Embarrassingly Simple Self-Distillation Improves Code Generation
Authors: Ruixiang Zhang, Richard He Bai, Huangjie Zheng, Navdeep Jaitly, Ronan Collobert, Yizhe Zhang
Paper: https://arxiv.org/abs/2604.01193v1
Code: https://github.com/apple/ml-ssd
TL;DR
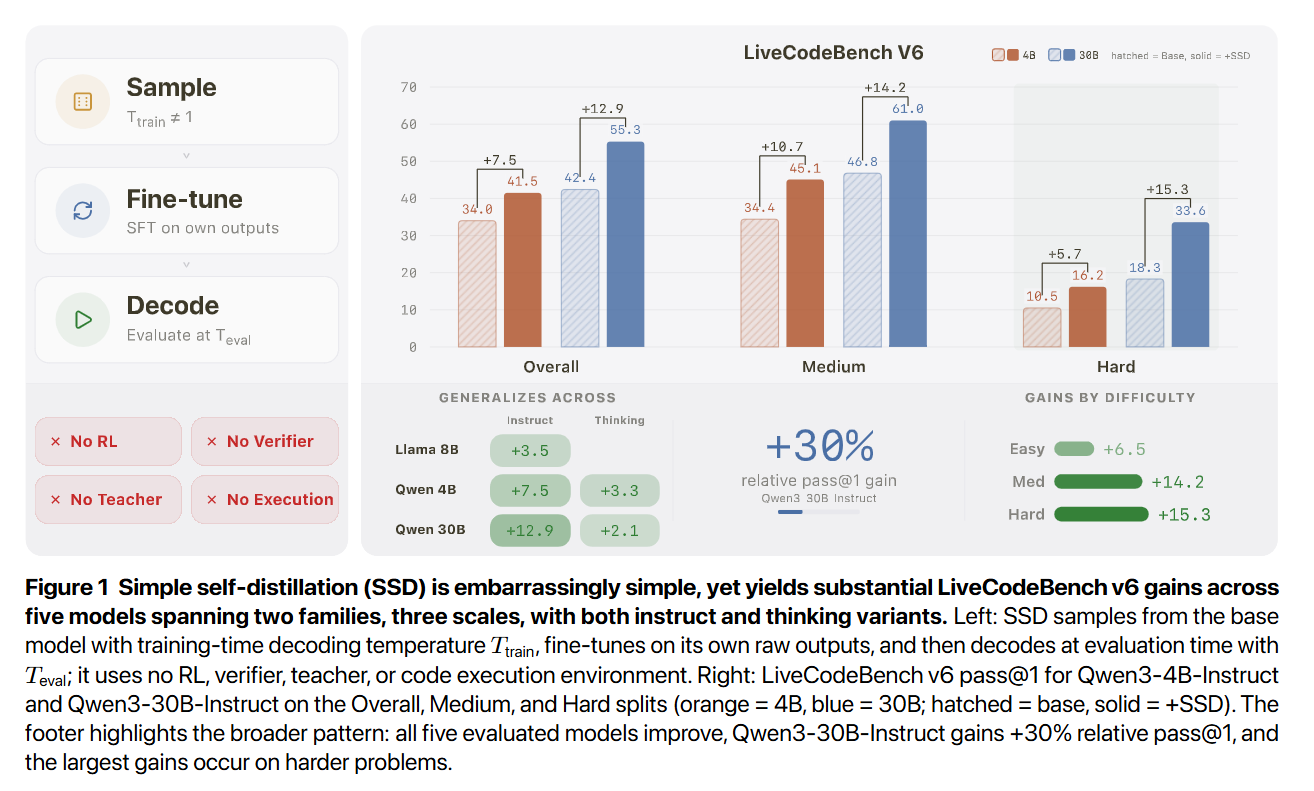
WHAT was done? The researchers introduced Simple Self-Distillation (SSD), a post-training method where a large language model fine-tunes on its own raw, unverified outputs. By generating samples under specific temperature and truncation configurations and directly optimizing a cross-entropy loss against those targets, the model achieves massive gains without reinforcement learning, verifiers, or a stronger teacher.
WHY it matters? This work fundamentally challenges the assumption that improving a language model requires higher-quality external data or complex execution sandboxes. By demonstrating that unverified, and sometimes even garbled, self-generated data can reorganize a model’s internal probability distributions to resolve structural decoding conflicts, this research offers a highly scalable, computationally inexpensive alternative to current alignment and reasoning paradigms.
Executive summary: For strategy leaders and research scientists building coding assistants, the bottleneck has historically been the generation of verified synthetic data or the operational instability of reinforcement learning. This paper proves that latent code generation capabilities can be unlocked purely by exploiting the model’s own distributional geometry. SSD extracts a signal not from the “correctness” of the training data, but from how temperature-shifted sampling forces the model to mathematically suppress distractor tokens in syntax-heavy contexts while preserving diversity at critical algorithmic decision points.
Details
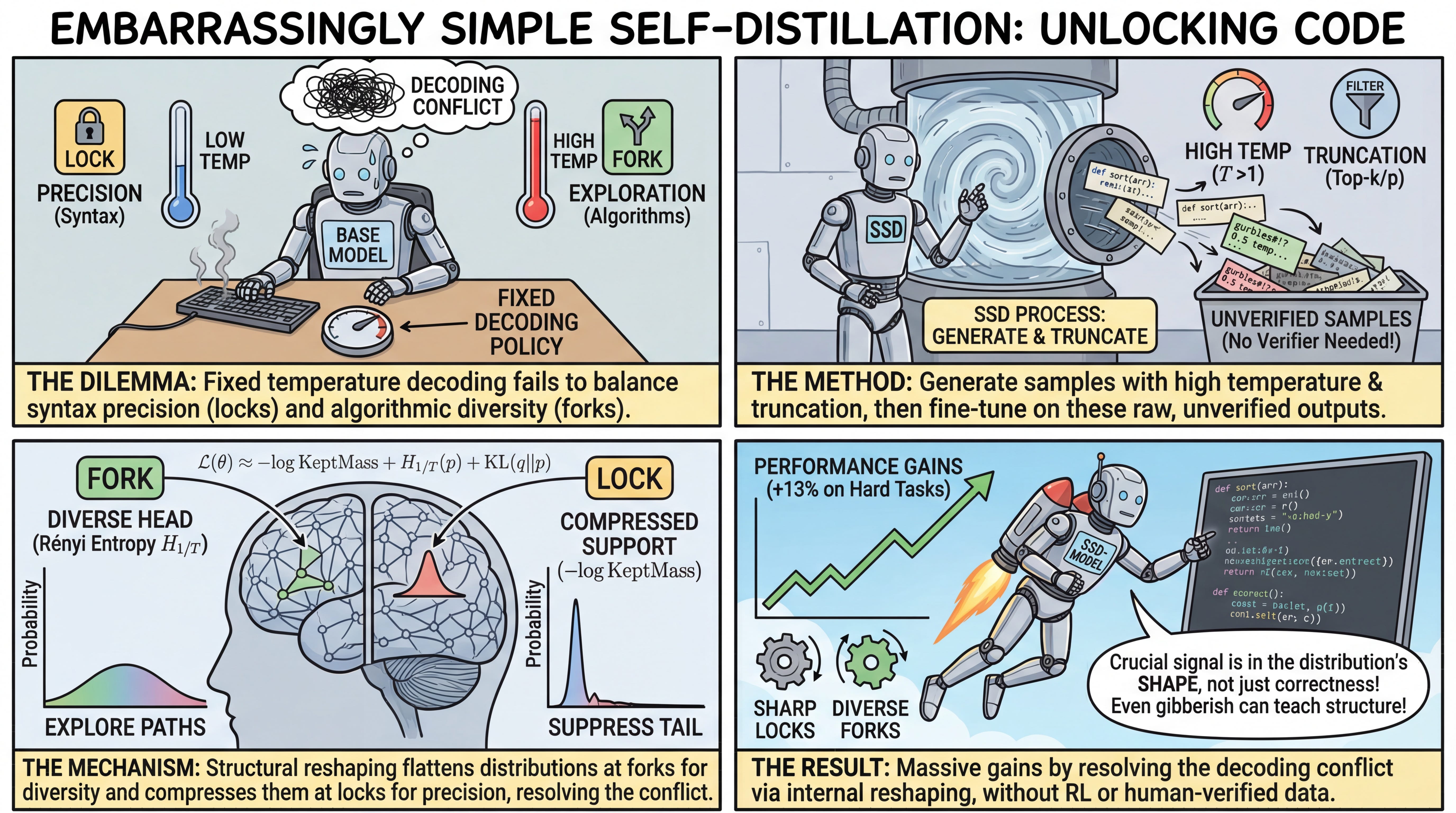
The Verification Bottleneck and the Decoding Dilemma
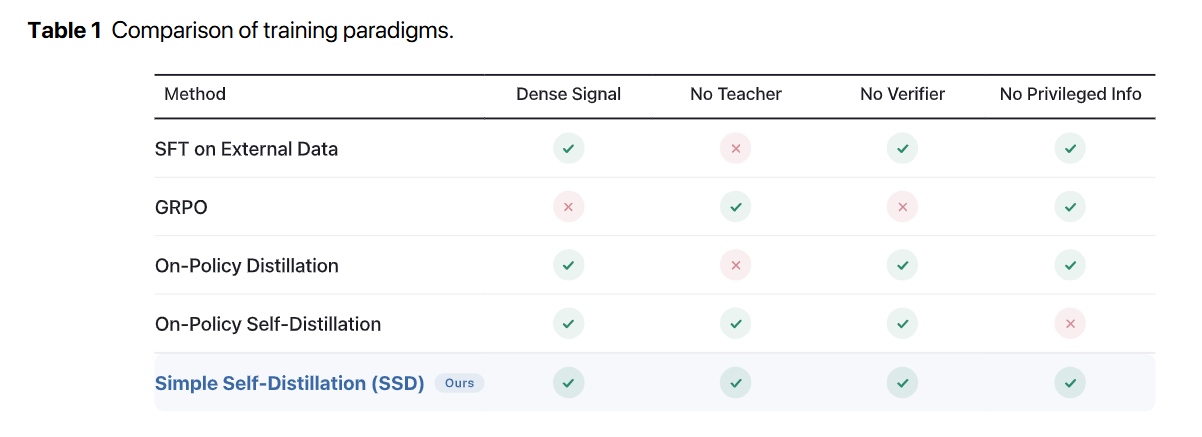
The prevailing consensus in the post-training era is that base models require rigorous, high-fidelity feedback to improve. Traditional approaches rely on SFT on External Data, which demands expensive human annotations, or complex reinforcement learning setups like GRPO, which necessitate execution sandboxes to generate verifiable reward signals. Other methods use stronger frontier models to generate synthetic trajectories, effectively capping the student’s potential at the teacher’s ceiling.
This paper shifts the paradigm by proposing that the bottleneck is not a lack of correct knowledge, but an inherent conflict in how models decode probabilities. Code generation presents contradictory demands. At certain syntax-heavy positions, the model must exhibit absolute precision, demanding a low evaluation temperature to suppress low-probability distractors. At other algorithmic branching points, the model must explore multiple viable paths, requiring a high evaluation temperature to avoid collapsing into a single, potentially flawed strategy. Because fixed decoding policies apply a single temperature globally, they force a compromise that inherently degrades performance at one of these two extremes. The authors introduce Simple Self-Distillation (SSD) to resolve this tension by structurally reshaping the base model’s internal distribution rather than tuning external decoding parameters.