Beyond Language Modeling: An Exploration of Multimodal Pretraining
Authors: Shengbang Tong, David Fan, John Nguyen, Ellis Brown, Gaoyue Zhou, Shengyi Qian, Boyang Zheng, Théophane Vallaeys, Junlin Han, Rob Fergus, Naila Murray, Marjan Ghazvininejad, Mike Lewis, Nicolas Ballas, Amir Bar, Michael Rabbat, Jakob Verbeek, Luke Zettlemoyer, Koustuv Sinha, Yann LeCun, Saining Xie
Paper: https://arxiv.org/abs/2603.03276
Page: https://beyond-llms.github.io/
TL;DR
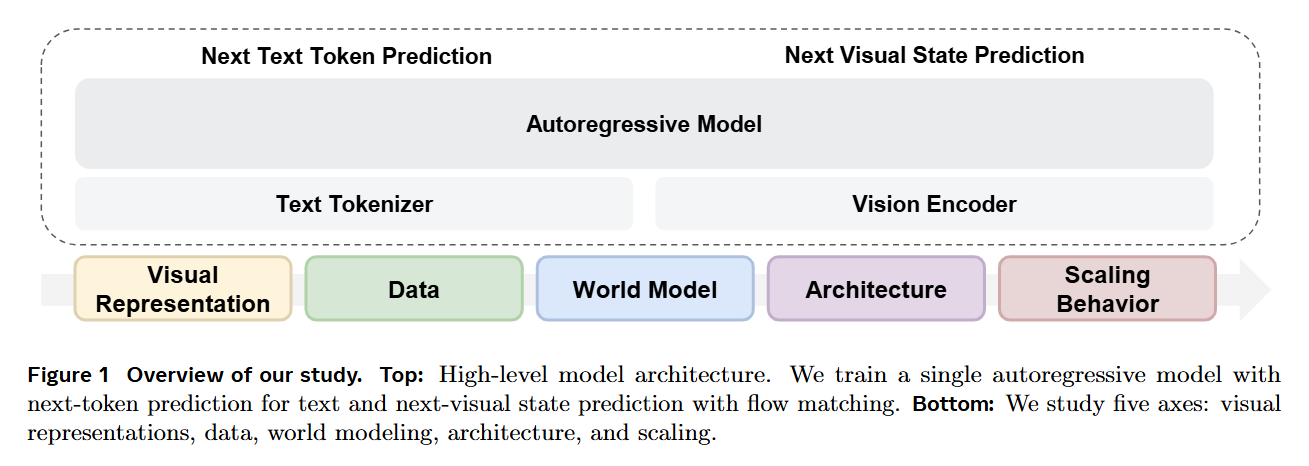
WHAT was done? Researchers at FAIR, Meta, and NYU conducted a controlled, from-scratch empirical study on unified multimodal pretraining. By combining discrete next-token prediction for language with continuous flow matching for vision within a single architecture, they systematically isolated the variables governing multimodal learning. They demonstrated that a single Representation Autoencoder (RAE) can handle both understanding and generation, and that Mixture-of-Experts (MoE) architectures naturally resolve the scaling asymmetries between language and vision.
WHY it matters? The prevailing approach to multimodal AI involves bolting visual adapters onto frozen language models, a paradigm that confounds new multimodal capabilities with inherited text priors. By training from scratch, this work maps the native scaling laws of unified models. It proves that modality competition is largely an architectural artifact, not a fundamental flaw, and demonstrates that world modeling capabilities—such as navigating an environment based on free-form text commands—emerge zero-shot purely from general multimodal pretraining.


Details
The Modality Competition Bottleneck
The foundation model landscape is currently constrained by a heavy reliance on text, a modality that acts as a lossy, low-bandwidth compression of physical reality. To capture physics, geometry, and causality, models must treat visual signals as first-class citizens. However, attempting to jointly train vision and language from scratch typically results in modality competition, where optimizing for one degrades the performance of the other. Consequently, most state-of-the-art systems freeze a pretrained language backbone and graft on visual pathways, obscuring the fundamental dynamics of how neural networks actually fuse multimodal distributions. This paper dismantles that post-hoc paradigm, utilizing the Transfusion framework to train a single decoder-only transformer from scratch on text, video, image-text pairs, and action-conditioned video, without relying on modality-specific architectural silos like U-Nets.