
Do Transformers Need Three Projections? Systematic Study of QKV Variants
Authors: Ali Kayyam, Anusha Madan Gopal, M Anthony Lewis
Paper: https://arxiv.org/abs/2606.04032
Code: https://github.com/Brainchip-Inc/Do-Transformers-Need-3-Projections
Model: N/A
TL;DR
WHAT was done? The authors systematically evaluate Projective Sharing in self-attention, testing three constraints: shared query-key, shared key-value, and single projection. By merging Key and Value projections, the optimal variant eliminates the need to cache separate Value tensors, achieving a 50% KV cache memory reduction. Crucially, they show projection sharing is orthogonal and complementary to head-sharing methods like Grouped Query Attention (GQA) and Multi-Query Attention (MQA), enabling a compounding KV cache reduction of up to 96.9%.
WHY it matters? This work dismantles the long-held assumption that self-attention requires three fully independent projections. It provides a highly effective, mathematically grounded technique to alleviate the KV cache serving bottleneck—the primary barrier to long-context and edge-device LLM deployment. Crucially, these massive memory savings are achieved with negligible degradation in model quality (e.g., losing only 0.41% average downstream accuracy at 1.2B scale), offering a new Pareto frontier for efficient transformer architectures.
Details
The Redundancy Bottleneck in Autoregressive Serving
The memory footprint of the Key-Value (KV) cache is the primary bottleneck in scaling context windows and throughput for autoregressive language models. While conventional efficiency methods target head-sharing dimensions—such as Grouped Query Attention (GQA) or Multi-Query Attention (MQA)—they leave the fundamental tripartite Query-Key-Value (QKV) projection structure of Transformers untouched. This paper introduces “Projective Sharing,” demonstrating that maintaining three distinct linear projections per token is mathematically redundant. By imposing direct equality constraints on the projection matrices, this work establishes a significant delta from baseline head-sharing methods. Unlike DeepSeek-V2’s Multi-Head Latent Attention (MLA), which compresses states into a latent vector and subsequently decompresses them using additional projection matrices, the proposed approach enforces hard equality constraints like K=V directly during training, reducing the cache footprint without introducing parameter overhead for expansion.
First Principles of Projective Weight Tying
Mathematically, standard multi-head attention operates on an input tensor X∈Rn×d, where n represents the sequence length and d is the hidden embedding dimension. Standard projections yield Qh=XWq, Kh=XWk, and Vh=XWv, utilizing learned weight matrices Wq,Wk,Wv∈Rd×dk where dk=d/H is the head dimension across H heads. The core hypothesis of this work is that the representational spaces spanned by these projection matrices are highly correlated, allowing them to be tied. Specifically, the authors evaluate the cosine similarity and effective rank of trained projection weights, revealing that Key and Value projections naturally exhibit a high similarity of 0.73, while the Query matrix remains distinct (0.42 similarity with Key). This forms the theoretical justification for the Q-K=V variant, which unifies Key and Value projections while preserving the directional asymmetry of the Query. It is worth noting a potential point of notation confusion in the manuscript: the authors utilize a dash (e.g., Q-K=V) to represent distinct versus shared projections, where the dash denotes a separator between different projection spaces rather than mathematical subtraction. For non-causal tasks where spatial symmetry is acceptable, the authors evaluate the symmetric Q=K-V and the highly compressed Q=K=V variants, which collapse the projections into shared spaces.
Mechanizing Projection-Shared Attention Flows
To understand how information flows through a projection-shared attention head, consider a single token input X passing through the optimal Q-K=V configuration. Rather than computing three projections, the system projects X using only two learned matrices to yield a distinct query Q and a unified key-value representation K. The attention output is computed as A=Softmax(αQKT)K, where α=1/sqrt(dk) represents the scaling factor. This flow is illustrated in Figure 1.
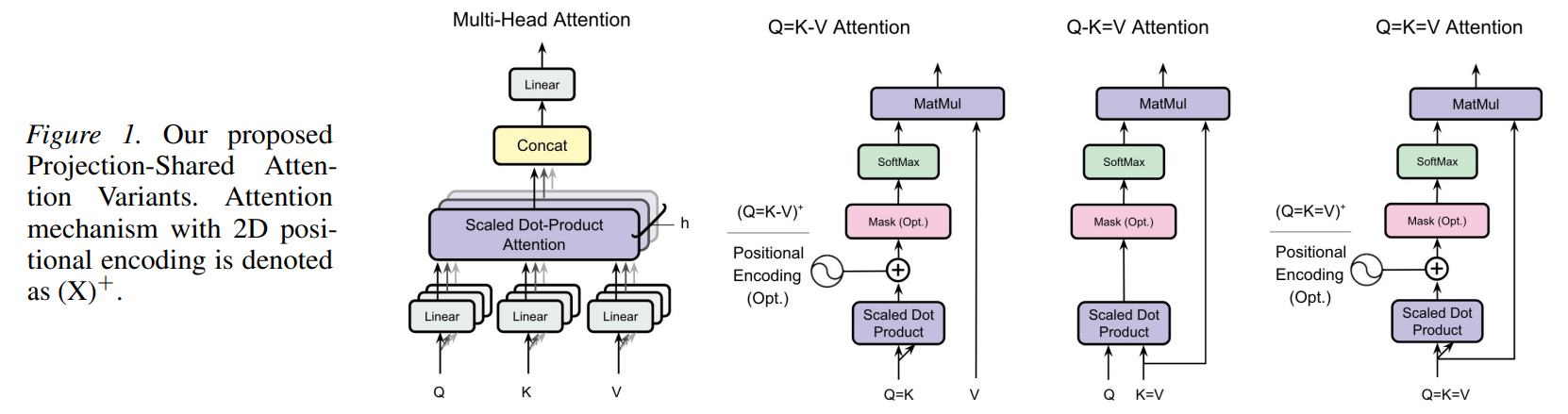
During autoregressive generation, instead of storing separate key and value tensors in the KV cache, only the K tensor is written to memory. During subsequent decoding steps, the attention mechanism reuses the cached K tensor as the value payload, completely bypassing the memory footprint of a separate value cache. For symmetric variants where Q=K (such as Q=K-V), the attention matrix KKT becomes symmetric, which breaks directional awareness. To circumvent this in non-causal contexts, the authors introduce the (X)+ mechanism shown in Figure 1. Under this configuration, the n×n attention map A is broadcasted along the channel dimension to match the m channels of a fixed 2D sinusoidal positional encoding P∈Rn×n×m, yielding the tensor A′=A+P, which is then projected back to Rn×n via a 1×1 convolution, effectively injecting positional and directional bias.
Engineering Constraints and Optimization Setup
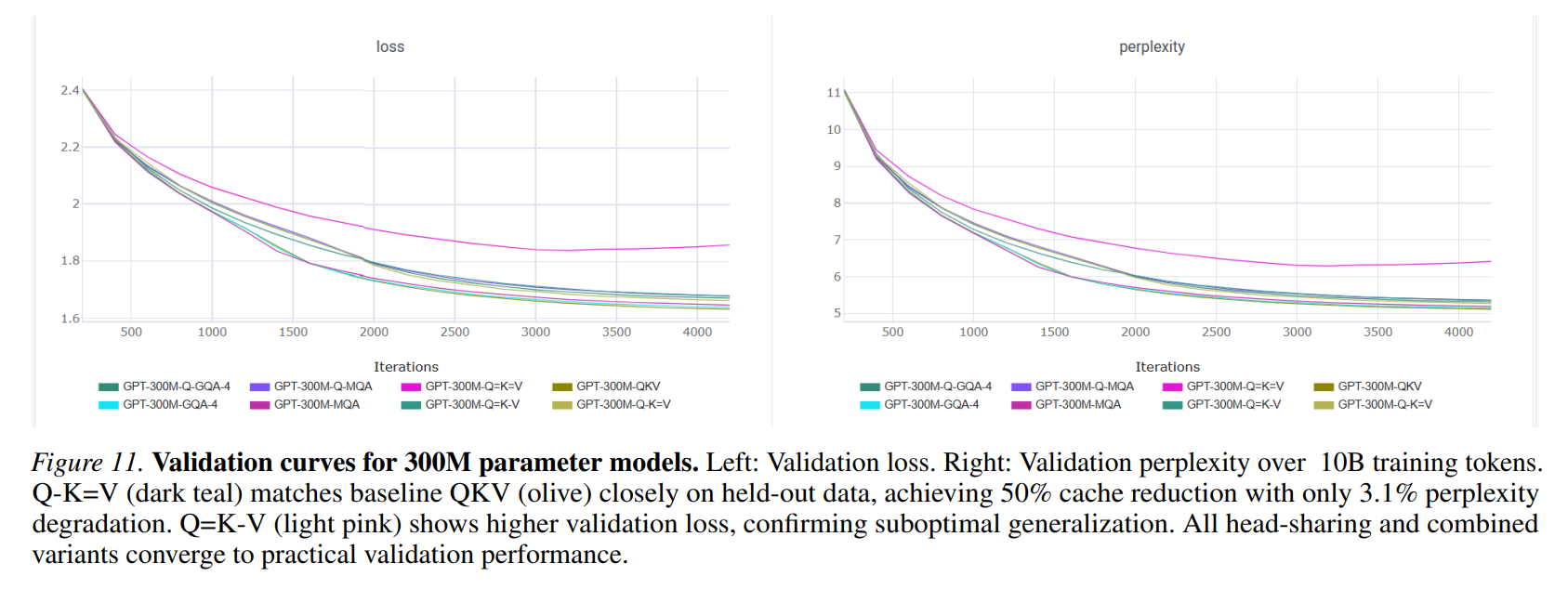
Implementing these variants requires careful calibration of the optimization and regularization strategies to ensure training stability. For language modeling, the authors utilize a standard cross-entropy loss and train decoder-only models using the AdamW optimizer with hyperparameters β1=0.9 and β2=0.95, and a weight decay coefficient of 0.1. To prevent training divergence, pre-norm LayerNorm with ϵ=10−5 is applied before each self-attention and feed-forward sublayer. The learning rate schedule incorporates a 1000-step linear warmup to a peak of 6×10−5 followed by a cosine decay down to a minimum of 6×10−6, combined with gradient clipping at a maximum norm of 1.0. All models are trained in bfloat16 mixed-precision on a distributed cluster of 8 NVIDIA A100 40GB GPUs with a gradient accumulation of 36 steps, ensuring reproducible and highly stable convergence curves as visualized in Figure 11 and Figure 12.
Deconstructing the Efficiency-Quality Pareto Frontier
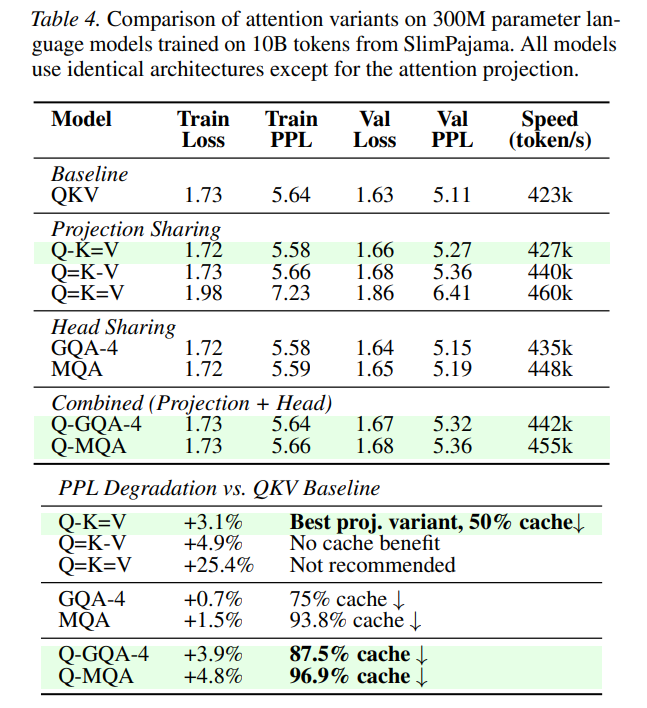
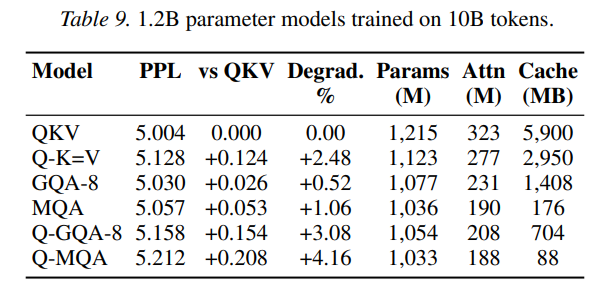
The experimental results across multiple scales provide substantial empirical validation. In language modeling tasks evaluated on 10B tokens from the SlimPajama dataset, the Q-K=V variant trained at 300M parameter scale achieves a 50% KV cache reduction while incurring a negligible perplexity degradation of only 3.1% (5.27 PPL versus 5.11 for the QKV baseline) as detailed in Table 4.
At the 1.2B parameter scale, this gap narrows even further to 2.48% (5.128 PPL versus 5.004 baseline), suggesting that larger models are increasingly robust to projective constraints.
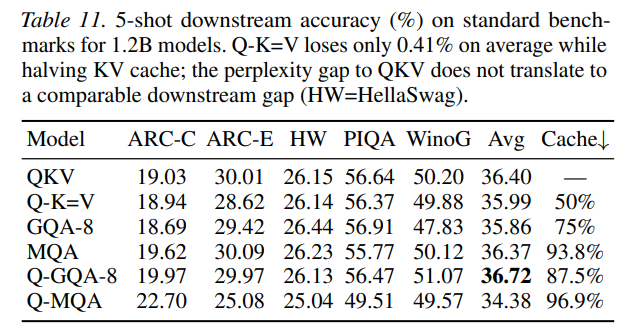
When evaluated on downstream tasks using the lm-eval-harness across standard benchmarks like HellaSwag and WinoGrande, the 1.2B Q-K=V model demonstrates an average accuracy of 35.99%, which is virtually indistinguishable from the baseline QKV model at 36.40% in Table 11.
Conversely, the symmetric Q=K=V variant experiences catastrophic failure in causal language modeling, degrading perplexity by 25.4%, which confirms that preserving query-key asymmetry is vital. Mechanistic probing of the trained weight matrices verifies that keys and values occupy a highly similar representational subspace (0.73 cosine similarity), whereas the query maintains a low similarity (0.42), explaining why K=V weight tying is exceptionally benign.
Mapping the Landscape of Attention Simplification
This work operates in a rich ecosystem of transformer optimization research, directly extending concepts of weight tying in attention originally introduced in the Key-Value Transformer baseline. It stands in contrast to approaches that aim to eliminate attention entirely or replace it with linear complexity models. Instead, it maintains the core flexibility of standard attention while streamlining the projection dimension. Furthermore, the paper demonstrates a fascinating theoretical bridge in the appendix: under complete QKV collapse (qt=kt=vt=zt), linear kernelized attention mathematically reduces to a recurrent state-space model (SSM) with adaptive, input-conditioned observations, defined by the state update St=St−1+ϕ(zt)ztT and output
yt=ϕ(zt)TSt/ϕ(zt)T∑i≤tϕ(zi) where St is the running recurrent state matrix and ϕ(⋅) is a positive feature map. This bridges the gap between attention-based architectures and contemporary state-space models.
Scalability Limits and Implementation Hurdles
Despite the compelling efficiency gains, several limitations must be addressed before widespread adoption. The most prominent constraint is that the maximum validated scale is 1.2B parameters; whether the minor perplexity degradation continues to shrink or suddenly worsens at the 7B to 70B parameter scale remains unverified. Additionally, the evaluations were restricted to sequence lengths up to 2048 tokens, meaning the impact of projection sharing on length extrapolation and long-context needle-in-a-haystack tasks has not been systematically characterized. Finally, standard deep learning libraries and highly optimized kernels like FlashAttention are structurally hardcoded for tripartite QKV tensors. Realizing the physical on-device speedups projected in the paper will require engineering custom CUDA kernels that natively handle unified key-value tensors without requiring memory-expensive padding or materialization steps.
The Path to On-Device Long-Context Serving
Projective sharing represents a powerful paradigm shift in how we conceptualize representational redundancy in deep neural networks. By showing that the key and value projections can be completely unified with minimal quality trade-offs, this research unlocks dramatic serving efficiencies. The most profound strategic implication is the multiplicative synergy with head-sharing baselines: combining Q-K=V with GQA-4 yields an 87.5% cache reduction (see Table 11), while combining it with MQA (Q-MQA) achieves an astonishing 96.9% reduction, making large-scale local deployment on mobile and edge devices highly viable. For practitioners and researchers developing next-generation foundation models, adopting the Q-K=V configuration is a highly recommended architectural modification that yields immediate, substantial memory dividends.