
Controlling the "Thought" Process
AlphaOne Teaches Large Reasoning Models When to Think Slow and Fast
AlphaOne: Reasoning Models Thinking Slow and Fast at Test Time
Authors: Junyu Zhang, Runpei Dong, Haoran Geng, Peihao Li, Jitendra Malik, Saurabh Gupta, Han Wang, Xialin He, Xuying Ning, Yutong Bai, Huan Zhang
Paper: https://arxiv.org/abs/2505.24863
Code: https://alphaone-project.github.io/
Model: Models used are open-source (DeepSeek-R1, Qwen QwQ series); AlphaOne itself is a framework.
TL;DR
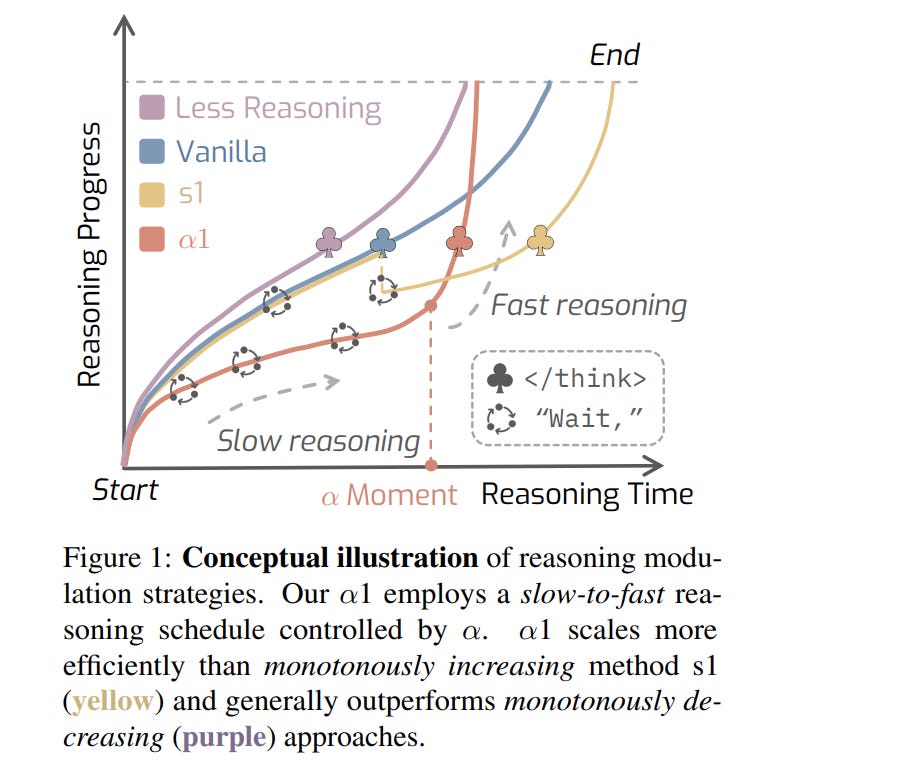
WHAT was done? The paper introduces AlphaOne (α1), a training-free framework that dynamically modulates the reasoning process of Large Reasoning Models (LRMs) at test time. It defines an "alpha moment" (α), which scales the LRM's average thinking phase token length (N_think) to set an overall thinking budget (αN_think). Before this moment, AlphaOne stochastically encourages "slow thinking" by inserting tokens like "wait,"; after this moment, it deterministically enforces "fast thinking" by replacing slow thinking tokens with an </think> token.
WHY it matters? LRMs often grapple with "overthinking" or "underthinking," which hinders their problem-solving efficacy. AlphaOne provides explicit, universal control to optimize the transition between deliberative and decisive reasoning. This innovative approach leads to significant improvements in accuracy across diverse benchmarks (math, code, science) while often enhancing computational efficiency by reducing token length. A key and surprising insight is that a "slow thinking first, then fast thinking" strategy, contrary to some human cognitive patterns, proves highly beneficial for LRMs.

Details
Large Reasoning Models (LRMs) have demonstrated remarkable capabilities, yet their test-time performance can be hampered by an inability to optimally manage their "thinking" pace, leading to either "overthinking" or "underthinking." The paper tackles the challenge of whether reasoning progress can be universally modulated to develop a better strategy for transitioning between slow, deliberate thought and fast, decisive action. The authors introduce AlphaOne (a1), a novel framework designed to provide this explicit control, enabling flexible and dense modulation of an LRM's reasoning from slow to fast.
Guiding LRM Deliberation: The AlphaOne Methodology
AlphaOne operates as a universal, training-free framework that orchestrates an LRM's reasoning process at test time. Its innovation lies in the introduction of an "alpha moment" (α), a parameter that scales the LRM's typical thinking phase budget (defined by its average thinking phase token length, N_think, to become αN_think), effectively defining the duration of intense deliberation.
The methodology unfolds in two distinct phases around this α moment, as illustrated in Figure 2:

Pre-
αMoment (Slow Thinking Modulation): Before reaching theαmoment, AlphaOne dynamically encourages slow, deliberative thinking. This is achieved by modeling the insertion of specific "reasoning transition tokens" (e.g., "wait,"), often appended after frequently co-occurring structural delimiters like\n\n, as a Bernoulli stochastic process. The probability of inserting these tokens,P_wait, is typically governed by a scheduling function, such as linear annealing, which gradually reducesP_waitover time.
This design choice facilitates a "slow thinking first, then fast thinking" pattern, found empirically to be highly effective. The rationale behind a stochastic process is likely to allow for more flexible and dense modulation compared to fixed insertion rules.
Post-
αMoment (Fast Thinking Enforcement): Once the token generation reaches theαmoment, AlphaOne deterministically shifts the LRM into a fast-thinking mode. Any subsequent attempt by the LRM to generate a slow thinking token is intercepted and replaced with an "end-of-thinking" token (e.g.,</think>). This decisive intervention is crucial for overcoming "slow thinking inertia"—a tendency for LRMs to get stuck in deliberation—and promotes efficient answer generation.

This structured approach unifies and generalizes previous monotonic scaling methods, such as s1 (https://arxiv.org/abs/2501.19393, manual review is here) and Chain-of-Draft (CoD) (https://arxiv.org/abs/2502.18600), by jointly considering and controlling both the overall thinking budget (via α) and the detailed scheduling of reasoning transitions. The authors highlight that existing methods often neglected this joint optimization. The use of linear annealing for P_wait was an empirical choice, outperforming other strategies like constant or exponential scheduling. The deterministic termination post-α addresses a practical limitation observed in LRMs, making the transition to answer generation more robust. This part resembles ThoughtTerminator.
Experimental Validation: Performance and Efficiency Gains
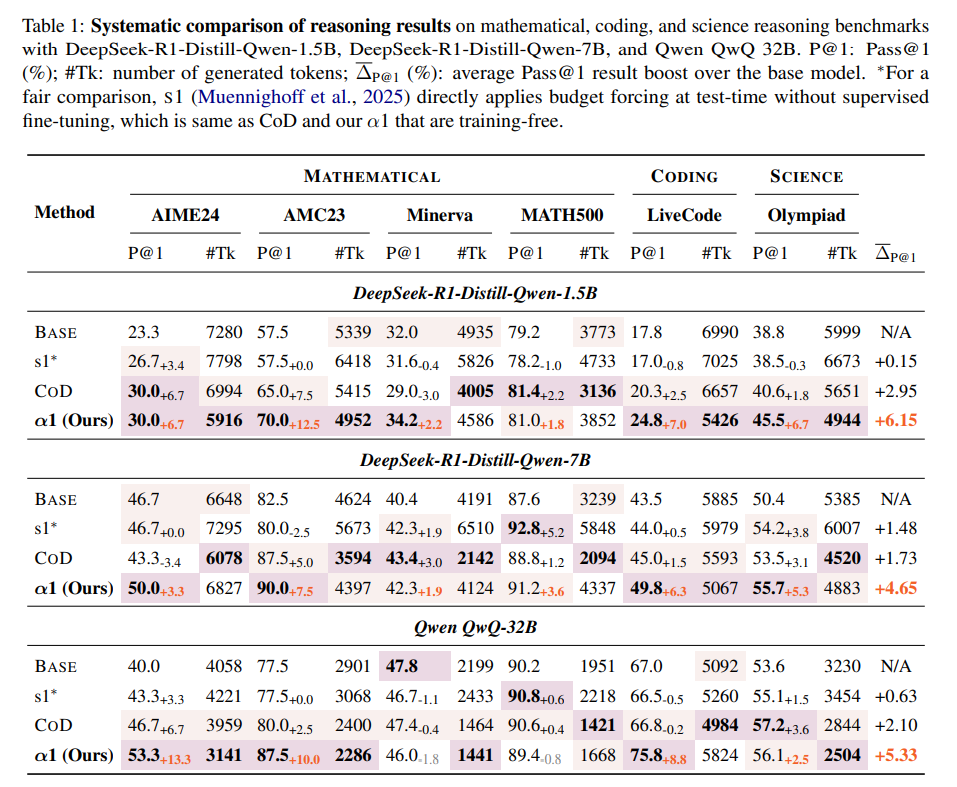
The authors conducted extensive experiments across mathematical reasoning (AIME 2024, AMC 2023, Minerva-Math, MATH500), code generation (LiveCodeBench), and scientific problems (OlympiadBench) using base models such as DeepSeek-R1-Distill-Qwen-1.5B, DeepSeek-R1-Distill-Qwen-7B (https://arxiv.org/abs/2501.12948, manual review is here), and Qwen QwQ 32B (https://qwenlm.github.io/blog/qwq-32b-preview/).
The results demonstrate AlphaOne's significant advantages:
Superior Accuracy: AlphaOne consistently outperformed baseline methods (BASE LRM,
s1, and CoD) in problem-solving accuracy (Pass@1). As detailed in Table 1, it improved the DeepSeek-R1-Distill-Qwen-1.5B model by a notable +6.15% on average, and achieved average accuracy boosts of +3.12% over CoD and +4.62% overs1.
Enhanced Efficiency: Beyond accuracy, AlphaOne also proved more efficient. For the 1.5B model, it reduced token length by nearly 14% compared to the base model. Its average thinking phase token length was only slightly higher (+4.4%) than the aggressively token-reducing CoD, and significantly more efficient (+21.0%) than
s1.Better Performance-Efficiency Balance: The proposed Reasoning Efficiency-Performance (REP) metric further highlighted AlphaOne's strengths, showing a more favorable balance between performance and efficiency on most benchmarks compared to baselines (Figure 6).


It is worth noting that while the performance gains are compelling, the paper does not report statistical significance measures like p-values or confidence intervals for these results. Ablation studies confirmed the importance of the post-α moment modulation (Table 2) and the efficacy of the linear annealing schedule for P_wait.

The sensitivity analysis on α (Figure 5) also showed its direct impact on scaling the thinking phase budget and performance.

Broader Implications and Future Horizons
The implications of AlphaOne extend beyond immediate performance gains. The research offers valuable insights into LRM behavior and charts promising future directions.
One of the most fascinating, and perhaps paradigm-shifting, takeaways is that LRMs, unlike humans, benefit most from a "slow thinking first, then fast thinking" strategy. This divergence from Kahneman's System 1 then System 2 model in human cognition (Kahneman, 2011) opens up exciting questions about the unique 'cognitive' pathways of AI and emphasizes the need for dedicated scaling strategies tailored to LRM behavior. This finding suggests that effective AI reasoning might require strategies distinct from direct human mimicry, opening new research avenues into LRM-native cognitive architectures.
Practically, AlphaOne's ability to enhance accuracy while improving, or at least competitively managing, token efficiency is crucial for deploying LRMs in real-world applications. More reliable and cost-effective problem-solving in complex domains becomes more feasible. The introduction of the α parameter provides a tunable knob for practitioners to balance reasoning depth against computational resources, tailoring LRM behavior to specific needs.
The authors identify several avenues for future work:
Developing more sophisticated slow thinking scheduling mechanisms, potentially learning modulation strategies or integrating them into model training.
Creating "transitioning-token-agnostic" modulation to improve generalizability across different LRMs, particularly those not of the
o1-style(https://arxiv.org/abs/2412.16720).Extending the AlphaOne framework to multimodal and embodied reasoning, where controlled deliberation is equally critical.
The success of AlphaOne may also influence future LRM design and training. For instance, models could be pre-trained or fine-tuned to be more receptive to such dynamic reasoning control, or even to internalize these strategic thinking phases.
Acknowledged Limitations
The authors transparently discuss several limitations of AlphaOne :
The framework is primarily designed for
o1-styleLRMs, where specific tokens like "wait" effectively trigger slow thinking. Its applicability to future LRMs with different internal mechanisms for thought transition is an open question.AlphaOne relies on an empirically determined average thinking phase token length (
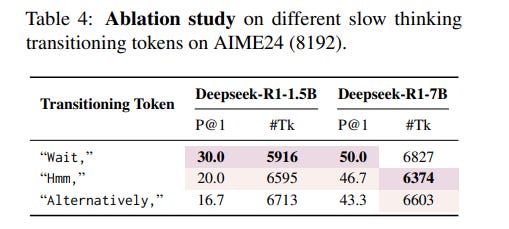
N_think) to set theαmoment. This estimation requires a small pre-run on sample questions, incurring a marginal cost and potentially being suboptimal if representative samples are unavailable.The choice of the "slow thinking transition token" (e.g., "Wait," vs. "Hmm") can impact performance, as shown in Table 4, indicating some model-specific sensitivity.

While linear annealing proved effective, the paper acknowledges that optimal scheduling for diverse tasks remains an area for further research, and some strategies like exponential anneal showed less stable performance boosts.
An additional consideration is that while α offers scalability, finding the universally optimal α across all tasks, models, and complexities may still require careful tuning.
Concluding Thoughts
AlphaOne presents a significant step forward in controlling and optimizing the reasoning processes of Large Reasoning Models at test time. By introducing a universal framework for modulating slow-to-fast thinking transitions, the paper demonstrates a practical and effective method to enhance both the accuracy and efficiency of LRMs on complex tasks. The insights into LRM-specific reasoning strategies, particularly the "slow first, then fast" paradigm, are valuable for the broader AI research community.
This paper offers a valuable contribution to the field. Its principled approach to test-time reasoning modulation, supported by comprehensive empirical evidence, provides a strong foundation for future advancements in developing more intelligent, controllable, and efficient AI systems. While further research is needed to address current limitations and explore more sophisticated scheduling, AlphaOne marks a compelling advancement in our ability to guide how LRMs "think."