


Beyond the Learning Rate
Unpacking the Reality of Hyperparameter-Free Deep Learning
How far away are truly hyperparameter-free learning algorithms?
Authors: Priya Kasimbeg, Vincent Roulet, Naman Agarwal, Sourabh Medapati, Fabian Pedregosa, Atish Agarwala, George E. Dahl
Paper: https://arxiv.org/abs/2505.24005
Code: The study leverages the MLCommons AlgoPerf benchmark (https://github.com/mlcommons/algorithmic-efficiency) for evaluation, and some algorithm implementations were based on the Optax library (https://github.com/deepmind/optax).
TL;DR
WHAT was done? The paper systematically evaluates existing "learning-rate-free" (LRF) optimization algorithms to determine if they deliver on the promise of "hyperparameter-free" deep learning. It tests them on the diverse ALGOPERF benchmark, first with their literature-supplied defaults and then after an extensive "ALGOPERF-calibration" process. This calibration seeks a single set of non-learning rate hyperparameters (e.g., momentum, weight decay, schedule parameters) that performs well across all workloads. The performance of these calibrated LRF methods is then compared against similarly calibrated traditional baselines like AdamW.
WHY it matters? This work provides a crucial reality check, demonstrating that current LRF methods are not a silver bullet for eliminating the pervasive challenge of hyperparameter tuning. The study reveals that literature-supplied defaults for LRF optimizers often perform poorly out-of-the-box. Even after extensive calibration of their other hyperparameters, LRF methods do not decisively outperform traditional optimizers that have undergone similar cross-workload calibration. This underscores that the learning rate schedule and other associated parameters remain critical tuning points, guiding future research towards more holistic and genuinely robust solutions for reducing tuning burden and improving reproducibility in deep learning.

Details
Many an AI practitioner has lost sleep to the dark art of hyperparameter tuning – that costly, often frustrating quest for the magic numbers that unlock a model's true potential. "Learning-rate-free" (LRF) optimizers emerged as a promising dawn, offering hope to adapt the most critical parameter, the learning rate, automatically. This paper, "How far away are truly hyperparameter-free learning algorithms?", tackles a critical question: how close are these LRF methods to the dream of algorithms that work robustly across diverse tasks without painful, workload-specific tuning?
The primary contribution of this research is not a new algorithm, but a systematic and rigorous empirical evaluation of this very promise. The authors' key innovation lies in:
Defining "hyperparameter-free" in a practical, demanding sense: can an algorithm, with a single fixed set of its non-learning rate hyperparameters, perform well across a multitude of different tasks? The authors clarify this scope: workload-agnostic regularization methods like weight decay and dropout are considered part of the training algorithm's tunable hyperparameters, while architectural design choices are deemed part of the fixed workload definition.
Executing an extensive "ALGOPERF-calibration" process to find such a universal set of hyperparameters for both LRF methods and standard baselines, leveraging the diverse ALGOPERF benchmark.
Methodology: A Crucible for "Hyperparameter-Free" Claims
The study's methodology is central to its impact, designed to provide an "evidence-based calibration" of LRF methods against strong, general-purpose baselines.
The Arena: The ALGOPERF: Training Algorithms benchmark (https://arxiv.org/abs/2306.07179) serves as the testing ground. This benchmark features 8 diverse workloads spanning image, text, speech, and graph domains using various model architectures (Table 2). This diversity is crucial for assessing genuine cross-workload generalization, a cornerstone of the "hyperparameter-free" ideal.

Phase 1: The "Out-of-the-Box" Test: A suite of LRF methods (including DOG, DOWG, PRODIGY, D-ADAPT, MECHANIC, CoCoB, and MoMo) were first evaluated using their literature-supplied default hyperparameter values (Table 1), often sourced from their reference implementations or libraries. This initial phase employed minimal additional tuning, for instance, setting weight decay to zero.

Phase 2: The "ALGOPERF-Calibration": Recognizing the potential limitations of naive defaults, the authors undertook a comprehensive hyperparameter search. The objective was not to find the best parameters for each individual workload, but rather to discover a single configuration (for parameters such as weight decay, dropout, label smoothing, warmup fraction, training horizon, and momentum terms like β1, β2 – search space detailed in Table 3) that performed well simultaneously across all ALGOPERF workloads.

This involved a quasi-random search of 200 configurations for each algorithm and various training horizons (33%, 50%, and 66% of maximum steps). The top-performing configurations, selected based on the geometric mean of time-to-target metrics, were then re-trained with 5 independent random seeds for final evaluation using the AlgoPerf Benchmark Score. This score is an aggregate measure derived from performance profiles (Figure 1), which illustrate how often an algorithm is within a certain factor of the best performer.

Fair Comparison: Critically, standard baselines like AdamW and NADAMW were subjected to the same rigorous ALGOPERF-calibration process. This ensures a fair comparison against robustly configured alternatives, moving beyond comparisons to easily beaten naive or unoptimized baselines.




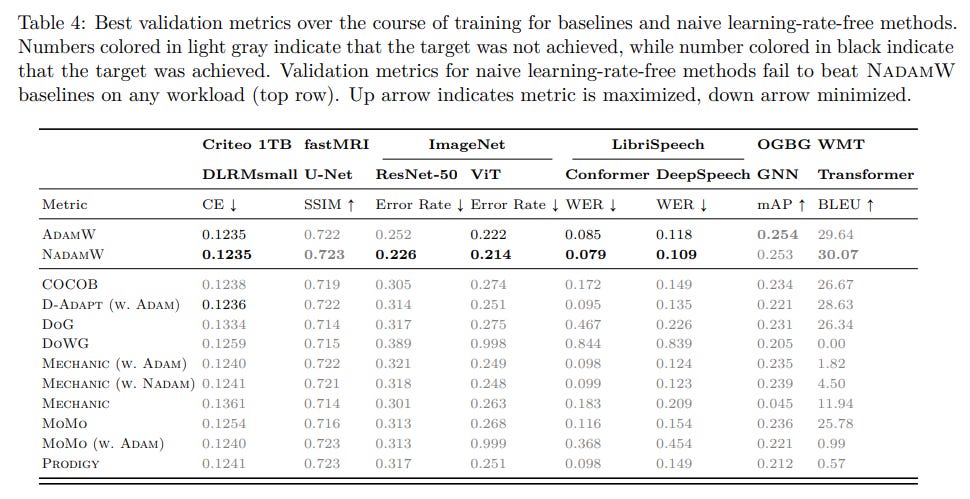
The rationale for this meticulous approach is clear: the authors aim to assess the true "plug-and-play" potential of LRF methods. As the results would show, the initial poor performance of naive defaults (Table 4) strongly underscored the necessity of such a calibration step.
Experimental Results & Analysis: A Sobering Reality
The findings from this extensive evaluation paint a nuanced and rather sobering picture of the current state of LRF optimizers:
Literature Defaults Fall Short: The "out-of-the-box" LRF methods, when used with their published default settings, generally performed poorly. As detailed in Table 4 and visualized in the training curves (Figures 2-9), most of these methods failed to reach the target performance levels on the majority of the benchmark's diverse workloads.
Calibration is Key (Even for LRF Methods): The "ALGOPERF-calibration" process significantly boosted the performance of the more promising LRF methods, particularly PRODIGY and MECHANIC (Table 5). Once calibrated, these methods successfully trained models on a greater number of workloads and achieved competitive validation metrics.

Competitive, But Not Conclusively Superior: Despite the improvements from calibration, the top-performing LRF methods (PRODIGY, MECHANIC) did not decisively outperform similarly calibrated AdamW and NADAMW baselines in terms of the overall AlgoPerf benchmark score (Table 6, Figure 1). While they demonstrated promise on certain tasks, they did not offer a clear, consistent advantage that would suggest they fundamentally simplify the tuning process or yield universally better general-purpose defaults.

"Learning-Rate-Free" is Not "Hyperparameter-Free": A critical insight emerging from the study is that LRF methods, despite their name, are not truly free of all hyperparameter tuning. They still require careful selection of a "training horizon" (i.e., the total number of training steps) or a relative learning rate schedule (often involving warmup and decay phases). These schedule-related parameters essentially act as workload-dependent hyperparameters themselves; for instance, parameters defining the length of a warmup phase or the total steps over which the learning rate decays to zero often need to be set based on the specific task or computational budget, thus reintroducing a significant tuning requirement. The authors also noted that the LRF property did not appear to make the tuning of other hyperparameters (like momentum or weight decay) noticeably easier.
The Schedule Matters Significantly: An informal comparison with SCHEDULE-FREE ADAM (detailed in Table 10), an algorithm that recently won an ALGOPERF competition by specifically aiming to remove the learning rate schedule, suggests that this aspect might be an even more potent target for achieving genuine hyperparameter-freeness than solely eliminating the base learning rate.

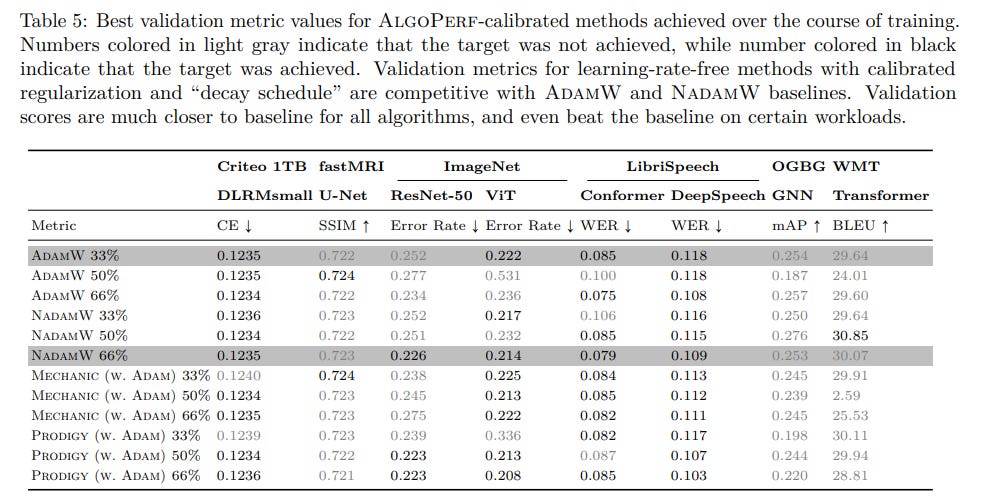
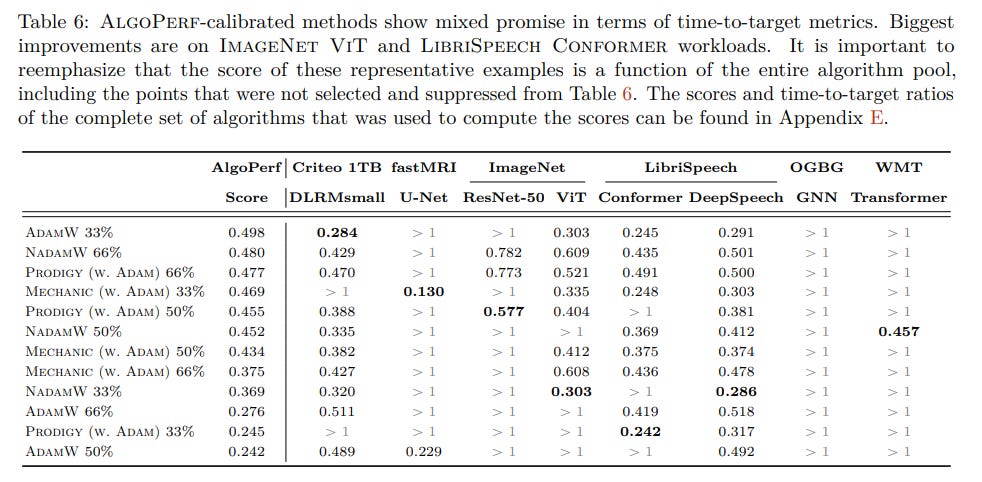

While the paper mentions that calibrated methods were run with 5 independent random seeds, the main comparison tables and figures do not present error bars or confidence intervals. This makes a direct statistical assessment of the observed differences challenging from the provided visuals alone.
Strengths and Weaknesses of the Study
The paper's primary strength lies in its exceptionally rigorous and transparent evaluation methodology. The use of the diverse ALGOPERF benchmark combined with the novel "ALGOPERF-calibration" approach for both LRF methods and strong baselines provides a much-needed, fair assessment of the current state-of-the-art. It courageously tackles a highly pertinent problem—the substantial cost and complexity of hyperparameter tuning in deep learning. The clear demonstration that literature defaults for LRF methods are often suboptimal is a crucial, if somewhat disheartening, insight for the field.
However, the study also highlights inherent limitations and ongoing challenges:
The "hyperparameter-free" ideal remains elusive. Even the best LRF methods require careful tuning of other parameters, especially those related to training horizons and relative learning rate schedules.
The computational cost of the ALGOPERF-calibration process itself is substantial. While necessary for finding robust "universal" defaults, it implies that optimizing these LRF methods for broad generalization still requires significant computational effort on the part of researchers developing or benchmarking them.
The scope, while focused on learning rates and associated optimizer parameters, acknowledges that true hyperparameter freedom would need to encompass architectural choices, regularization strategies, and other aspects beyond just the optimizer.
The comparison to SCHEDULE-FREE ADAM, while insightful, is based on recomputed scores from competition results, which the authors note is an approximation.
Broader Implications & Impact: Charting the Course Ahead
This work serves as a significant reality check for the AI research community.
It tempers the enthusiasm surrounding LRF methods as a complete panacea for hyperparameter tuning, emphasizing that the problem's complexity extends beyond just the base learning rate.
It compellingly shifts focus towards the criticality of learning rate schedules. The journey towards simpler and more robust model training might lie more in developing adaptive or schedule-free approaches than solely in LRF mechanisms for the base rate.
It champions a paradigm of evidence-based defaults and rigorous, cross-workload benchmarking. The authors advocate for researchers introducing new algorithms to provide robust, calibrated default hyperparameter settings that generalize well, rather than showcasing performance only on select tasks with extensive, specific tuning. This practice can significantly enhance reproducibility and accelerate collective progress.
The findings carry implications for Automated Machine Learning (AutoML) and Hyperparameter Optimization (HPO) systems. These systems cannot assume that LRF optimizers automatically reduce the search space or complexity for all other crucial hyperparameters.
For the increasingly important domain of large model training, where tuning is prohibitively expensive, the paper underscores that even optimizers designed to reduce the hyperparameter burden may still necessitate careful consideration and potential adaptation of their other parameters and schedules.
Future Directions: The Ongoing Quest
The authors delineate several important avenues for future research:
Continuing the development of LRF methods with the goal of demonstrably and consistently outperforming strong, well-calibrated baselines across diverse workloads.
Innovating algorithms that successfully eliminate or robustly automate the need for relative learning rate schedules, including warmup and decay phases.
Designing scale-aware optimizers, potentially incorporating heuristics or dimensionally-aware parameterizations for hyperparameters, to ensure effectiveness across models trained at various scales.
A persistent community effort towards establishing and publishing evidence-based default settings for new algorithms, thoroughly validated on diverse benchmarks.
Conclusion & Overall Assessment
"How far away are truly hyperparameter-free learning algorithms?" offers a valuable, meticulously researched, and timely contribution to the field of deep learning optimization. It does not present a new silver-bullet optimizer, but instead delivers an insightful empirical study that tempers current expectations while illuminating a pragmatic path forward. The paper's rigorous methodology and candid assessment reveal that while notable progress has been made with learning-rate-free techniques, the dream of truly "set-and-forget" deep learning algorithms remains, as the title aptly suggests, still some way off.
The core message is unambiguous: simply being "learning-rate-free" is insufficient. The broader ecosystem of hyperparameters, particularly those governing training schedules, continues to demand significant attention and tuning. This work stands as a strong call for more rigorous, cross-workload evaluation practices and a concerted effort towards the development of genuinely robust default configurations for machine learning algorithms. It is a recommended read for anyone involved in developing, evaluating, or applying deep learning optimization techniques, and for those keenly observing the ongoing quest to make AI more accessible, efficient, and reproducible. While the journey to truly hyperparameter-free learning is far from over, this paper provides an excellent map of the current terrain and highlights promising, albeit challenging, routes for future exploration.