
Why Transformers are Graph Neural Networks Winning the Hardware Lottery
Transformers are Graph Neural Networks
Authors: Chaitanya K. Joshi
Paper: https://arxiv.org/abs/2506.22084
TL;DR
WHAT was done? This paper formally establishes that the Transformer architecture is a specific instance of a Graph Neural Network (GNN). It demonstrates that the multi-head self-attention mechanism is mathematically equivalent to a message-passing GNN operating on a fully connected graph, where every input token is a node that attends to every other token. This perspective recasts the input sequence not as a line, but as a complete graph where positional encodings act as soft structural hints rather than hard constraints.
WHY it matters? This unifying perspective provides two crucial insights. First, it clarifies that Transformers are highly expressive "set processing networks" capable of learning complex global relationships without the constraints of a predefined sparse graph. Second, it powerfully argues that the Transformer's dominance is a result of "winning the hardware lottery" (a concept explored in https://arxiv.org/abs/2009.06489). Its implementation via dense matrix operations is vastly more efficient and scalable on modern GPUs and TPUs than the sparse message-passing operations typically used by GNNs. This hardware alignment, not just theoretical superiority, is presented as the key driver behind the Transformer's unprecedented success and the rise of foundation models.
In case you feel Deja Vu, you are not mistaken. The same author explored this idea five years ago, but without hardware lottery (the paper on that emerged later).

Details
In the landscape of modern deep learning, Transformers and Graph Neural Networks (GNNs) have often been viewed as distinct architectural lineages, each dominating its respective domain—natural language and structured graph data. This paper offers a compelling and insightful bridge between these two worlds, arguing not just for a conceptual similarity but for a formal equivalence. It presents a clear narrative: Transformers are, in essence, a specialized form of GNN that have achieved widespread success by being exceptionally well-suited to the architecture of modern parallel hardware.
The Formal Equivalence: From Sequences to Fully Connected Graphs
The paper begins by tracing the evolution from sequential models like RNNs to the parallel-first architecture of Transformers (Figure 1). The core innovation, the self-attention mechanism, was introduced in the seminal paper "Attention Is All You Need" (https://arxiv.org/abs/1706.03762) and allowed every token in an input to interact directly with every other token, overcoming the long-range dependency issues of its predecessors.
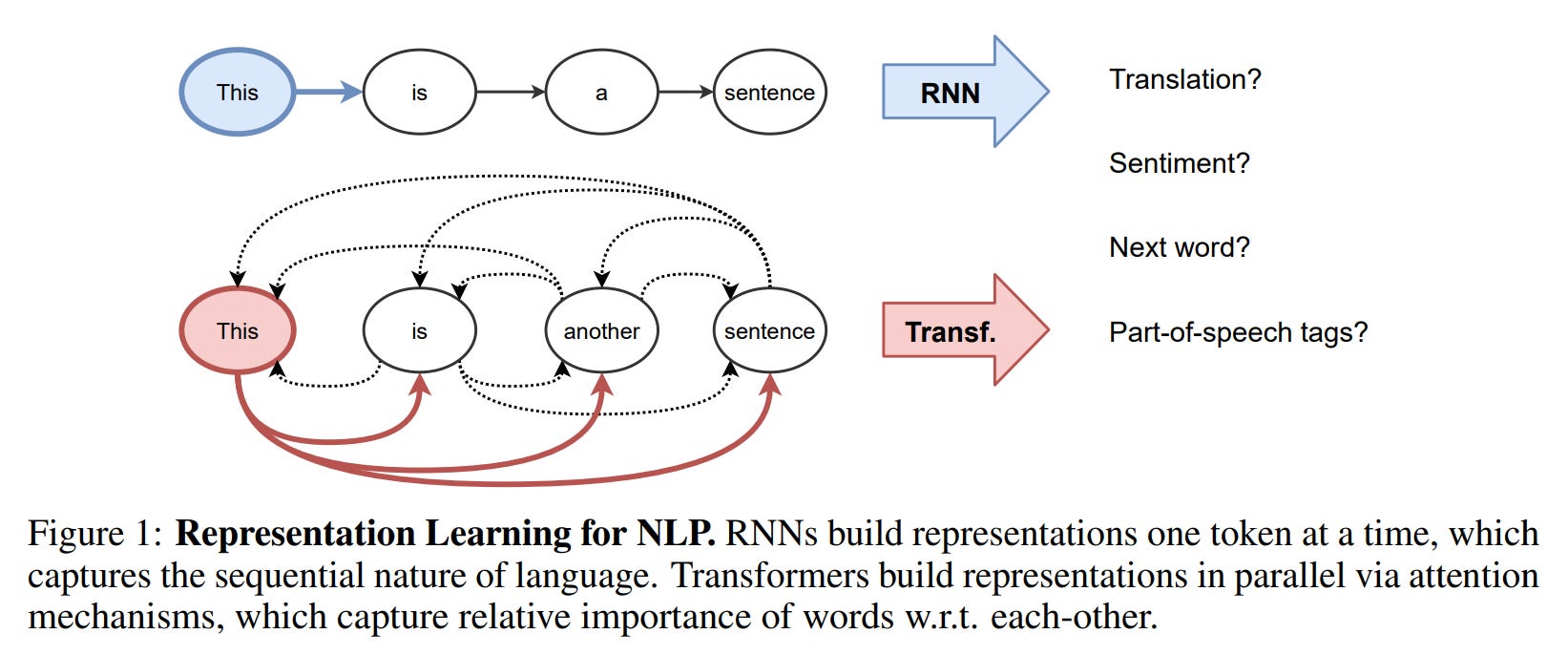
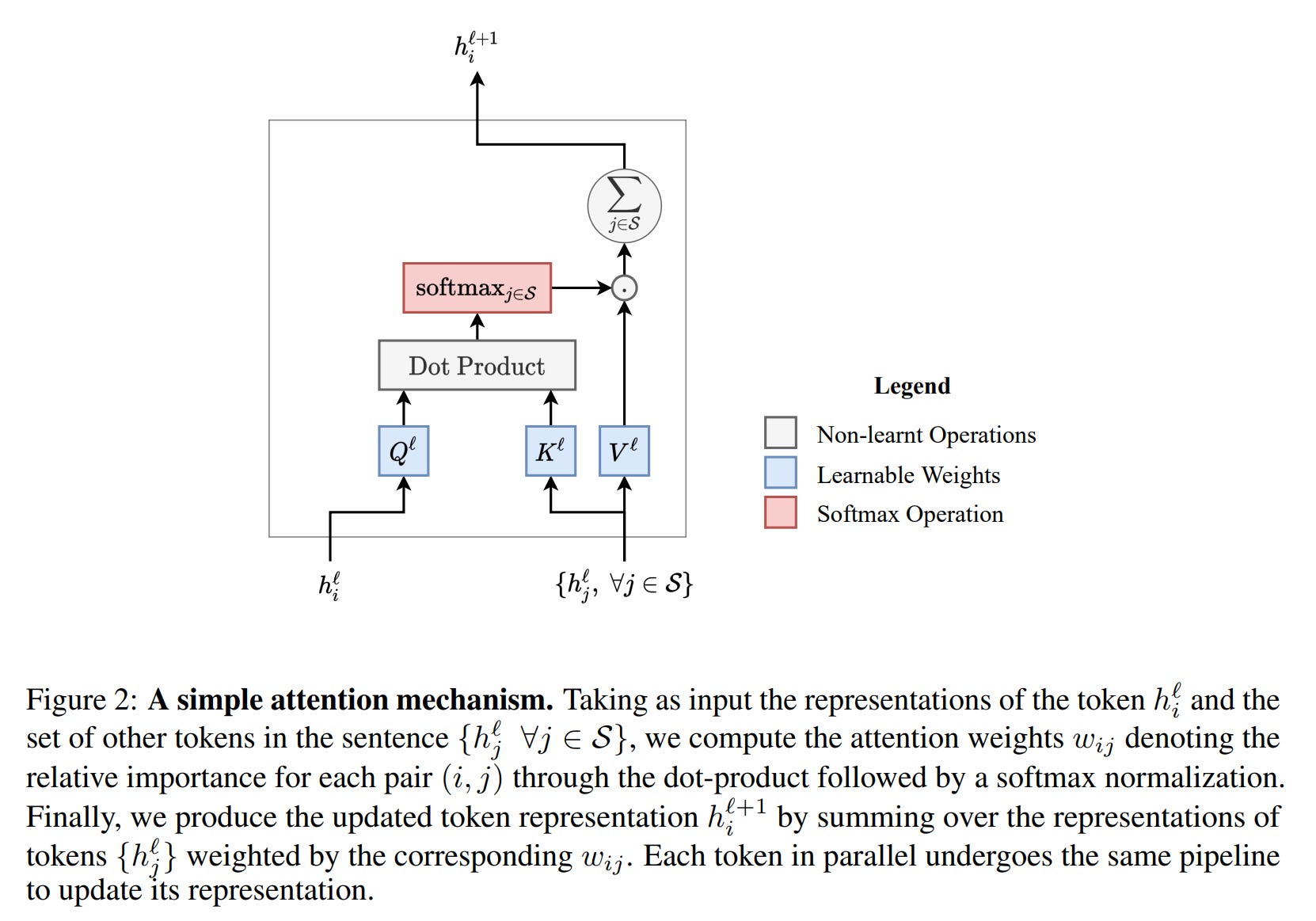
The author then methodically builds the case for equivalence. A Transformer layer is deconstructed into its key components: the multi-head attention sub-layer, where attention weights are computed via dot-products of Query, Key, and Value projections (Figure 2),
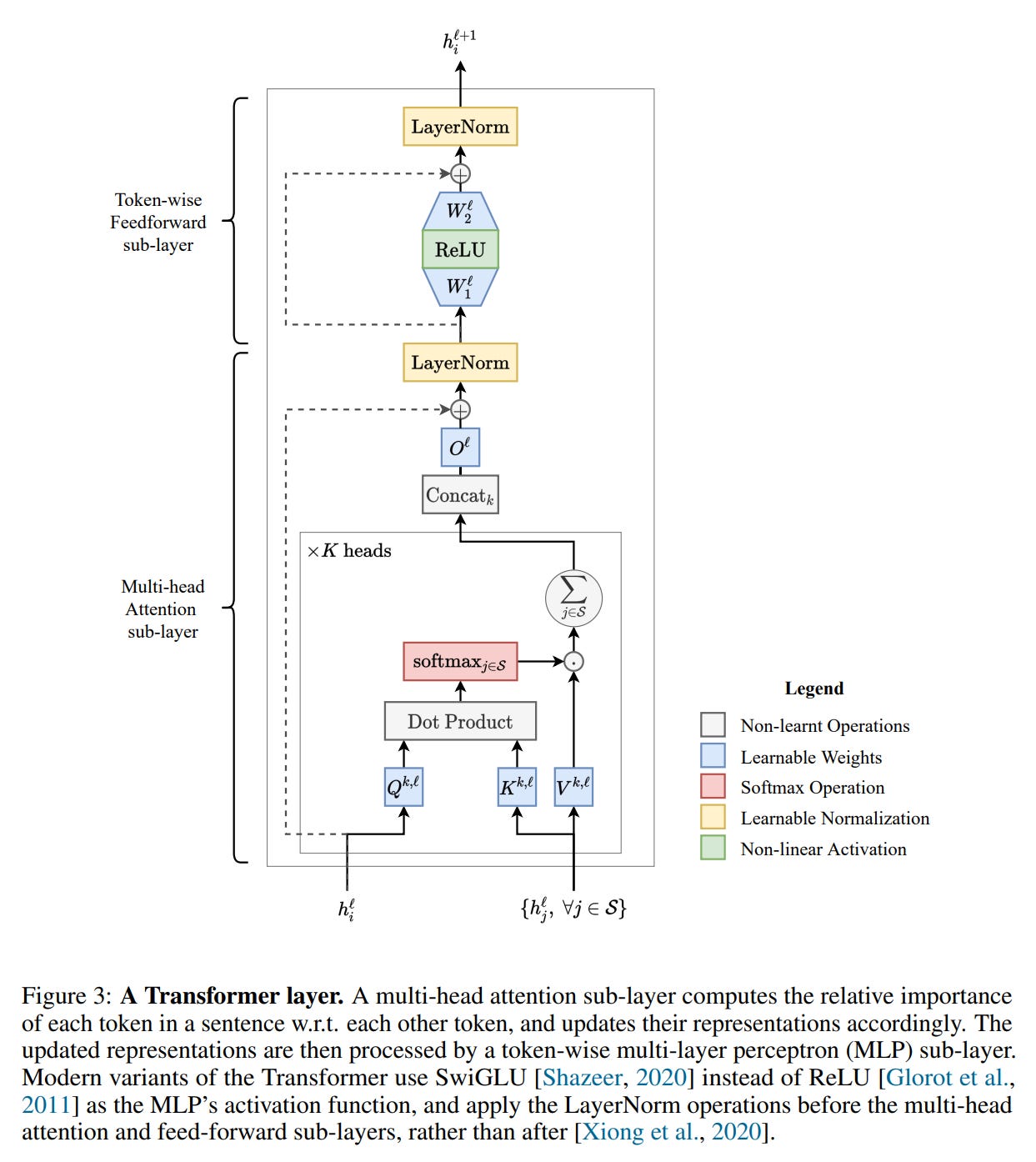
and a token-wise feed-forward network, all tied together with residual connections and layer normalization (Figure 3).
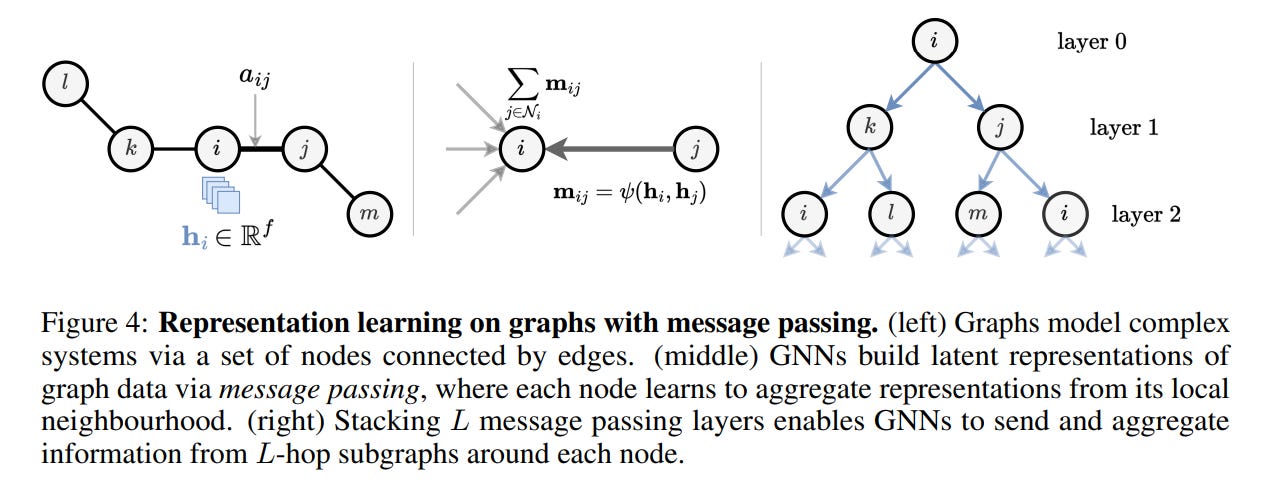
Next, the paper introduces the standard message-passing framework for GNNs, which is particularly well-exemplified by Graph Attention Networks (GATs) (https://arxiv.org/abs/1710.10903). GNNs operate by having nodes iteratively construct, aggregate, and update messages from their local neighbors (Figure 4).
The "aha!" moment comes when these two frameworks are placed side-by-side. The paper demonstrates that a Transformer's self-attention is a direct implementation of message passing on a fully connected graph. In this formulation, a sequence of n tokens becomes a graph with n nodes and n² edges, as every token-node is connected to every other. This perspective clarifies why self-attention's computational complexity scales quadratically with sequence length (not to say it was unclear before, honestly). This is a fundamental departure from typical GNNs, where the graph's sparse connectivity is a hard architectural constraint. A Transformer, by operating on a complete graph, discards this structural assumption and instead learns relationships from the data itself. Positional encodings re-introduce information about the original sequence order not as a rigid structure, but as a feature—a 'soft hint'—that the model can learn to use, providing immense flexibility.
The "Hardware Lottery": Why Implementation Matters
While the theoretical link is elegant, the paper's most impactful contribution is its practical explanation for the Transformer's dominance: it won the "hardware lottery." This concept, articulated to describe how certain algorithmic approaches succeed because they match the capabilities of available hardware (https://arxiv.org/abs/2009.06489), is central to this paper's thesis.
Despite being conceptually equivalent to a GNN, the Transformer's implementation differs critically. GNNs typically rely on sparse message passing (e.g., gather-scatter operations) to propagate information along predefined edges. In contrast, a Transformer's global attention is implemented as a series of dense matrix multiplications (Equation 20), an operation that is massively parallelizable and highly optimized on modern GPUs and TPUs.

This architectural alignment with hardware has profound consequences. It makes Transformers "orders of magnitude" faster to train and easier to scale than their sparse GNN counterparts for most typical problem sizes. This efficiency advantage enabled the training of massive foundation models on vast datasets, allowing them to learn complex, implicit relationships and even inductive biases like locality, which are explicitly encoded in traditional GNNs.
Impact and Broader Implications
This paper does more than just re-categorize an architecture; it reframes our understanding of what drives progress in AI. It highlights that the success of a model is a function of both its theoretical expressivity and its practical, hardware-level efficiency.
This perspective helps explain the rise of "Graph Transformers," a new class of models that seeks to combine the explicit structural biases of GNNs with the scalable global attention of Transformers (as explored in works like https://arxiv.org/abs/2012.09699). By understanding Transformers as GNNs on a complete graph, researchers can more effectively reason about how to blend local, sparse message passing with global, dense attention to create more powerful and efficient models for structured data.
Conclusion
Ultimately, this paper is more than an academic exercise in re-categorization. It is a powerful reminder that progress in AI is driven by a deep synergy between algorithmic theory and hardware reality. While not presenting novel empirical results, its conceptual clarity and powerful "hardware lottery" argument make it a valuable contribution. It challenges researchers to think beyond architectural novelty and consider which ideas are best positioned to win the next hardware lottery, fundamentally shaping the future of scalable and powerful artificial intelligence.