
DMax: Aggressive Parallel Decoding for dLLMs
Authors: Zigeng Chen, Gongfan Fang, Xinyin Ma, Ruonan Yu, Xinchao Wang
Paper: https://arxiv.org/abs/2604.08302
Code: https://github.com/czg1225/DMax
TL;DR
WHAT was done? The authors introduce DMax, a novel training and inference framework designed to unlock aggressive decoding parallelism in Diffusion Language Models (dLLMs). It mitigates the cascading error accumulation that typical parallel decoding methods suffer from by reformulating the standard binary mask-to-token transition into a self-revising continuous trajectory in the embedding space. This is achieved via two core techniques: On-Policy Uniform Training (OPUT), which trains the model on its own predictive distribution to learn self-correction, and Soft Parallel Decoding (SPD), which represents intermediate decoding states as a probability-weighted interpolation between predicted tokens and mask embeddings.
WHY it matters? While non-autoregressive parallel decoding has promised massive throughput improvements, existing masked diffusion models suffer severe generation quality collapse when forced to decode aggressively due to irreversible early errors. DMax successfully bridges this speed-accuracy gap. Applying DMax to the state-of-the-art LLaDA-2.0-mini baseline yields more than a 2.5× improvement in speed (tokens-per-forward) on complex reasoning (GSM8K) and coding (MBPP) benchmarks with negligible accuracy degradation, achieving over 1,300 tokens per second (TPS) on dual H200 GPUs.
Details
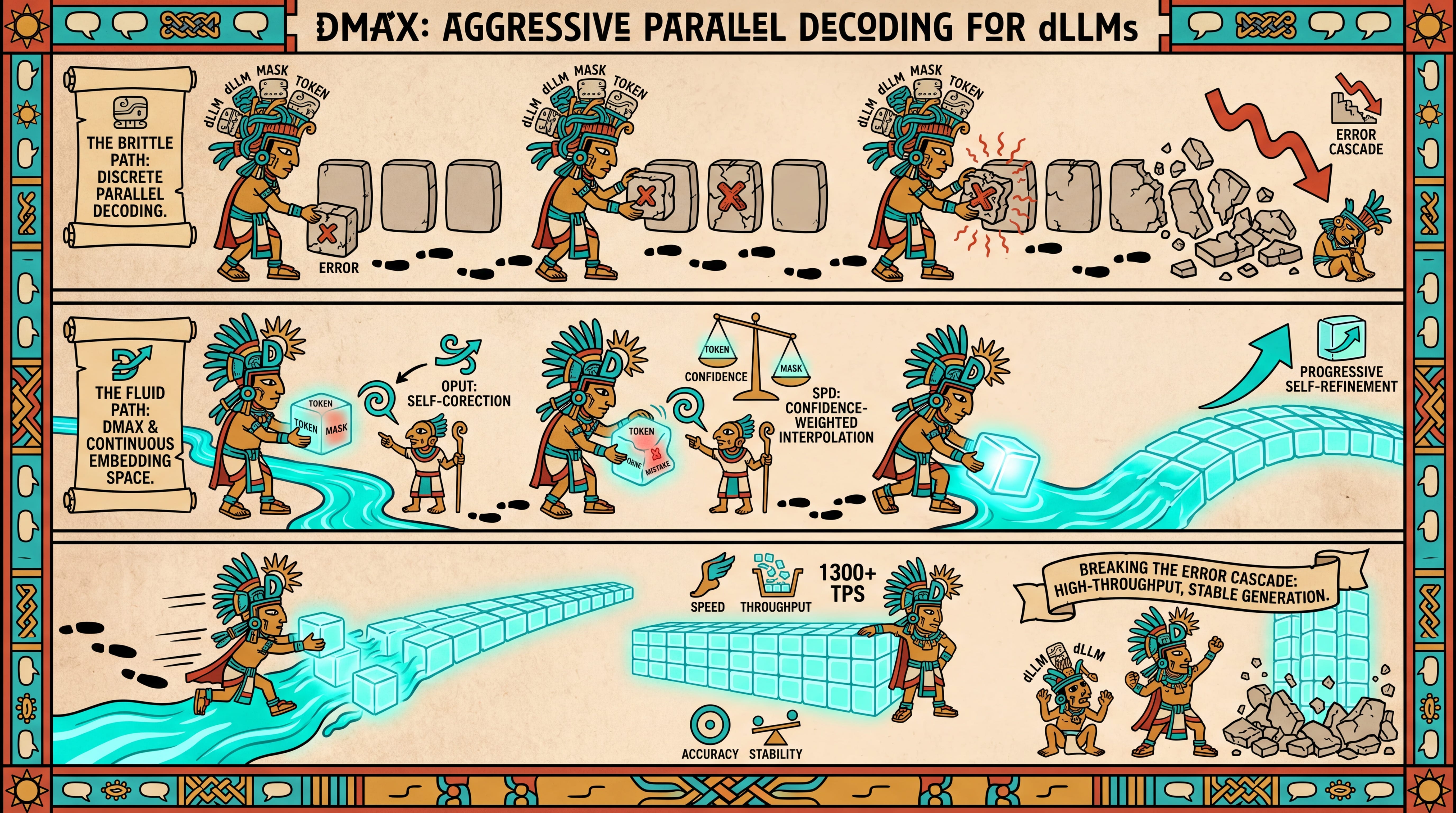
The Error Accumulation Bottleneck in Discrete Parallel Generation
Discrete Diffusion Language Models (dLLMs), such as Masked Diffusion Language Models (MDLMs), have surfaced as a highly compelling alternative to traditional Autoregressive Large Language Models (AR-LLMs) due to their innate potential for parallel generation. Rather than generating text token-by-token from left to right, MDLMs decode sequences via an iterative, non-autoregressive denoising process starting from a fully masked sequence. However, as illustrated in the comparison in Figure 1, the practical utility of aggressive parallel decoding is heavily bottlenecked by error propagation. Under standard MDLM decoding schemes, the transition from a mask to a token is a binary, one-way commitment. Once a position is decoded into a discrete token, it is treated as fixed context for subsequent steps. Under aggressive parallel settings, the model inevitably makes erroneous early predictions. These incorrect tokens then contaminate the context for neighboring positions, triggering a cascade of errors that ultimately culminates in semantic collapse.

To resolve this issue, prior methods have attempted to optimize inference schedules or utilize post-training distillation, as seen in dParallel-SFT or Hierarchical Decoding. However, these approaches do not address the root architectural deficiency: standard dLLMs completely lack an intrinsic mechanism to revise their own previous outputs in the middle of a decoding trajectory. A promising theoretical alternative lies in Uniform Diffusion Language Models (UDLMs), which are trained to denoise arbitrary corrupted tokens from the vocabulary rather than a dedicated mask token. This allows UDLMs to re-evaluate and correct any position at each step. Yet, because standard UDLMs initialize generation from entirely random vocabulary tokens, their generation trajectories are highly unstable. DMax elegantly unifies the stability of MDLMs with the self-correcting flexibility of UDLMs, reformulating text generation as a continuous, self-revising process.
