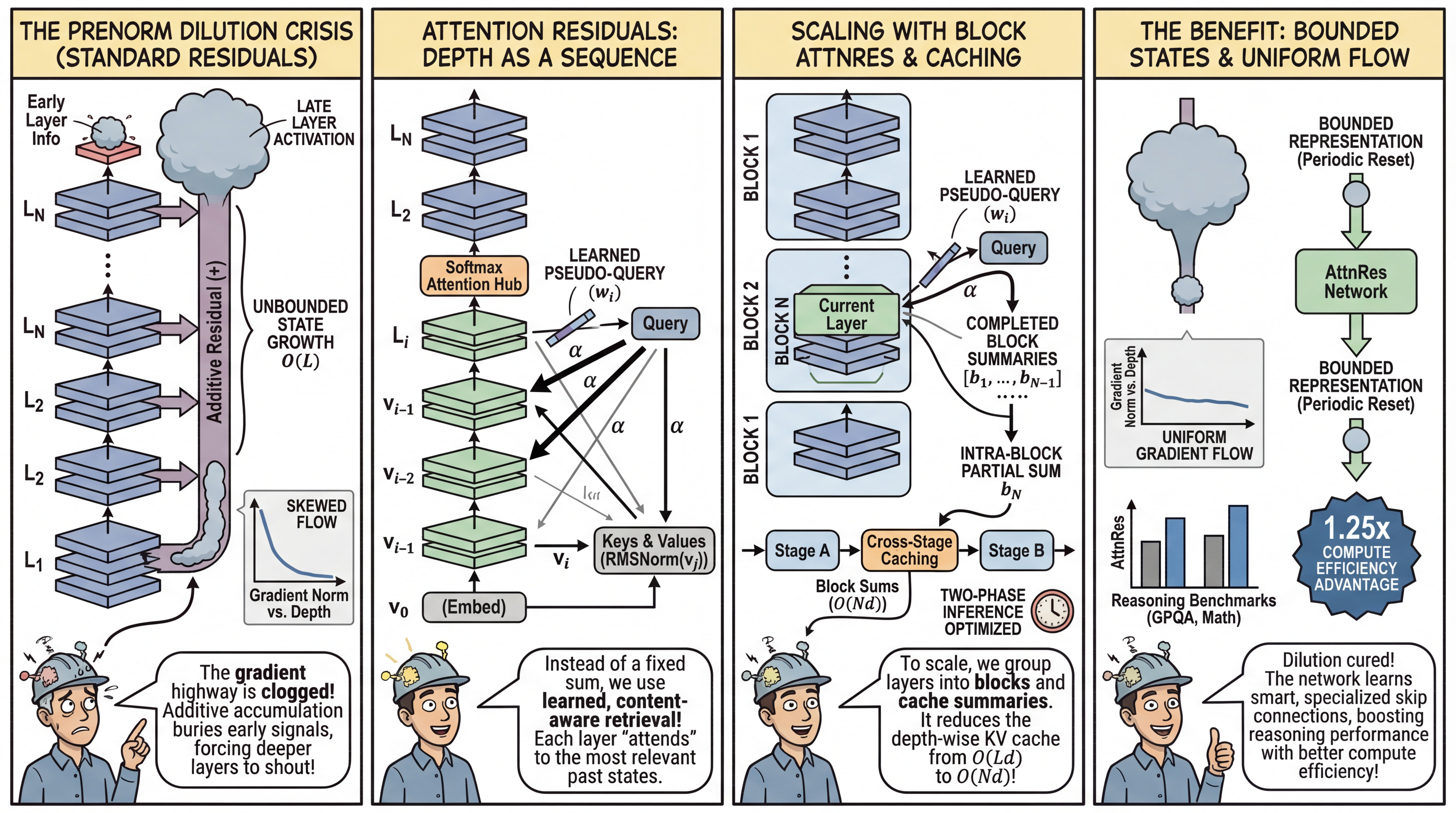
WHAT was done? The authors replace the ubiquitous additive residual connection with “Attention Residuals”, a mechanism that uses learned, depth-wise softmax attention to aggregate representations from all preceding layers. To scale this for massive models, they introduce a block-wise variant with custom pipeline parallelism caching and two-phase inference optimizations.
WHY it matters? Standard residuals uniformly accumulate outputs, leading to unbounded hidden-state growth and the progressive dilution of early-layer information. By migrating to a content-aware retrieval mechanism over network depth, this architecture tightly bounds representation magnitudes, uniformizes gradient flow, and significantly boosts reasoning performance on compute-equivalent models, yielding a 1.25x compute efficiency advantage.
Details
The PreNorm Dilution Crisis
Standard residual connections form the absolute bedrock of modern Transformer architectures. The fundamental update rule, hl=hl−1+fl−1(hl−1), acts as a gradient highway that enables stable training by bypassing nonlinear transformations. However, this mathematically simple addition enforces a rigid structural constraint: uniform depth-wise aggregation. Every previous layer is granted an identical unit weight. Combined with the standard PreNorm architecture, this unweighted accumulation causes the hidden-state magnitude to grow at O(L) with network depth. This creates a severe representation bottleneck known as PreNorm dilution. Because the accumulated state vector grows steadily larger, early-layer information becomes deeply buried. For deeper layers to meaningfully influence the downstream output, they are compelled to produce increasingly larger activations to overcome the inflated residual stream. This phenomenon stifles effective depth and destabilizes training dynamics, posing a structural limit on how deep we can efficiently scale models.
