
Authors: Dmitry Guskov, Vitaly Vanchurin
Paper: https://arxiv.org/abs/2504.05279
TL;DR
WHAT was done? The authors introduce Covariant Gradient Descent (CGD), a new optimization framework that unifies popular gradient-based methods like SGD, RMSProp, and Adam into a single, cohesive structure. The core idea is to define the optimization dynamics using a "covariant force vector" and a "covariant metric tensor." These are constructed from the first and second statistical moments of the gradients, estimated efficiently using exponential moving averages. This formulation ensures that the optimization process is consistent across different parameterizations and can naturally handle the curved geometry of high-dimensional loss landscapes. The paper demonstrates that leveraging the full covariance matrix of gradients—not just the diagonal elements used by existing methods—leads to a more accurate representation of this geometry.
WHY it matters? This work shifts the paradigm of optimizer design from a collection of effective but disconnected heuristics to a principled, unified theory grounded in geometry. It reveals that popular optimizers are essentially simplified versions of a more general dynamic, often discarding valuable information about gradient correlations. The experimental results show that by incorporating this richer geometric information (via the full covariance matrix), the proposed "full CGD" optimizer achieves faster, more stable convergence and a lower final loss than its predecessors on benchmark tasks. While computational scalability remains a challenge for large models, CGD provides a powerful theoretical lens and a clear path toward developing the next generation of more efficient and robust optimization algorithms.

Details
The field of deep learning optimization is dominated by a handful of highly effective, adaptive algorithms like Adam and its variants. While these methods have been instrumental in training massive neural networks, their development has often felt more like a series of clever engineering hacks than a progression guided by a unifying theory. A new paper proposes to change that by introducing a framework that places these optimizers on a solid geometric and statistical foundation.
The Core Idea: Covariant Gradient Descent
The central contribution of the paper is the formulation of Covariant Gradient Descent (CGD). The authors build their framework on a formal definition of a neural network involving three interacting spaces: a dataset space D, a non-trainable neuron space X, and a trainable parameter space Q. The optimization dynamics unfold within this trainable space Q.
The authors generalize the standard gradient descent update rule to a "manifestly covariant" form. This is a crucial property, as it addresses the "reparameterization problem": the performance of a standard optimizer can change dramatically if we reparameterize a model (e.g., by scaling the weights of one layer and inversely scaling the next), even if the underlying function remains identical. A covariant method is immune to such arbitrary choices because it adapts to the intrinsic geometry of the parameter space.
The core CGD equation is:

This equation describes the change in trainable parameters qμ over time. Let's break down its components:
γ is the learning rate.
F_ν(t) is the covariant force vector, representing the effective direction of the update. It is constructed from the first statistical moment of the gradients (i.e., an exponential moving average).
gμν(t) is the inverse metric tensor, a crucial element that adapts the update step to the local geometry of the loss landscape. It acts as a preconditioning matrix, stretching and rotating the update vector to navigate curved spaces more effectively. It is constructed from the second statistical moment of the gradients.
This approach places CGD in the family of natural gradient methods, which use a metric tensor to precondition updates. However, CGD distinguishes itself by constructing the metric tensor directly from the observed statistics of the gradients during training, rather than a predefined measure like the Fisher Information Matrix.
Both moments are estimated efficiently using exponential moving averages, which allows the method to maintain linear computational complexity by avoiding the storage of historical gradients.
Unifying the Optimizer Zoo
One of the most elegant aspects of the CGD framework is its ability to unify existing optimizers. The authors demonstrate that popular methods are simply special cases of CGD, corresponding to specific choices for the metric tensor and averaging timescales:
SGD: Uses a simple identity matrix for the metric tensor and no momentum (a timescale parameters τ_1=0).
RMSProp: Uses a diagonal metric tensor derived from the second moment of the gradients and has no momentum (τ_1=0).
Adam (https://arxiv.org/abs/1412.6980): Also uses a diagonal metric derived from the second moment but incorporates momentum (τ_1>0).
AdaBelief (https://arxiv.org/abs/2010.07468): Uses a diagonal metric derived from the variance of the gradients (M(2)−(M(1))2).
This unification provides a powerful lens through which to understand the relationships and implicit assumptions of these methods—most notably, their reliance on a diagonal metric tensor, which treats parameter updates as independent and ignores their correlations.
The Key Improvement: Leveraging the Full Covariance
The real power of the CGD framework is unlocked when it moves beyond the diagonal approximation. The authors propose a "full CGD" variant where the metric tensor is constructed from the full covariance matrix of the gradients:
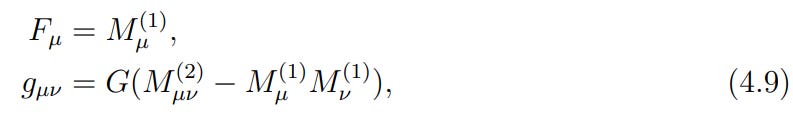
Here, G(⋅) is a function that maps the covariance matrix to the metric. For the experiments, a power-law form was used:
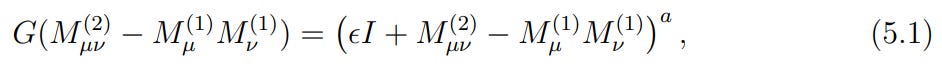
By including the off-diagonal elements, the metric tensor now captures the rich correlational structure between gradient components, providing a far more accurate picture of the loss landscape's local geometry.
Experimental Validation
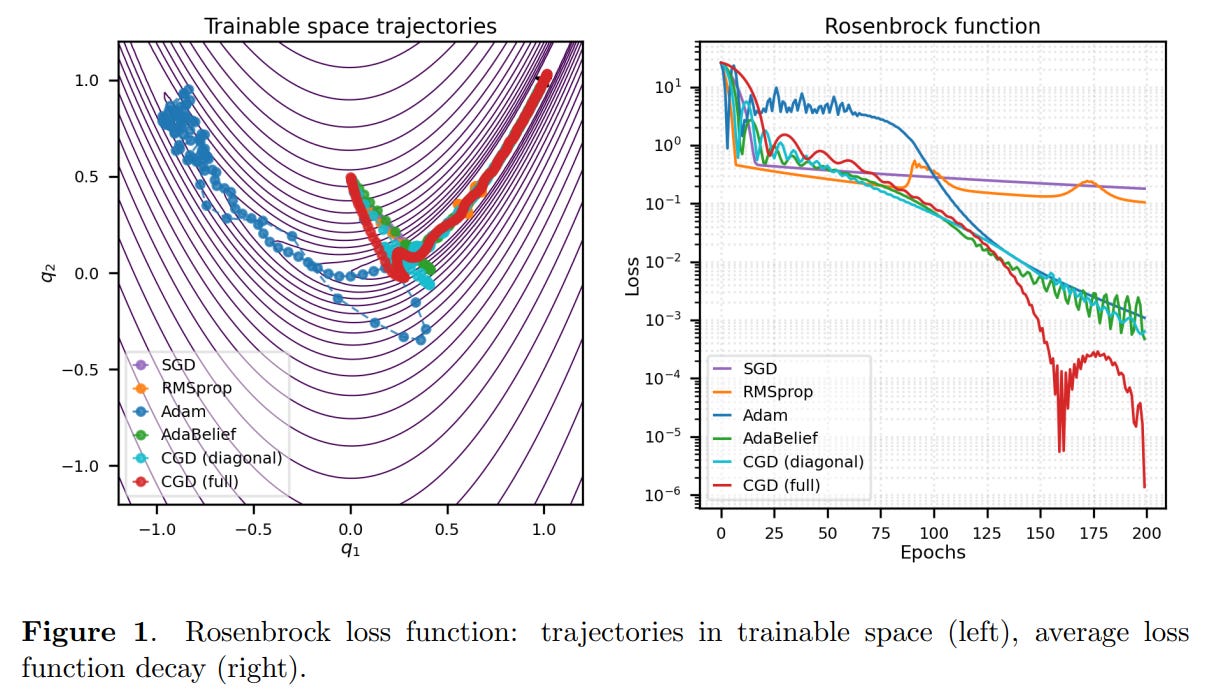
The authors test CGD (both diagonal and full versions) against SGD, RMSProp, Adam, and AdaBelief on two benchmark tasks: optimizing the Rosenbrock function and training a small neural network to perform multiplication.
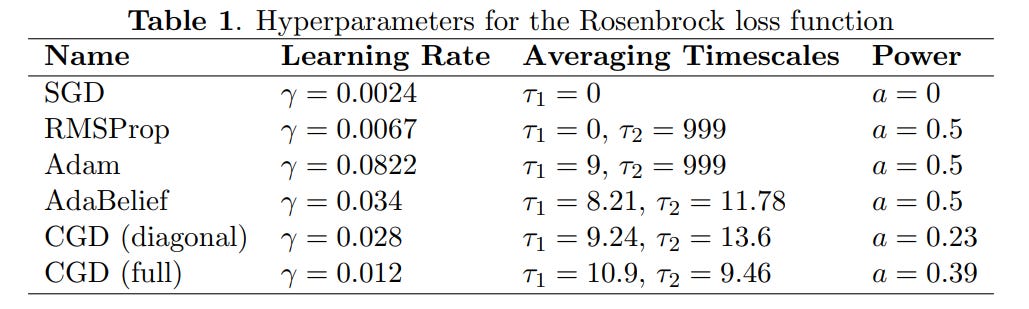
The hyperparameters for all methods were carefully tuned using Optuna (Table 1, Table 2).
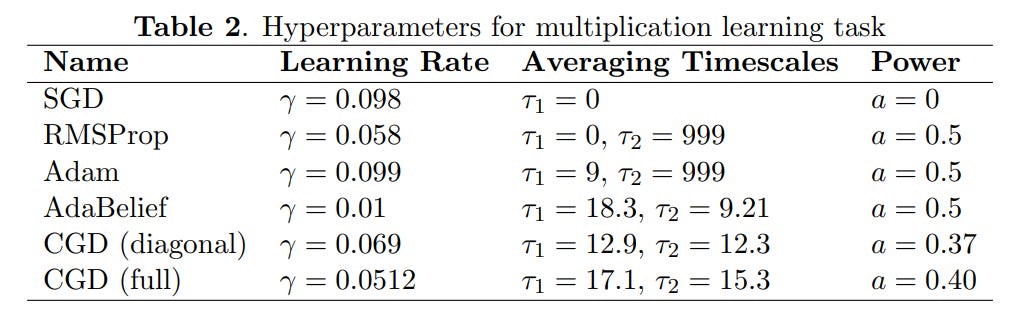
The results are compelling. On both tasks, the CGD methods performed exceptionally well. In the multiplication task, the "full CGD" optimizer, which leverages the complete covariance matrix, achieved the lowest final loss with rapid and stable convergence, outperforming all other methods (Figure 2). This provides strong evidence that the information contained in the off-diagonal elements of the covariance matrix is not just theoretically interesting but practically valuable for achieving better optimization performance.
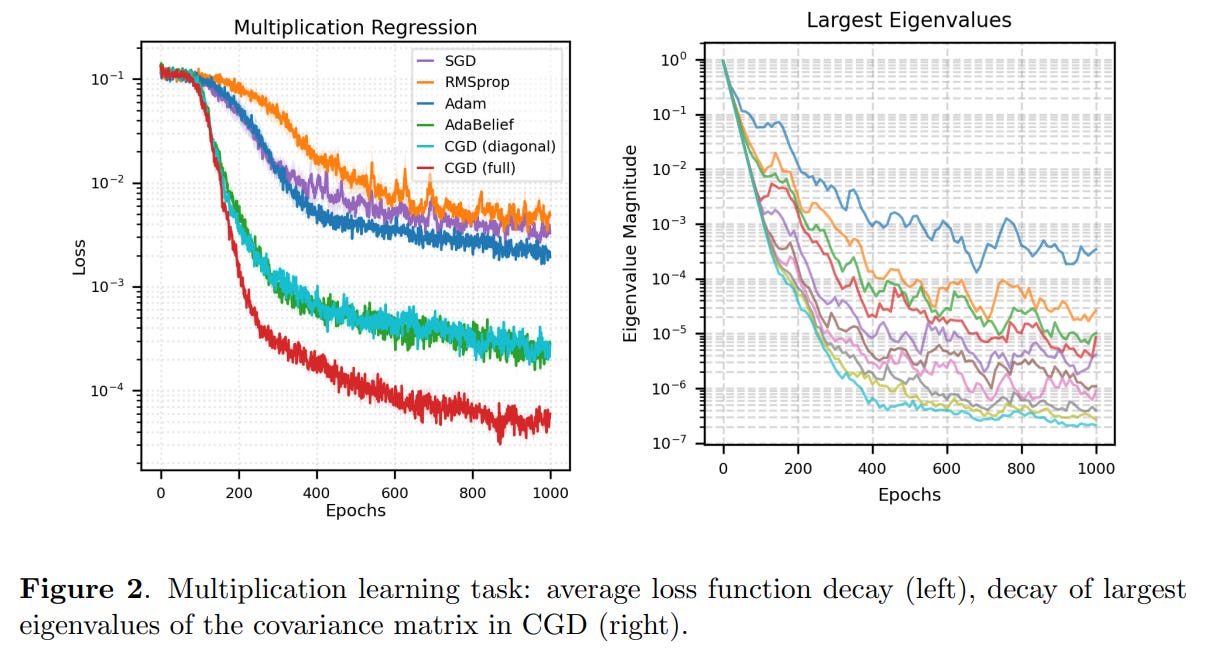
Furthermore, an analysis of the eigenvalues of the full covariance matrix during training revealed a steady decay over time. This suggests that the CGD optimizer learns to concentrate its updates within an effectively lower-dimensional subspace as training progresses, a fascinating insight into the dynamics of learning in high-dimensional spaces.
Limitations and Future Outlook
The primary limitation of the "full CGD" approach, as the authors acknowledge, is computational cost. Computing and inverting a full covariance matrix is intractable for models with millions or billions of parameters. This is the most significant hurdle to its widespread adoption. However, this work lays a clear and promising path for future research into efficient, scalable approximations, such as low-rank representations of the metric tensor.
Beyond the immediate applications in deep learning, the authors propose a truly mind-bending perspective. They suggest that the principles of CGD, where a curved geometry emerges from the statistical behavior of underlying components, might mirror how spacetime itself emerges in physics. This connects their work to ambitious theories like the "world as a neural network" (https://arxiv.org/abs/2008.01540) and the "autodidactic universe" (https://arxiv.org/abs/2104.03902), where the laws of physics are not fixed but are themselves the result of a learning process. While highly speculative, this vision elevates the paper from a mere improvement in optimization to a profound inquiry into the connections between learning, information, and physical reality.
In conclusion, this paper offers a significant contribution to our understanding of optimization. It provides a beautiful and rigorous unification of existing methods and introduces a principled way to generalize and improve them. By shifting the focus toward the rich, dynamic geometry of the learning process, Covariant Gradient Descent opens up exciting new avenues for designing the next generation of optimizers for deep learning.