
CoT-Self-Instruct: Building high-quality synthetic prompts for reasoning and non-reasoning tasks
Authors: Ping Yu, Jack Lanchantin, Tianlu Wang, Weizhe Yuan, Olga Golovneva, Ilia Kulikov, Sainbayar Sukhbaatar, Jason Weston, Jing Xu
Paper: https://arxiv.org/abs/2507.23751
TL;DR
WHAT was done? The paper introduces CoT-Self-Instruct, a two-stage pipeline for generating high-quality synthetic training data for LLMs. In the first stage, an LLM uses Chain-of-Thought (CoT) to reason about a small set of seed prompts and then generate a new, complex synthetic instruction. For reasoning tasks, this includes generating the answer as well. The second stage involves a rigorous curation process. For verifiable reasoning tasks, a novel "Answer-Consistency" filter is applied, which rejects prompts where the model's majority-voted answer doesn't match the self-generated one. For non-verifiable tasks, the Rejecting Instruction Preferences (RIP) method (https://arxiv.org/abs/2501.18578) is used to filter prompts based on reward model scores.
WHY it matters? This method is significant because the resulting synthetic data enables LLMs to achieve performance that surpasses models trained on existing high-quality, human-annotated datasets like s1k (https://arxiv.org/abs/2501.19393, review here) and OpenMathReasoning (https://arxiv.org/abs/2504.16891) for reasoning, and WildChat (https://arxiv.org/abs/2405.01470) for instruction following. It demonstrates that by instructing an LLM to reason about the data generation process and then self-curate the output, we can create a more effective training curriculum than what is often produced by humans. This work represents a major step towards data-centric AI and more autonomous, self-improving LLMs, reducing the dependency on expensive and potentially biased manual data annotation.

Details
The pursuit of more capable Large Language Models (LLMs) has an insatiable appetite for high-quality data. However, reliance on human-annotated data is a well-known bottleneck, fraught with high costs, scarcity, and potential for human error and bias. The "Self-Instruct" paradigm, where LLMs generate their own training data, offered a promising alternative. A new paper from researchers at FAIR and NYU pushes this paradigm a significant step forward, demonstrating a method that not only generates synthetic data but crafts it with such quality that it consistently outperforms human-sourced training sets.
The CoT-Self-Instruct Method
The proposed framework, CoT-Self-Instruct, is a sophisticated two-stage pipeline designed to generate and refine synthetic prompts for both reasoning and general instruction-following tasks.
Stage 1: Generation through Reasoning
The key innovation of CoT-Self-Instruct lies in its first stage. Instead of simply prompting an LLM to generate more examples similar to a few seeds, the method instructs the LLM to first engage in a Chain-of-Thought (CoT) process. The model is prompted to analyze the provided seed prompts, reflect on what makes them high-quality, and formulate a plan before generating a new, self-contained instruction (Figure 1).
For verifiable reasoning tasks, the LLM is guided by a specific template (Figure 2) to create a novel and challenging question, reason through its solution, and output both the question and its final, verifiable answer.

For general instruction-following tasks, the model analyzes common elements in the seed prompts to create a plan and then generates a new prompt that is creative and domain-appropriate (Figure 3).



This "thinking before writing" approach is designed to produce synthetic prompts of higher complexity and quality than standard self-instruction methods.
Stage 2: Curation through Self-Filtering
Recognizing that not all synthetic data is created equal, the second stage is a crucial filtering step to retain only the best examples.
For verifiable reasoning tasks, the authors introduce a novel filter called Answer-Consistency. After a prompt and its CoT-generated answer are created, the LLM is asked to solve the prompt again multiple times (
Ktimes). What makes this filter particularly clever is that it compares answers generated via two different pathways. The initial "golden" answer is generated alongside the prompt using the detailed Chain-of-Thought process, while the subsequentKanswers for verification are generated at inference time. If the majority-voted answer from these new attempts does not match the original CoT-generated answer, the prompt is discarded. This acts as a powerful self-validation mechanism, filtering out prompts that are likely ill-posed, ambiguous, or too difficult for the model to solve consistently.For non-verifiable instruction-following tasks, the method employs the Rejecting Instruction Preferences (RIP) technique (https://arxiv.org/abs/2501.18578). In this setup,
Kresponses (e.g., 32) are generated for each synthetic prompt and scored by a reward model. The lowest score among these responses is taken as the representative quality score for that prompt. The dataset is then curated by keeping only the prompts with the highest scores, ensuring a final set that reliably elicits strong responses.
This dual process of reasoned generation and rigorous self-curation forms the core of the CoT-Self-Instruct framework.
Experimental Validation and Striking Results
The authors conducted a comprehensive set of experiments to validate their approach, training Qwen3-4B models on reasoning tasks and Llama 3.1-8B models on instruction-following tasks. The results are compelling.
Reasoning Tasks: On a suite of challenging reasoning benchmarks (MATH500, AMC23, AIME24, GPQA-Diamond), models trained on data from CoT-Self-Instruct significantly outperformed all baselines.
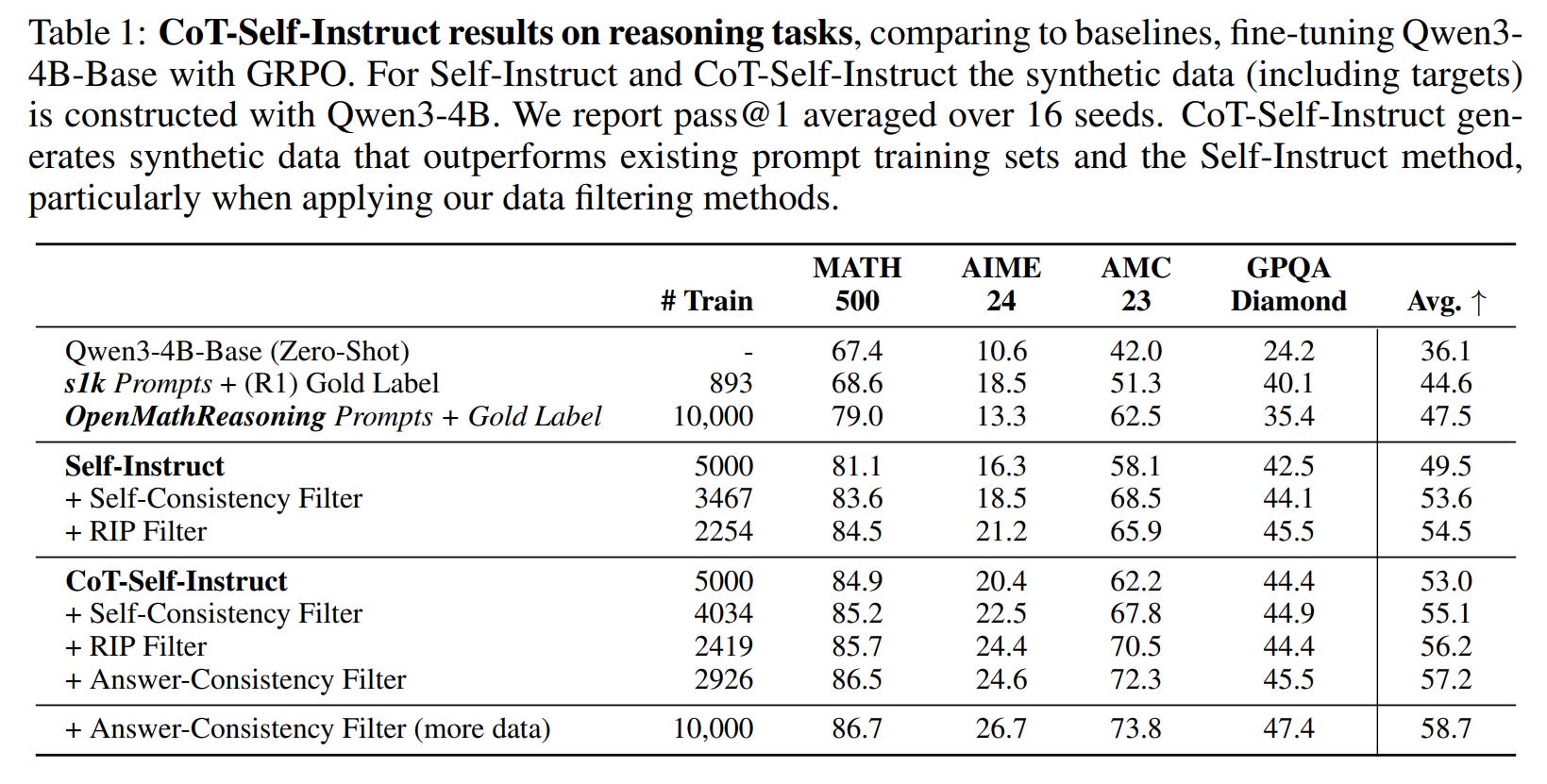
CoT-Self-Instruct vs. Human Data: The most striking result is the comparison with established human-annotated datasets. A model trained on just 2,926 prompts curated with Answer-Consistency achieved an average accuracy of 57.2%. This is substantially higher than models trained on 893 high-quality
s1kprompts (https://arxiv.org/abs/2501.19393, review) (44.6%) or even 10,000 prompts fromOpenMathReasoning(https://arxiv.org/abs/2504.16891) (47.5%) (Table 1).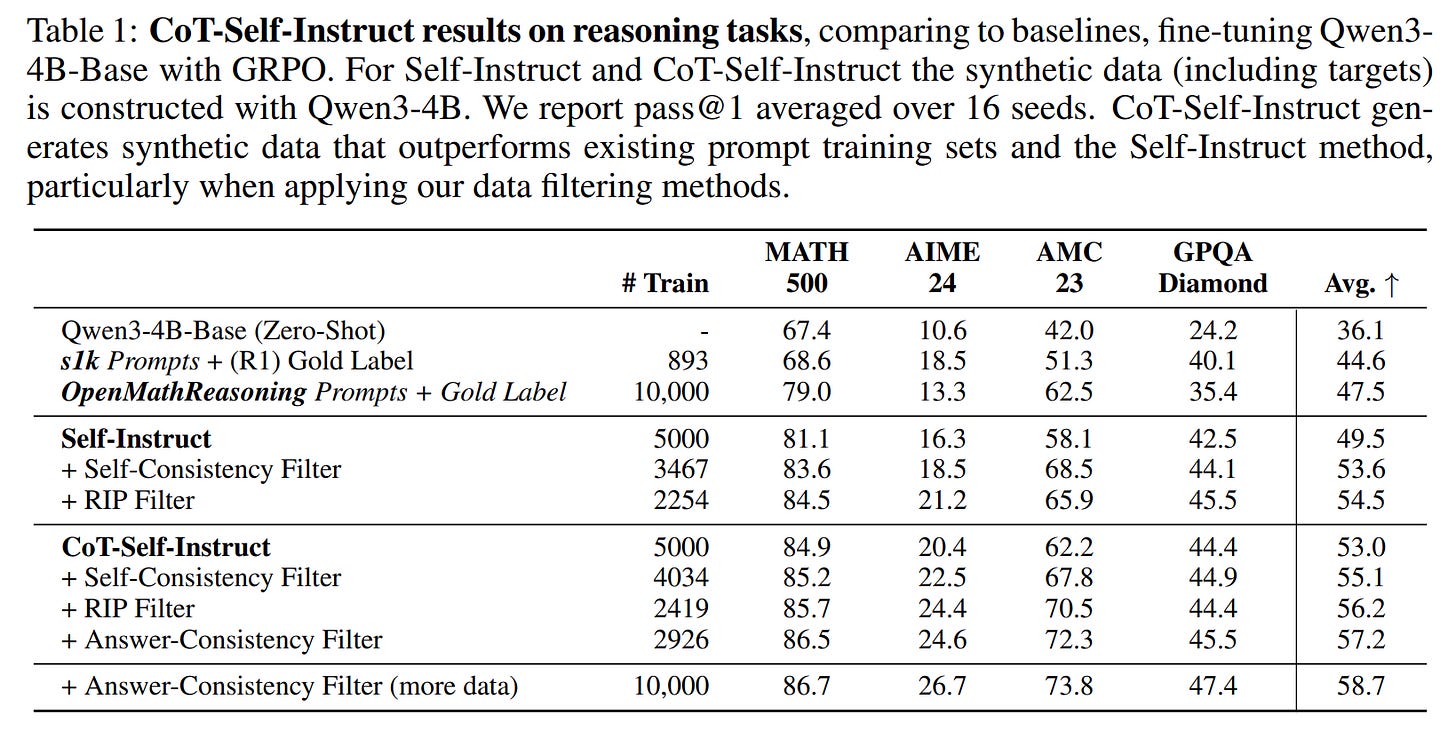
The Power of Filtering: Filtering proved crucial. Unfiltered CoT-Self-Instruct (53.0%) already beat unfiltered Self-Instruct (49.5%). However, applying the Answer-Consistency filter boosted performance to 57.2%, demonstrating that a smaller set of higher-quality data is more effective. When scaled to 10,000 filtered examples, the performance climbed further to 58.7%.
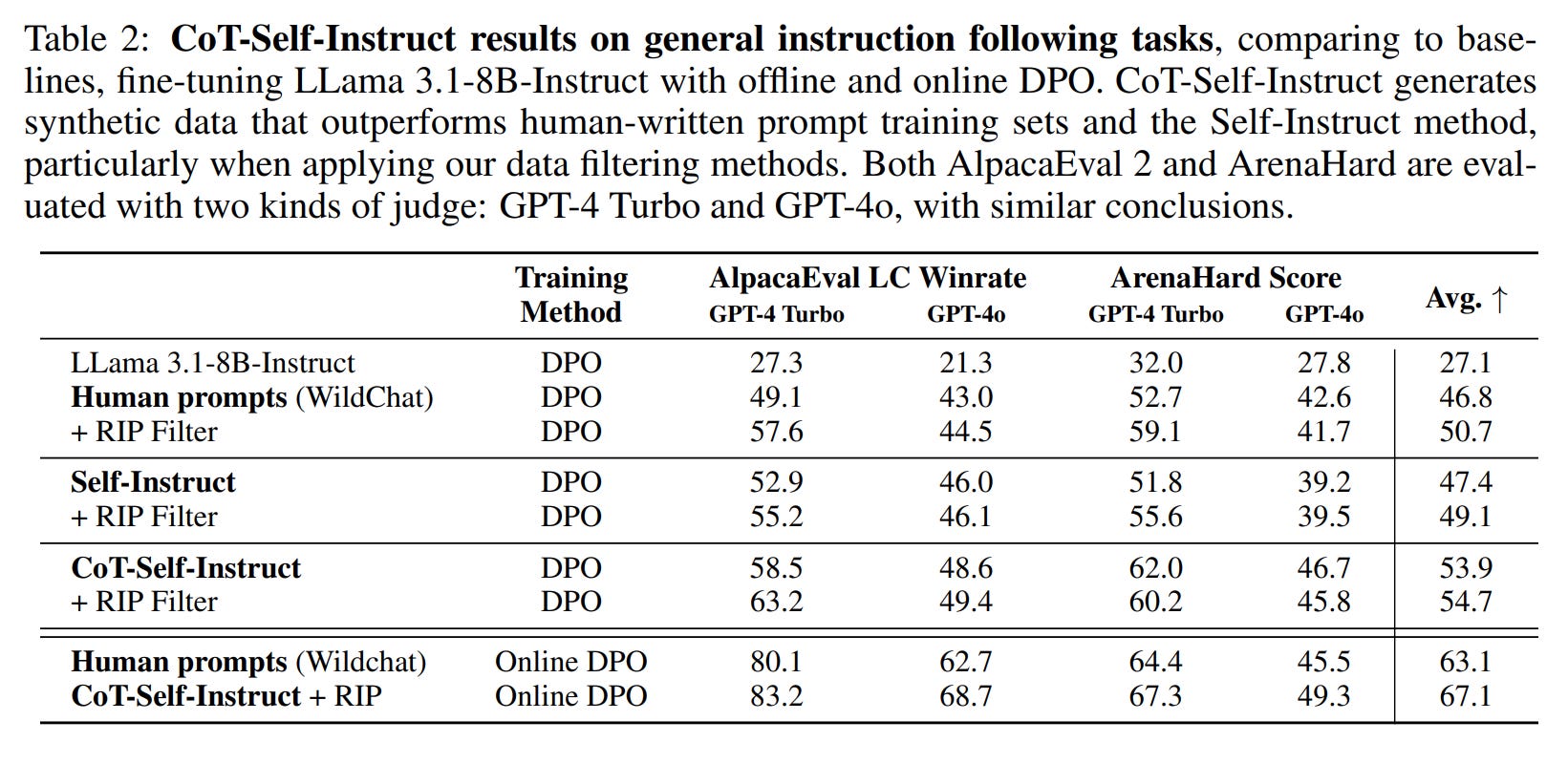
Instruction-Following Tasks: On non-verifiable tasks evaluated with AlpacaEval 2.0 and Arena-Hard, CoT-Self-Instruct again demonstrated its superiority.
A DPO-trained model using CoT-Self-Instruct data with RIP filtering achieved an average score of 54.7. This outperformed models trained on human prompts from
WildChat(https://arxiv.org/abs/2405.01470) (46.8%, or 50.7% with RIP filtering) and standard Self-Instruct (49.1% with RIP filtering) (Table 2).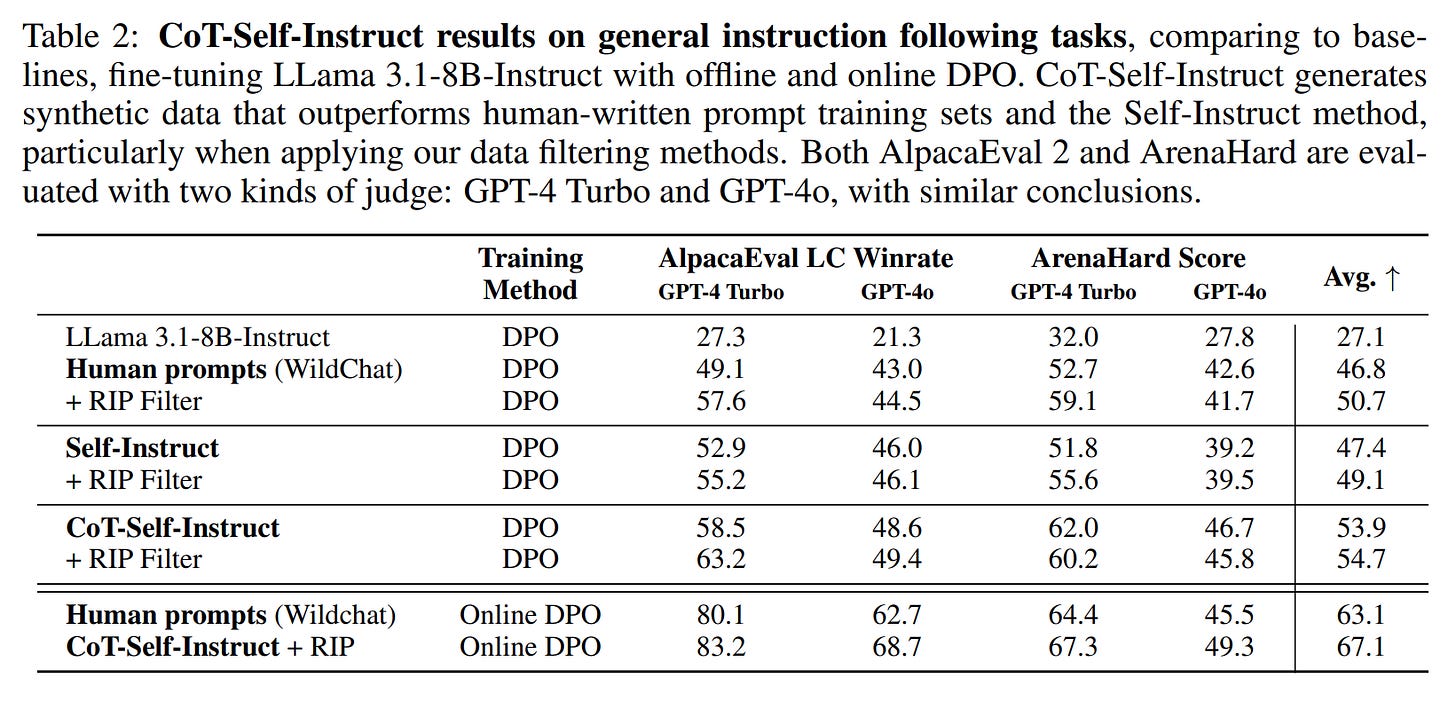
Even in an online DPO setup, CoT-Self-Instruct with RIP filtering (67.1) maintained its edge over human prompts (63.1).
These results consistently show that the combination of CoT-based generation and intelligent filtering produces a synthetic dataset that is not just a cheap alternative, but a superior one.
Implications and Future Outlook
The success of CoT-Self-Instruct is a compelling proof-of-concept for a new data generation paradigm. It reframes the role of human experts: instead of being laborers who manually annotate thousands of examples, they become architects who design the 'scaffolding'—the seed prompts and the generation/curation logic—for a more capable AI to then build the skyscraper of data. This work doesn't just show how to create better data; it points towards a more scalable and autonomous future for training state-of-the-art models.
While the method is powerful, it relies on the quality of the initial seed data and the reasoning capabilities of the generator LLM. The computational cost of the generation and filtering pipeline is also a practical consideration. Future work could explore ways to generate prompts that push beyond the complexity of the seed set and further optimize the efficiency of the curation process.
Conclusion
CoT-Self-Instruct presents a robust and highly effective framework for building superior synthetic datasets. By elegantly combining Chain-of-Thought reasoning for generation with intelligent self-filtering for curation, the authors have demonstrated a clear path to creating training data that surpasses even high-quality human annotations. This work is a valuable contribution, pushing the boundaries of what is possible with synthetic data and paving the way for more capable and autonomously self-improving language models.