CUDA Agent: Large-Scale Agentic RL for High-Performance CUDA Kernel Generation
Authors: Weinan Dai, Hanlin Wu, Qiying Yu, Huan-ang Gao, Jiahao Li, Chengquan Jiang, Weiqiang Lou, Yufan Song, Hongli Yu, Jiaze Chen, Wei-Ying Ma, Ya-Qin Zhang, Jingjing Liu, Mingxuan Wang, Xin Liu, Hao Zhou
Paper: https://arxiv.org/abs/2602.24286
Code: https://cuda-agent.github.io/
TL;DR
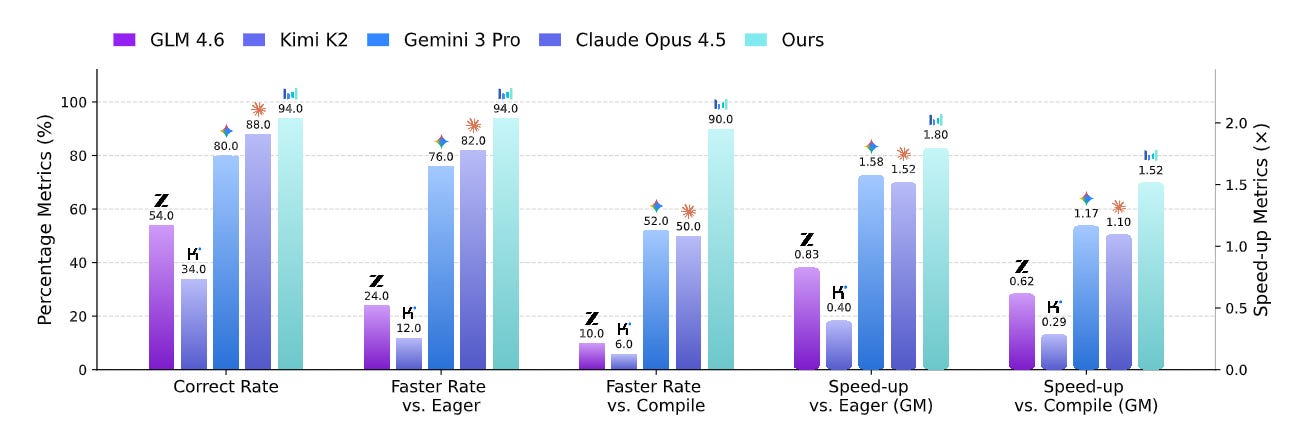
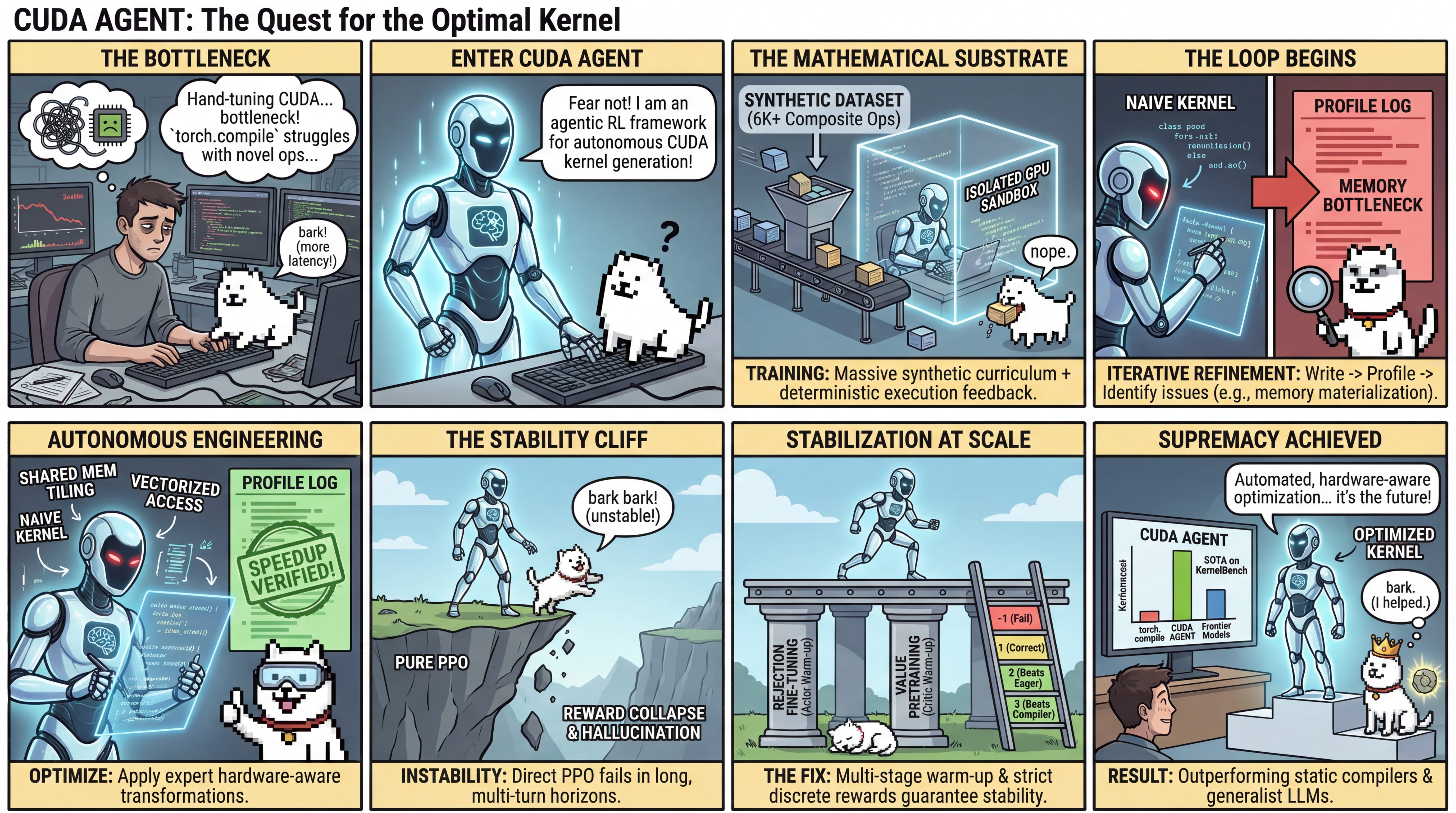
WHAT was done? Researchers from ByteDance and Tsinghua University introduced a reinforcement learning framework that trains a Large Language Model (LLM) agent to autonomously write, profile, and optimize low-level CUDA kernels. Supported by a novel synthetic dataset of over 6,000 composite PyTorch operators and a highly isolated execution sandbox, the system leverages Proximal Policy Optimization (PPO) alongside targeted pretraining strategies to stabilize multi-turn agentic learning.
WHY it matters? Hand-optimizing GPU kernels is a notoriously difficult, specialized skill that limits the rapid deployment of novel neural network architectures. By proving that an agentic RL system can consistently discover custom memory access patterns and hardware-specific operator fusions, this work successfully beats static compiler heuristics like torch.compile and outperforms generalist frontier models, pointing toward a future where hardware-aware performance engineering is fully automated.
Details
The Compiler Heuristics Bottleneck
GPU kernel optimization is the invisible engine powering modern deep learning infrastructure. However, extracting maximum theoretical bandwidth and compute from NVIDIA hardware requires intricate knowledge of memory coalescing, shared memory tiling, and register allocation. While compilers like torch.compile provide an excellent baseline via static analysis and rule-based operator fusion, they often fail to find the globally optimal hardware mapping for novel or highly complex operator graphs. Conversely, while frontier LLMs exhibit substantial reasoning capabilities, their intrinsic grasp of low-level CUDA semantics remains shallow. Existing LLM-based approaches either rely on training-free refinement workflows that are capped by the base model’s zero-shot limitations, or they attempt to fine-tune on limited datasets using multi-turn feedback loops that waste context windows and restrict autonomous debugging. The core conflict in the field is thus a data and stability bottleneck: how do we generate enough high-quality training signals to teach an LLM the iterative, experimental nature of performance engineering without causing the policy to collapse?