
Compute as Teacher: Turning Inference Compute Into Reference-Free Supervision
Authors: Dulhan Jayalath, Shashwat Goel, Thomas Foster, Parag Jain, Suchin Gururangan, Cheng Zhang, Anirudh Goyal, Alan Schelten
Paper: https://arxiv.org/abs/2509.14234
TL;DR
WHAT was done? The paper introduces Compute as Teacher (CaT), a method that transforms a model’s own exploratory outputs into high-quality, reference-free supervision. Instead of selecting the “best” answer from a group of parallel rollouts, CaT uses a frozen “anchor” policy to synthesize a single, improved reference by reconciling contradictions and integrating partial solutions. For verifiable tasks like math, this synthesized answer acts as a target for programmatic checkers. For non-verifiable domains like healthcare dialogue, CaT introduces a novel mechanism: the anchor generates self-proposed rubrics (fine-grained, binary criteria) from the synthesized reference, which are then scored by an LLM judge to provide a robust reward signal for Reinforcement Learning (CaT-RL).
WHY it matters? CaT provides a powerful solution to the supervision bottleneck in specialized LLM post-training, particularly in domains where ground truth is expensive, subjective, or non-existent. Its synthesis-over-selection approach is a paradigm shift; it enables genuine self-correction, producing correct answers even when all individual rollouts are flawed—a feat impossible for methods like best-of-N or majority vote. The self-proposed rubric mechanism makes reliable RL fine-tuning feasible in subjective areas, mitigating the known biases of coarse LLM-as-a-judge scoring. This work establishes a practical framework for trading inference compute for supervision, paving the way for more autonomous and scalable model improvement.

Details
The Supervision Bottleneck
Imagine a team of junior analysts all attempting a complex problem. Each one might get a different part of the solution right while making unique errors. A simple vote might lead to a popular but flawed conclusion. But a skilled manager could look at all the attempts, identify the common strengths, reconcile the contradictions, and synthesize a final report that is more accurate than any single individual’s work. This is the core intuition behind “Compute as Teacher” (CaT), a framework that addresses one of the most significant challenges in modern AI: the supervision bottleneck.
Post-training large language models (LLMs) for specialized skills typically requires a robust source of supervision, either through labeled references or verifiable rewards. However, for many valuable tasks—from creative writing to clinical guidance—such clean supervision is scarce, expensive, or simply doesn’t exist. This forces practitioners to rely on costly annotation pipelines or brittle, holistic scores from other LLMs, which are prone to verbosity bias and instability. This paper asks a fundamental question: Can inference compute substitute for missing supervision?
It’s important to understand CaT’s approach in the context of other recent reference-free methods. While techniques like TTRL (https://arxiv.org/abs/2504.16084) also use multiple rollouts, they typically rely on selection mechanisms like finding a majority consensus. CaT’s paradigm shift to synthesis—constructing a new, better answer from the pieces of imperfect ones—is what allows it to be correct even when all rollouts (and thus the majority consensus) are wrong. This fundamentally distinguishes it from prior work and opens up new avenues for self-correction.
Methodology: From Exploration to Supervision
The CaT pipeline is a three-stage process that turns a group of parallel model outputs into a refined learning signal (Figure 1).
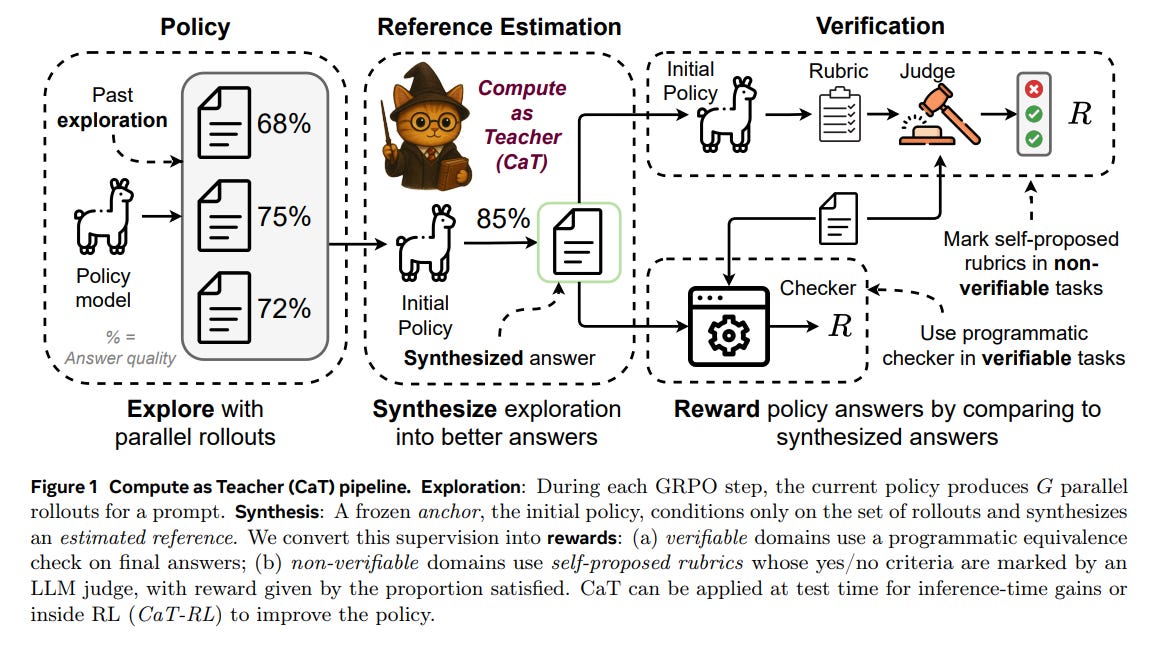
Exploration: The current policy, π_t, generates a set of G parallel rollouts, {o_i} i=1..G, for a given prompt q.
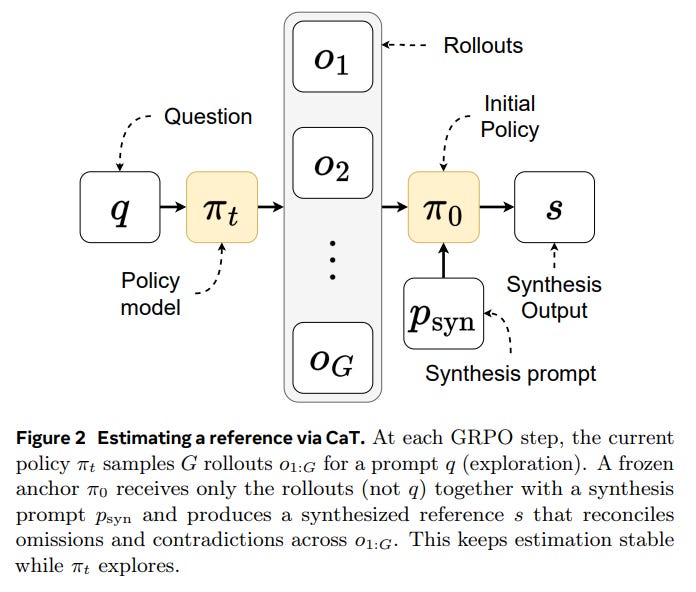
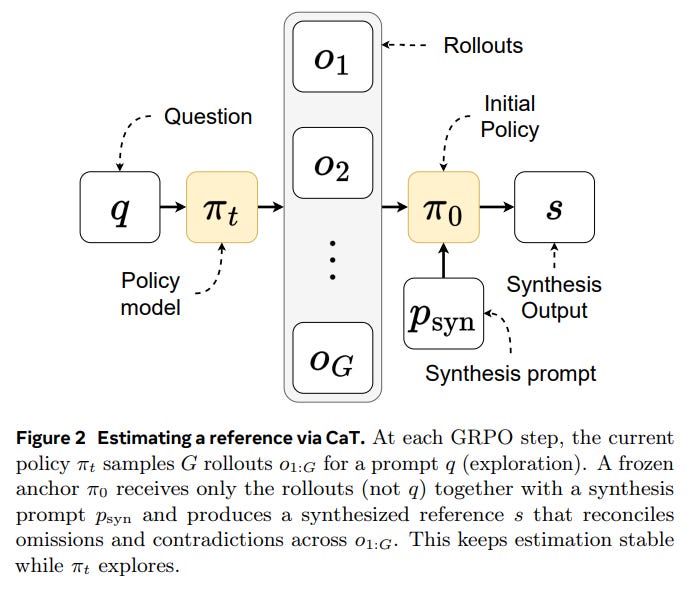
Synthesis (Reference Estimation): This is the core innovation of CaT. A frozen anchor policy, π_0 (typically the initial, pre-trained model), conditions only on the set of rollouts {o_i} and a synthesis prompt p_syn to produce a single, synthesized reference, s.


This step is designed to reconcile omissions, contradictions, and partial solutions across the rollouts. Crucially, the anchor is kept “question-blind” (it doesn’t see the original prompt q) to force genuine cross-rollout reasoning rather than just generating another independent answer (Figure 2). This separation of roles—with π_t exploring and the stable π_0 estimating—is key to the framework’s stability.
Verification (Reward Generation): The synthesized reference s is then converted into a reward signal for Reinforcement Learning. The mechanism depends on the domain:
Verifiable Tasks (e.g., math): A simple programmatic checker verifies if a rollout’s final answer matches the one in s, yielding a binary reward

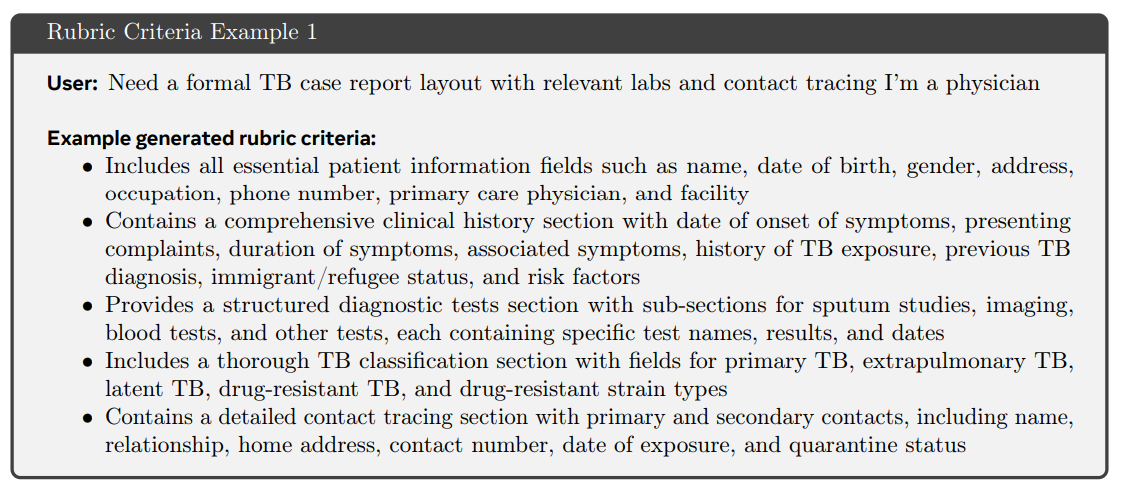
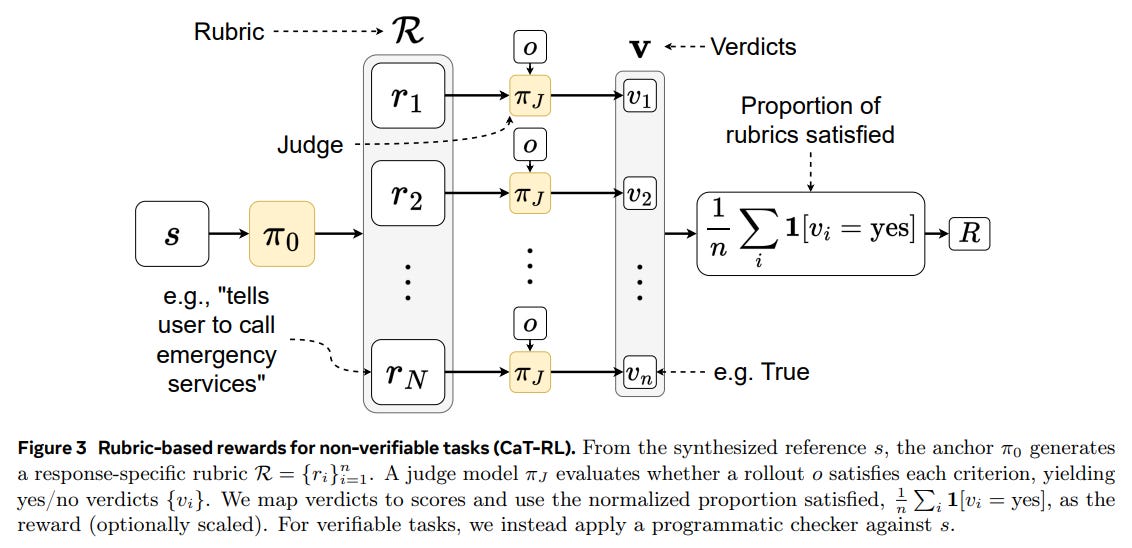
Non-Verifiable Tasks (e.g., healthcare): CaT introduces self-proposed rubrics. The anchor π_0 generates a response-specific rubric R = {r_i}—a set of binary, auditable criteria—based on the synthesized reference s.

An independent LLM judge, π_J, then evaluates whether a rollout o satisfies each criterion. The reward is the proportion of satisfied criteria:
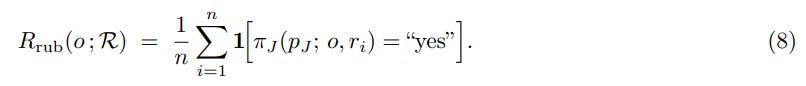
This is a crucial innovation: it decomposes a single, coarse, and often unstable holistic judgment (’is this good?’) into a set of fine-grained, auditable, and binary criteria.
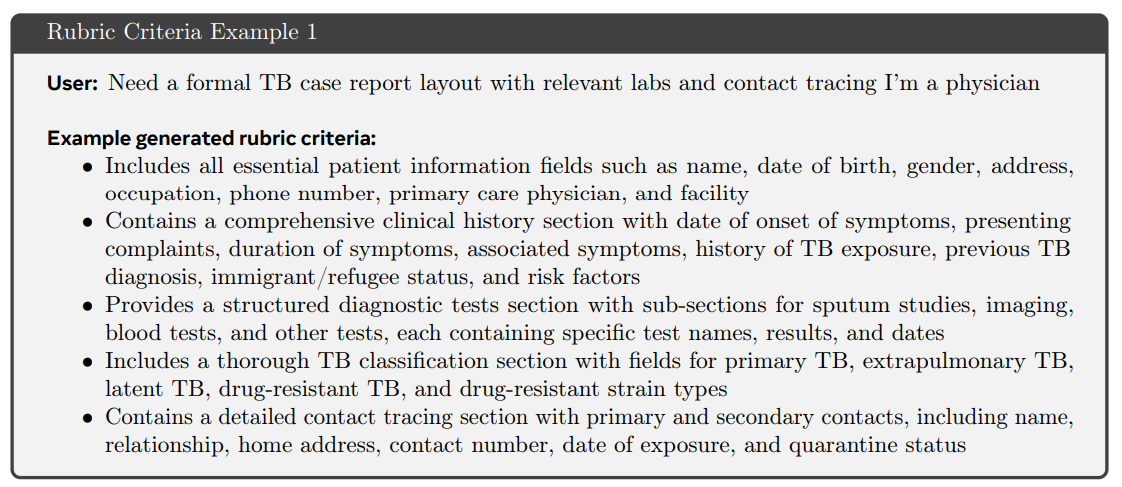
This decomposition is key to mitigating the known instabilities and surface-form biases (e.g., rewarding longer answers) that plague standard LLM-as-a-judge scoring systems (Figure 3).




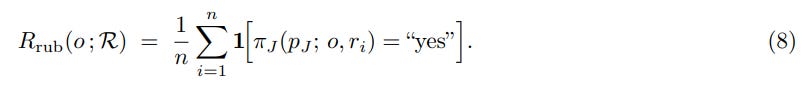
This entire process is integrated into a Group Relative Policy Optimization (GRPO) loop—a memory-efficient variant of PPO that avoids a learned value function by using the average reward of the group of rollouts as a baseline. This makes it particularly well-suited for CaT’s multi-rollout structure, allowing the policy π_t to be fine-tuned (CaT-RL) without any external reference data.

Experimental Validation: A Clear Win for Synthesis
The authors evaluated CaT across three model families (Gemma 3 4B, Qwen 3 4B, Llama 3.1 8B) on the verifiable MATH-500 dataset and the non-verifiable HealthBench dataset.
Key Findings:
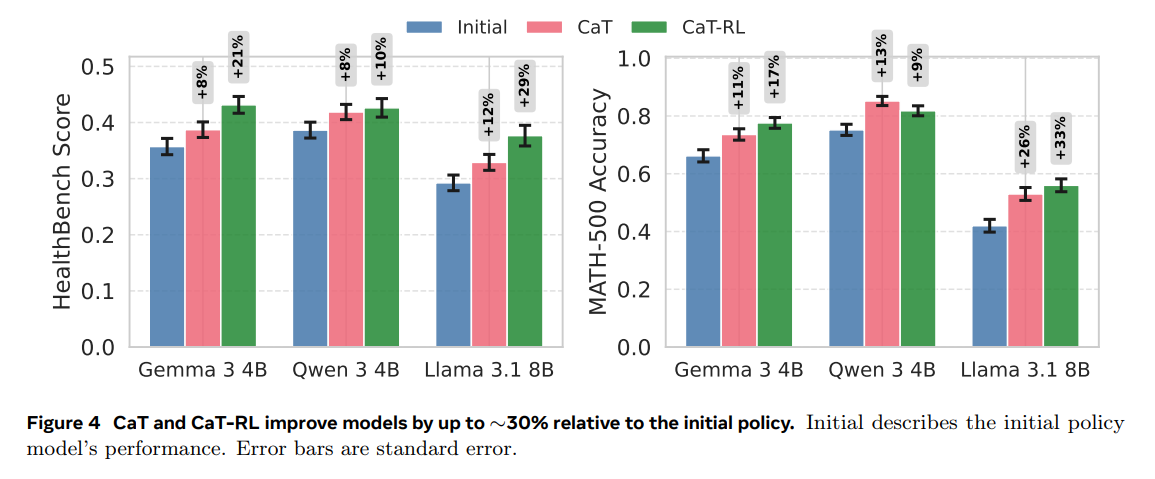
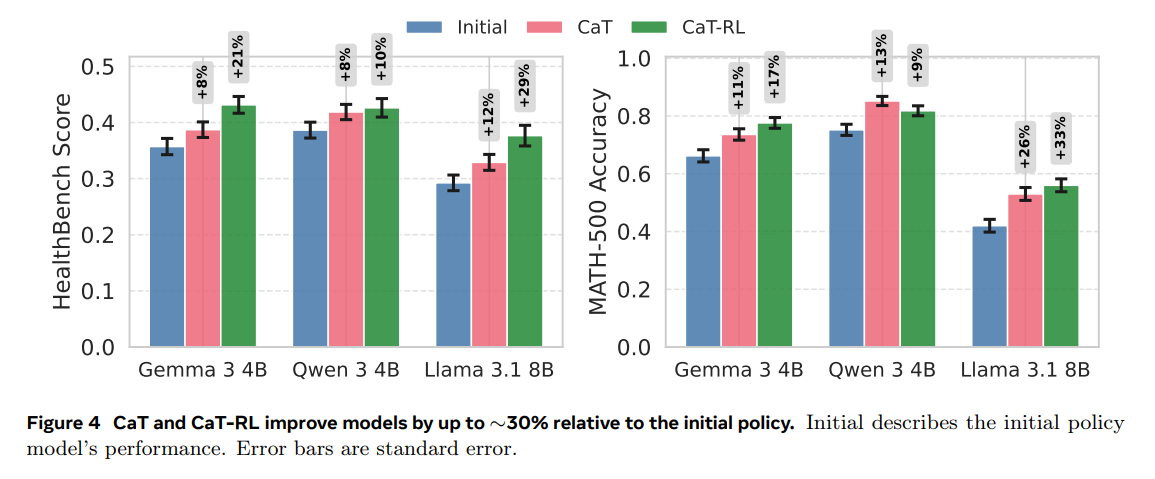
Significant Performance Gains: CaT-RL delivers substantial improvements over the initial policy, achieving up to a 33% relative gain on MATH-500 and a 30% gain on HealthBench with Llama 3.1 8B (Figure 4). The trained policy consistently improves upon the teacher signal provided by CaT, demonstrating a virtuous cycle of learning.
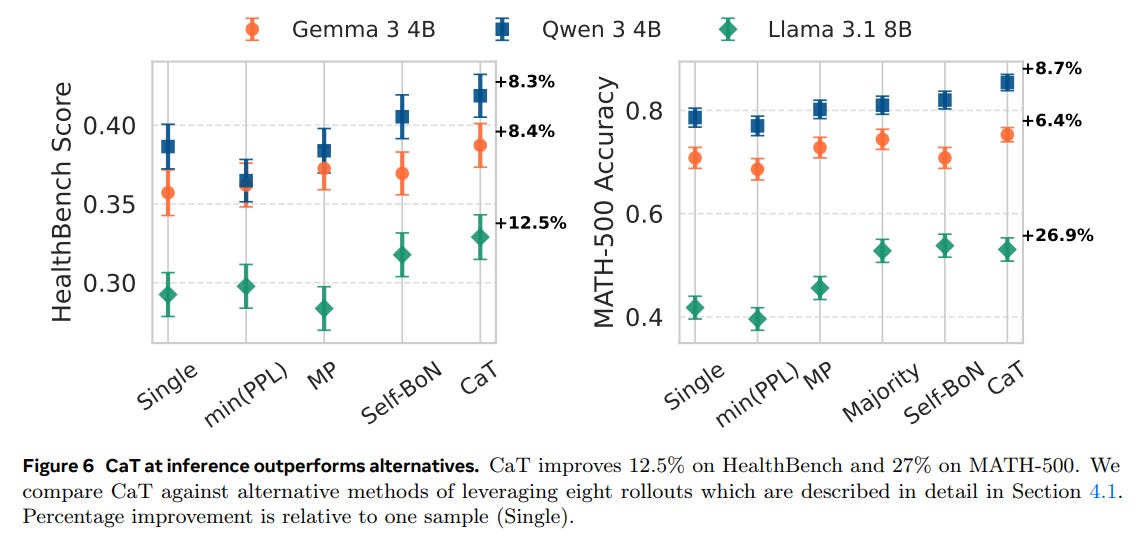
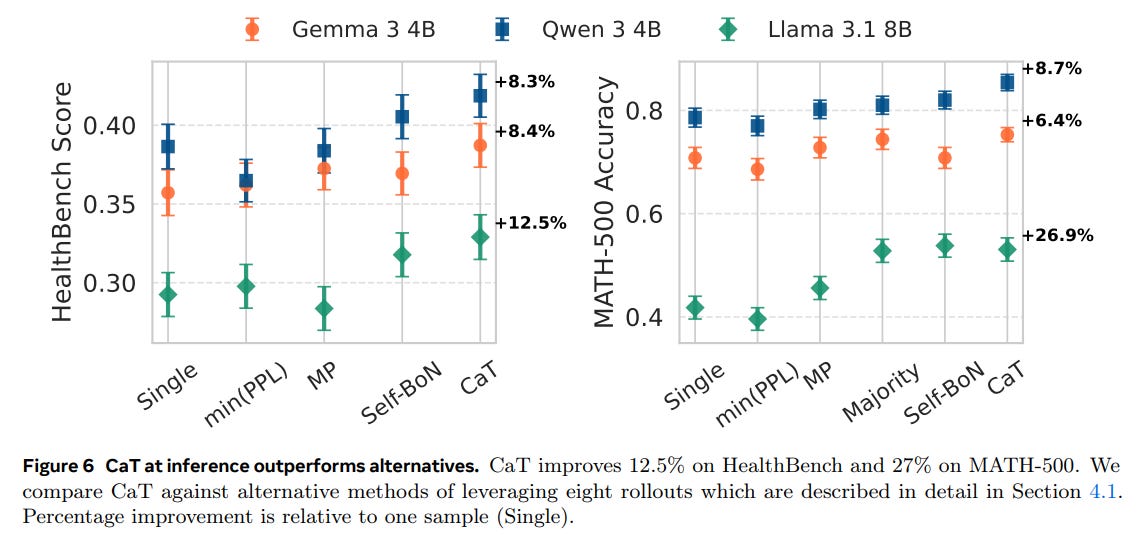
Synthesis Outperforms Selection: When used at inference time, CaT’s synthesis approach is superior to all tested selection baselines, including single-sample, minimum perplexity (minPPL), and majority voting. On MATH-500, it provides up to a 27% relative improvement over a single sample (Figure 6).
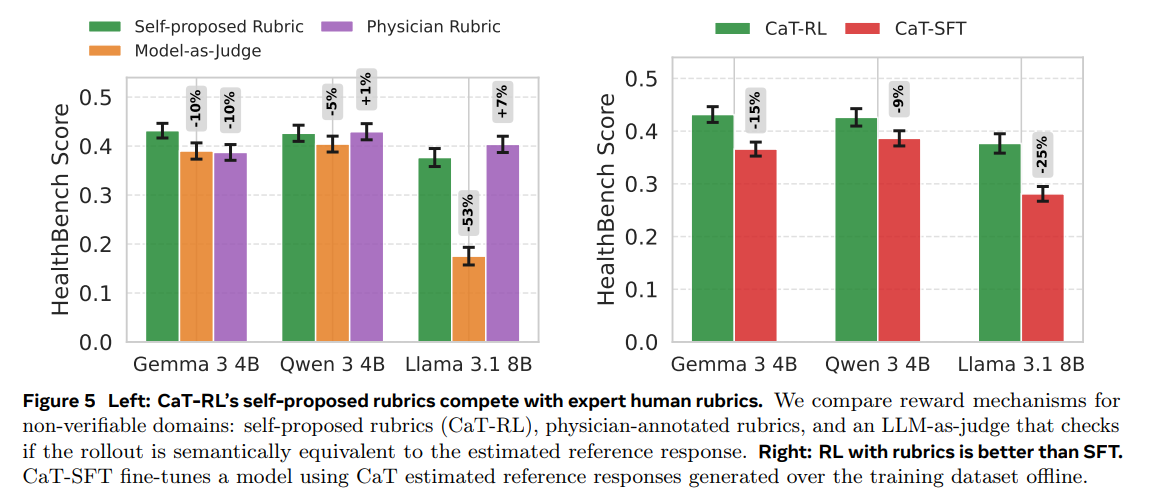
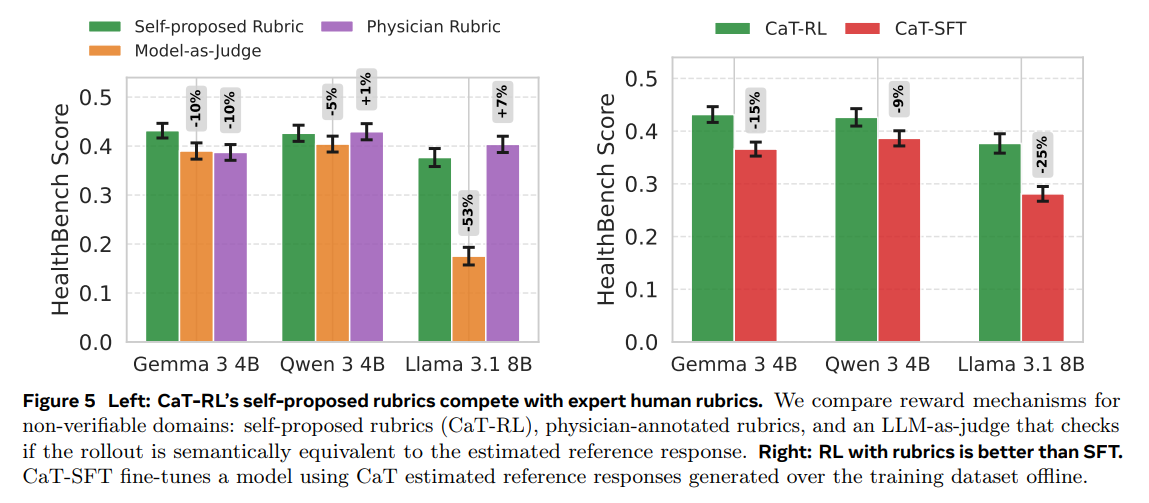
Self-Proposed Rubrics are Highly Effective: In the non-verifiable HealthBench domain, the self-proposed rubric rewards proved more effective than a standard model-as-a-judge baseline and were competitive with expert-annotated physician rubrics. Furthermore, RL with these rubrics (CaT-RL) outperformed supervised fine-tuning (SFT) on the synthesized references (Figure 5).
True Self-Correction: The most remarkable finding, bordering on algorithmic alchemy, is CaT’s proven ability to produce a correct answer even when every single input rollout is wrong. This occurred in approximately 1% of the challenging MATH-500 problems (Appendix A). This is not simply picking the ‘least wrong’ option; it is a genuine act of error correction and reasoning that transcends the initial distribution of answers, a capability impossible for any method based on selection. CaT also disagreed with the majority consensus 14% of the time, further highlighting its capacity for structured reconciliation.

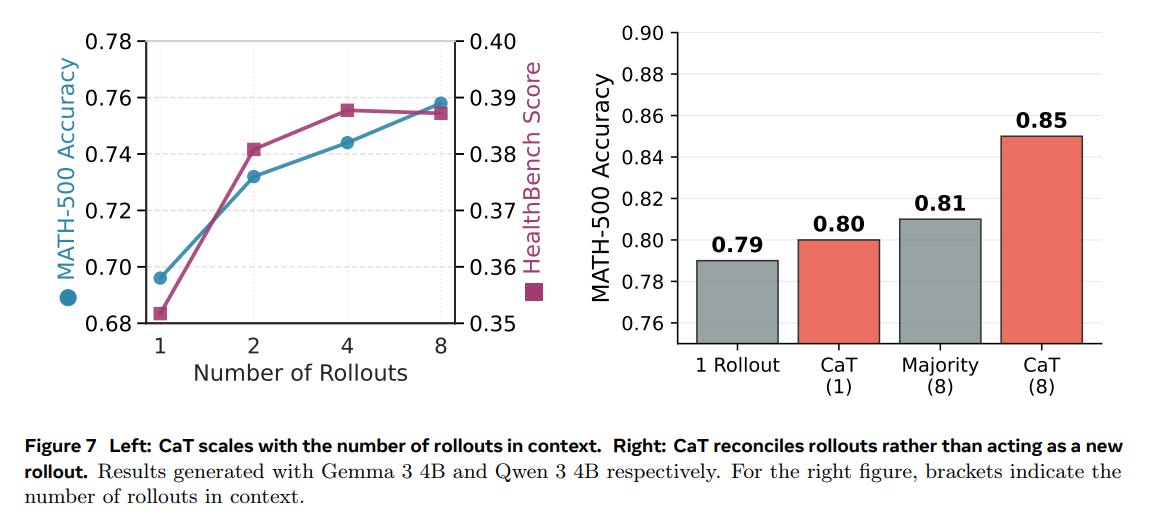
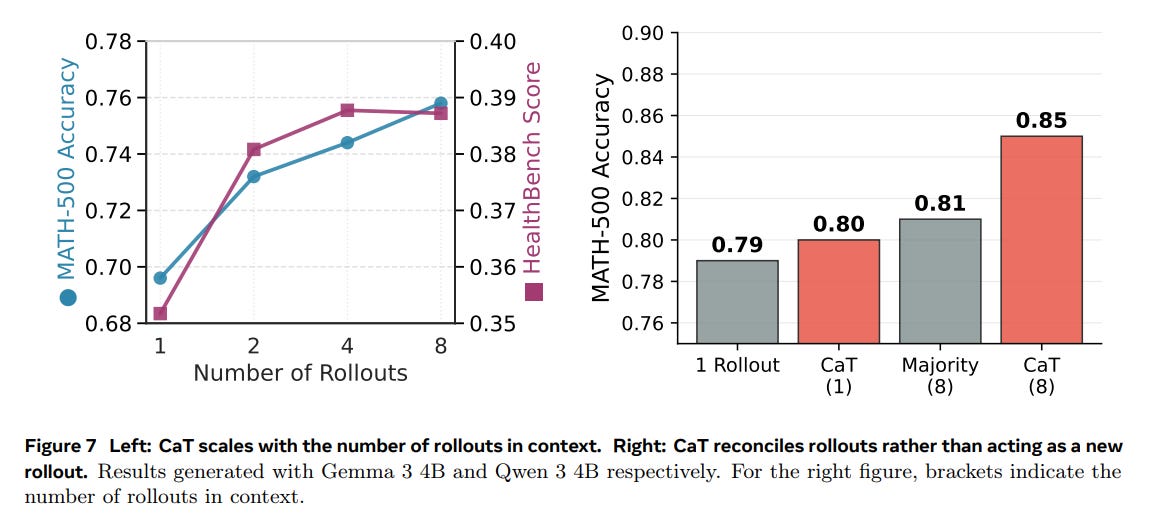
Scalability: Performance scales positively with the number of rollouts (G), confirming the practical trade-off of using more inference compute to generate better supervision (Figure 7).

Limitations and Future Outlook
The authors transparently discuss the method’s limitations. CaT’s effectiveness depends on a reasonably capable initial policy, as a weak anchor cannot reliably synthesize high-quality references. Additionally, the improvement eventually plateaus. As the policy becomes more proficient, its rollouts become less diverse, starving the synthesis step of the disagreements and contradictions it needs to generate a superior signal.
Future work aims to address this by promoting rollout diversity through exploration rewards, extending synthesis to intermediate reasoning traces, and integrating self-proposed questions to create a fully data-independent training loop.
Conclusion
“Compute as Teacher” presents a significant and well-executed contribution to the field of LLM training. By shifting the paradigm from selecting the best available answer to synthesizing a new, superior one, the paper demonstrates a powerful mechanism for self-correction and improvement. The introduction of self-proposed rubrics provides a practical and robust solution for training models in subjective, non-verifiable domains where supervision has traditionally been a major bottleneck.
This work offers a valuable framework that turns a computational cost—inference—into a high-quality asset—supervision. It suggests a promising path toward more autonomous models that can bootstrap their own capabilities, pushing beyond the limits of human-curated data.