
Evaluating AGENTS.md: Are Repository-Level Context Files Helpful for Coding Agents?
Authors: Thibaud Gloaguen, Niels Mündler, Mark Müller, Veselin Raychev, Martin Vechev
Paper: https://arxiv.org/abs/2602.11988
TL;DR
WHAT was done? Researchers from ETH Zurich and LogicStar.ai rigorously investigated whether repository-level context files (such as AGENTS.md) actually improve the performance of autonomous coding agents. Because existing benchmarks lack repositories with developer-committed context files, the authors constructed AGENTBENCH, a novel evaluation suite of 138 real-world Python software engineering tasks sourced from niche repositories. They evaluated four frontier models across three settings: providing no context file, providing an LLM-generated context file, and providing a human-written context file.
WHY it matters? Despite ubiquitous recommendations from industry leaders to use context files to guide agents, this paper demonstrates that LLM-generated context files actually degrade task success rates while inflating inference costs by over 20%. The findings challenge standard operational heuristics, revealing that supplying models with broad architectural overviews often distracts them into unbounded exploration rather than focused execution.

Details
The Context Bottleneck in Autonomous Engineering
As autonomous systems migrate from isolated functions to full-repository software engineering, their core bottleneck has shifted from raw code generation to contextual navigation. The industry’s prevailing solution has been the introduction of standardized context files—typically named AGENTS.md or CLAUDE.md. These files serve as a repository-level prompt prefix, explicitly defining style guides, environment setup commands, and architectural overviews. However, a significant gap exists between agent-developer guidelines and empirical validation. Established benchmarks like SWE-bench are derived from highly popular, well-documented repositories that historically lack these files. Consequently, the field has lacked a mechanism to measure whether injecting global constraints into the agent’s context window improves structural reasoning or merely dilutes the attention mechanism. This paper provides the first large-scale empirical analysis of this practice by compiling AGENTBENCH, a dataset constructed explicitly from repositories utilizing these files natively.
First Principles of Agentic State Space
To evaluate an agent’s capability systematically, the authors formalize the repository as a deterministically verifiable state machine. The problem space is defined by an instance, represented as a quadruple (I,R,T,X∗). Here, I denotes the natural language issue description, R represents the state of the codebase prior to the fix, T is the suite of regression tests, and X∗ is the ground-truth patch created by human developers.
The objective of the coding agent is to observe I and R to predict an optimal patch, X̂. The system evaluates this prediction using a deterministic update rule. The base repository R is modified by the predicted patch, creating a new repository state denoted as R∘X̂. Success is achieved strictly if the execution of the test suite on the patched repository returns a passing state, mathematically defined as execR∘X̂(T)=PASS. This formalism ensures that the agent’s performance is not graded on semantic similarity to the human patch, but entirely on the functional resolution of the state space.
The AGENTBENCH Mechanism: From Issue to Resolution
To understand the operational flow, consider a specific instance from the evaluation pipeline where an agent is tasked with adding support for chained comparisons in a Python repository. The system initializes a Dockerized execution environment containing the base repository R. The agent, for example, Claude Code, is provided with the issue I and allowed to interact with the environment via a specialized harness utilizing shell tools.
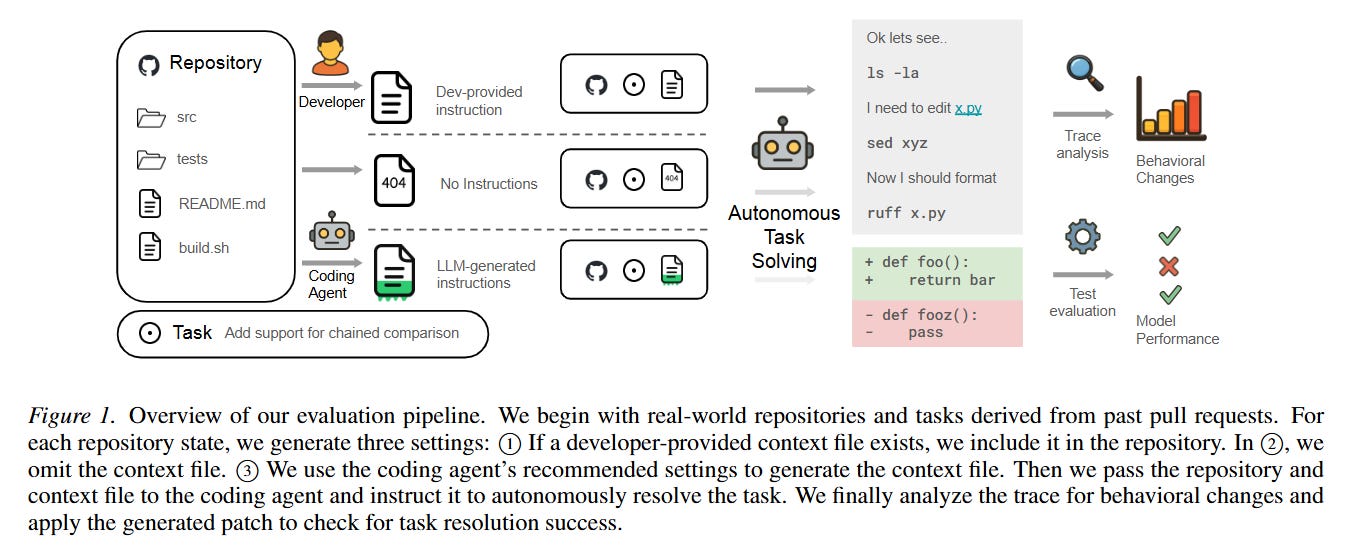
As depicted in Figure 1, the flow diverges based on the context setting. In the standard scenario, the environment includes a context file detailing that the repository uses uv for dependency management and ruff for formatting. The agent reads this file, begins exploring the directories (ls -la), inspects specific files (cat x.py), and applies inline edits (sed). It then executes ruff and runs the test suite T to verify its own work. Once the agent signals completion, the system extracts the predicted patch X̂ and independently verifies the test suite. By tracing this sequence of interactions, the researchers can quantify not only the boolean success rate but also the behavioral variations induced by the context file.
Execution Dynamics and Inference Topology
The experimental evaluation was conducted across four primary coding agents: Claude Code powered by Sonnet-4.5, Codex powered by GPT-5.2 and GPT-5.1 Mini, and Qwen Code powered by Qwen3-30B-Coder. To maintain evaluation integrity, inference parameters were strictly controlled. Temperature was anchored at 0 for API-based models to ensure deterministic tool use, while the open-weight Qwen model was deployed locally via vLLM with a temperature of 0.7.
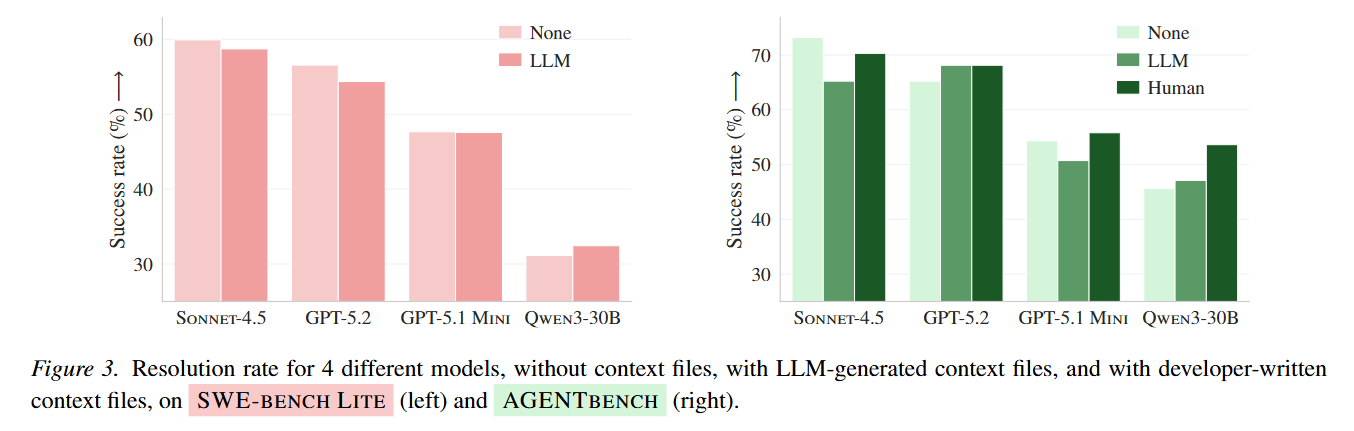
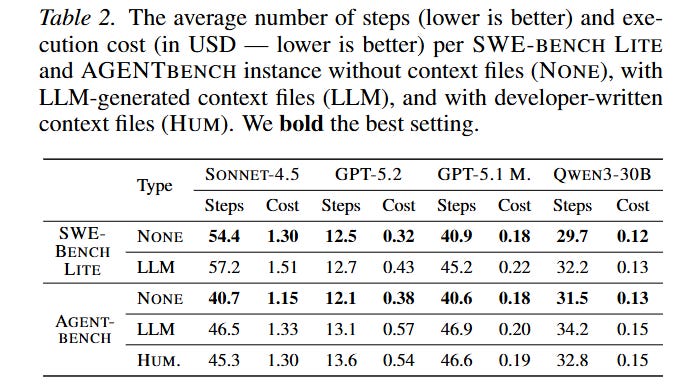
The empirical results reveal a counterintuitive reality regarding agent efficiency. As shown in Figure 3, utilizing LLM-generated context files does not elevate agent capabilities; rather, it universally triggers performance degradation, reducing average resolution rates by 0.5% on SWE-bench Lite and 2% on AGENTBENCH. More critically, Table 2 highlights the infrastructural burden of this practice. Across all models, context files increased the length of the trajectory by an average of 3.92 steps. For a model like GPT-5.2, this expanded search behavior balloons the total cost of inference by over 20% per instance, rendering the widespread automated generation of AGENTS.md files computationally inefficient. Even human-written context files provided only a marginal 4% improvement on average, primarily in scenarios where no other documentation existed.
Trace Analysis: The Mechanics of Distraction
The underlying cause of this performance drop becomes apparent through mechanistic trace analysis. The authors utilized a secondary LLM pipeline to categorize every tool call invoked by the agents into distinct intent clusters. When context files explicitly mention specific tools, instruction adherence is remarkably high. For instance, the invocation of repository-specific tools spikes from nearly zero to 2.5 times per instance when prompted by the context document.
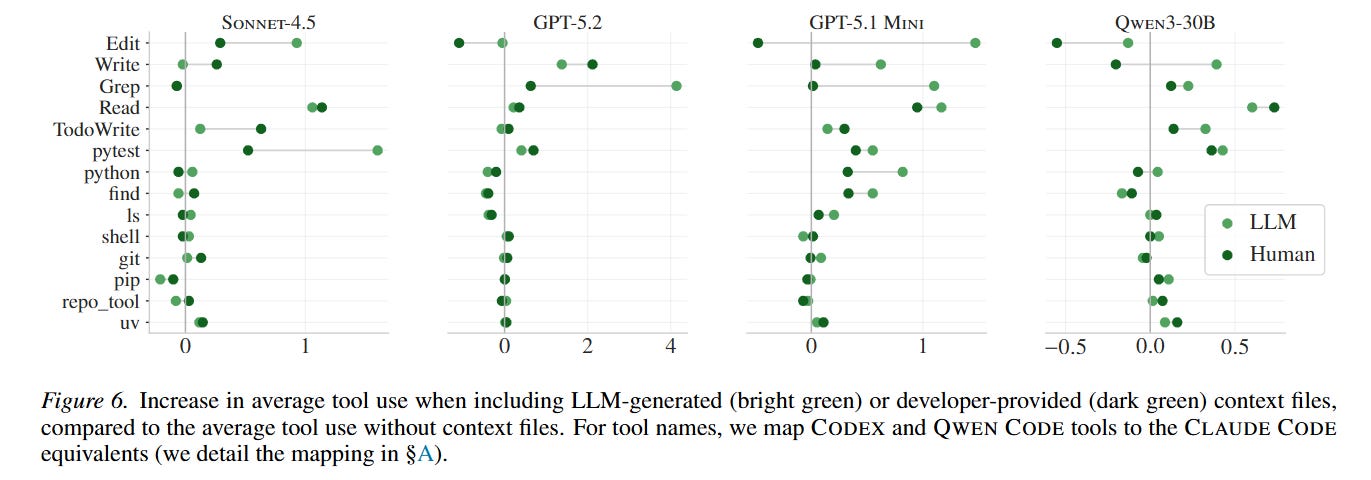
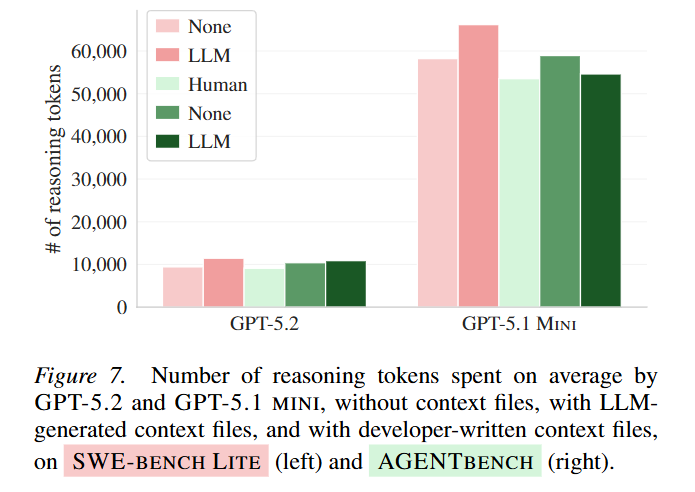
However, this obedience manifests as counterproductive exploration. Figure 6 demonstrates that agents equipped with context files execute significantly more searches (grep), read more files, and run redundant testing loops. The inclusion of architectural overviews in these files serves as a distraction rather than a map. By manually deleting standard project documentation, the researchers discovered that context files only provide a substantial net benefit when they act as the absolute sole source of information in a completely undocumented repository. In well-maintained codebases, the files act as redundant data that prompts the agent’s attention mechanism to over-explore the directory tree before attempting a targeted fix, actively exhausting its reasoning tokens.
Contextualizing Within Related Works
This analysis sits at the intersection of repository-level code generation and self-improving agent architectures. The construction of AGENTBENCH directly addresses the saturation and popularity biases inherent in datasets like SWE-bench Lite. It builds upon foundational methodologies for automated benchmark generation, echoing the robust evaluation frameworks seen in works exploring autonomous feature-driven development such as SWE-Dev (https://arxiv.org/abs/2505.16975). By shifting the focus to how agents consume global parameters, this paper challenges assumptions made by scaffolding systems like SWE-agent, suggesting that expanding the state representation through generalized Markdown summaries yields diminishing returns.
Limitations of the Redundancy Hypothesis
While the behavioral findings are robust, the evaluation methodology exhibits a heavy bias toward Python-based projects. Python is exhaustively represented in the pre-training corpora of all tested frontier models, including GPT-5.1 Mini (https://arxiv.org/abs/2601.03267). It is highly probable that these models already possess deep parametric knowledge regarding standard Python architectures, rendering explicit textual context redundant. The dynamics of context files might shift dramatically when evaluating niche programming languages or proprietary internal DSLs where the model cannot rely on latent knowledge.
Strategic Implications and Verdict
The practice of autonomously generating AGENTS.md files to adapt coding agents to new repositories operates on a flawed assumption regarding how current language models process global repository context. This paper convincingly argues that generalized architectural overviews trigger unbounded exploration, tangling agents in excessive reasoning steps that inflate compute costs without yielding higher resolution rates. The strategic recommendation is clear: automated context file generation should be deprecated in standard workflows. If context files are utilized, they must be manually authored by developers and strictly limited to indispensable operational constraints, avoiding broad structural documentation that distracts the agent from the atomic resolution of the task at hand.
