
Continuous Autoregressive Language Models
Authors: Chenze Shao, Darren Li, Fandong Meng, Jie Zhou
Paper: https://arxiv.org/abs/2510.27688
Code: https://github.com/shaochenze/calm
Project: https://shaochenze.github.io/blog/2025/CALM
TL;DR
WHAT was done? The paper introduces Continuous Autoregressive Language Models (CALM), a new paradigm that shifts LLM generation from sequential, discrete next-token prediction to continuous next-vector prediction. This is achieved by using a robust, high-fidelity variational autoencoder to compress a chunk of K tokens into a single continuous vector, thereby reducing the number of autoregressive steps K-fold. The shift to a continuous domain required the development of a comprehensive likelihood-free toolkit, including: an Energy Transformer head for efficient, single-step vector generation; a novel evaluation metric, BrierLM, based on the strictly proper Brier score; and a principled, black-box algorithm for temperature sampling.
WHY it matters? This work directly confronts the fundamental computational bottleneck of LLMs: their inefficient, token-by-token generation process. By increasing the “semantic bandwidth” of each generative step, CALM establishes a new and highly effective scaling axis for language models. Experiments show this approach yields a superior performance-compute trade-off; for instance, a CALM model achieves the performance of a strong discrete baseline with 44% fewer training FLOPs and 34% fewer inference FLOPs. This establishes next-vector prediction as a powerful and scalable pathway towards building ultra-efficient language models, moving beyond the traditional scaling laws focused solely on parameters and data.

Details
The Inefficiency of One Token at a Time
Large Language Models (LLMs) have demonstrated remarkable capabilities, but their success is shadowed by a critical flaw: immense computational inefficiency. At the heart of this inefficiency lies the autoregressive, token-by-token generation process. Each step predicts a single, low-information discrete token, forcing powerful models to laboriously construct responses one piece at a time. While the field has scaled model parameters to astronomical levels, the fundamental task—predicting the next 15-18 bits of information—has not evolved.
This paper challenges this paradigm with Continuous Autoregressive Language Models (CALM), a framework that proposes a new axis for LLM scaling: increasing the semantic bandwidth of each generative step. Instead of predicting the next token, CALM predicts the next vector, where each vector represents a whole chunk of K tokens. This reduces the number of required generative steps by a factor of K, fundamentally improving computational efficiency (Figure 1).
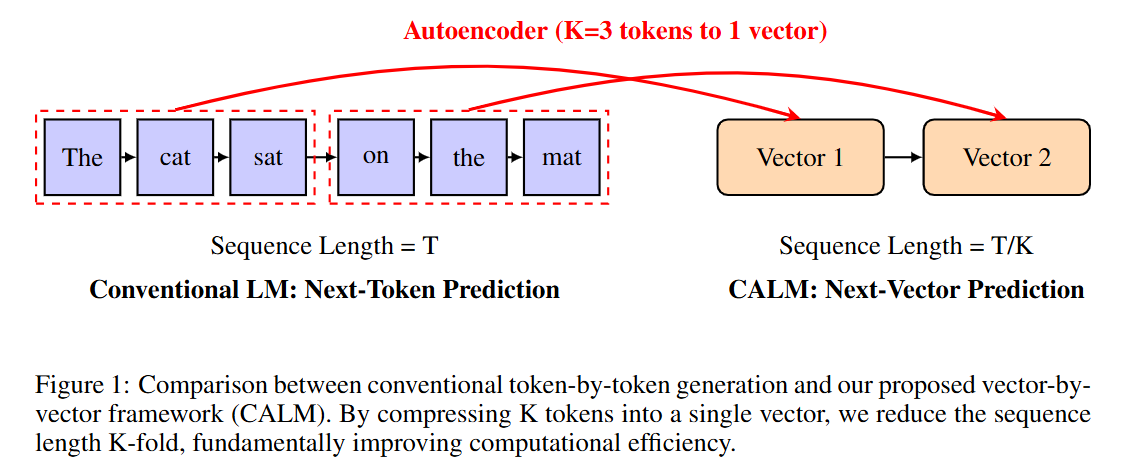
If traditional LLM scaling is like writing a novel with a typewriter by placing one character at a time, CALM is like upgrading to a word processor where each generative step places an entire phrase. However, moving from a finite vocabulary of discrete tokens to an infinite space of continuous vectors is non-trivial and requires a complete rethinking of the modeling toolkit.
A related approach targeted at reasoning in latent space was explored in the Chain Of Continuous Thought (Coconut) paper. It is strange, the authors didn’t mention that paper.

Keep reading with a 7-day free trial
Subscribe to ArXivIQ to keep reading this post and get 7 days of free access to the full post archives.