
Fantastic Pretraining Optimizers and Where to Find Them
Authors: Kaiyue Wen, David Hall, Tengyu Ma, Percy Liang
Paper: https://arxiv.org/abs/2509.02046
Code: https://github.com/marin-community/marin/tree/kaiyue/optimizers
WandB Runs: https://wandb.ai/marin-community/optimizer-scaling
TL;DR
What was done? The authors conduct a systematic and rigorous re-evaluation of eleven deep learning optimizers for language model pretraining. They address two common methodological flaws in prior research: unequal hyperparameter tuning and limited evaluation setups. Using a meticulous three-phase coordinate descent framework, they ensure near-optimal hyperparameters for all optimizers—including the AdamW baseline—across four model scales (0.1B to 1.2B parameters) and multiple data-to-model ratios (1-8x the Chinchilla optimum).
Why it matters? This work serves as a critical reality check for the field. It reveals that the widely claimed 1.4-2x speedups of novel optimizers over AdamW are often significantly inflated due to poorly tuned baselines. The study finds that the true speedup is much more modest, peaking at 1.4x for small models and, crucially, diminishing with scale to a mere 1.1x for 1.2B parameter models. This finding challenges the narrative of rapid progress in optimization and sets a new, higher standard for fair and robust benchmarking. It provides invaluable, sobering insights for researchers and practitioners, highlighting that for large-scale training, the race for a "better-than-AdamW" optimizer is far from over, and true gains may require new approaches designed explicitly for scalability.

Details
The Quest for a Faster Optimizer
In the world of large language models (LLMs), pretraining accounts for over 95% of the computational cost, making the choice of optimizer a critical factor in both research and production. For years, AdamW has been the reliable workhorse. Recently, however, a wave of new optimizers has emerged, promising significant training speedups of 1.4x to 2x or even more. These include methods like Sophia (Liu et al., 2024a), Muon (Jordan et al., 2024), and Soap (Vyas et al., 2025), among others. But do these claims hold up under rigorous scrutiny? This paper meticulously investigates this question and finds that the reality is far more nuanced.
The authors posit that many previous comparisons have been undermined by two fundamental methodological shortcomings:
Unequal Hyperparameter Tuning: Baselines like AdamW are often not tuned as rigorously as the newly proposed optimizers, leading to an unfair comparison and inflated speedup claims.
Limited Evaluation Setups: Many studies are confined to smaller-scale models or a narrow range of data regimes, leaving their scalability and generalizability in question.
To correct this, the paper undertakes an exhaustive benchmarking study of eleven prominent optimizers, providing a clearer picture of their true capabilities.
A New Standard for Fair Benchmarking
The core of this paper is its rigorous evaluation framework, designed to ensure a fair and level playing field for every optimizer. This is achieved through a systematic, three-phase hyperparameter tuning process.
Experimental Setup:
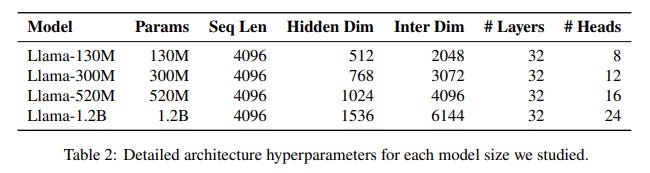
Models: The study uses the Llama 2 architecture across four scales: 130M, 300M, 520M, and 1.2B parameters (Table 2).
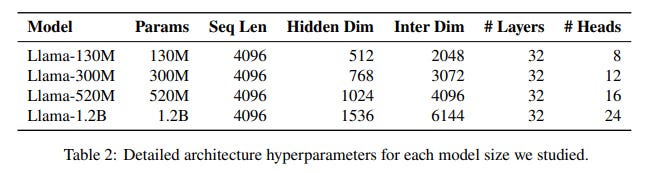
Data: A large-scale corpus combining DCLM-baseline, StarCoder V2, and ProofPile 2 is used, with training conducted at 1x, 2x, 4x, and 8x the Chinchilla-optimal data-to-model ratio.
Optimizers: Eleven optimizers are benchmarked, including AdamW, variance-reduced variants (NAdamW, Mars), memory-efficient options (Lion, Adam-mini), and matrix-based preconditioners (Muon, Soap, Kron, Scion) (Table 1).
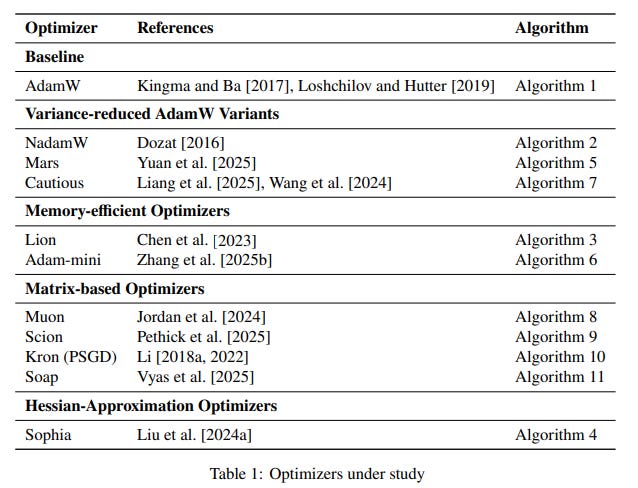
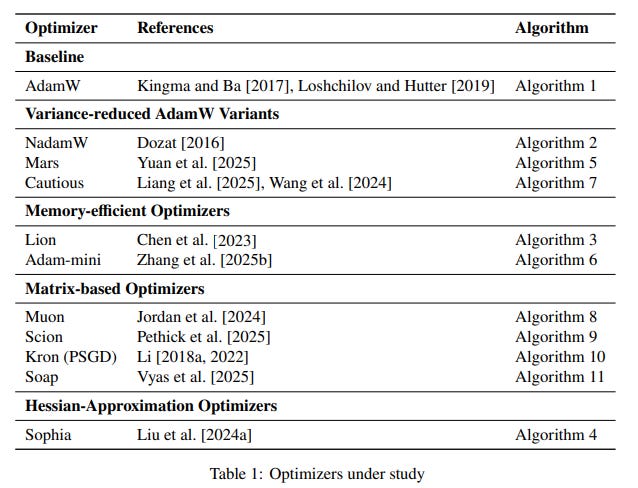
The Three-Phase Tuning Framework:
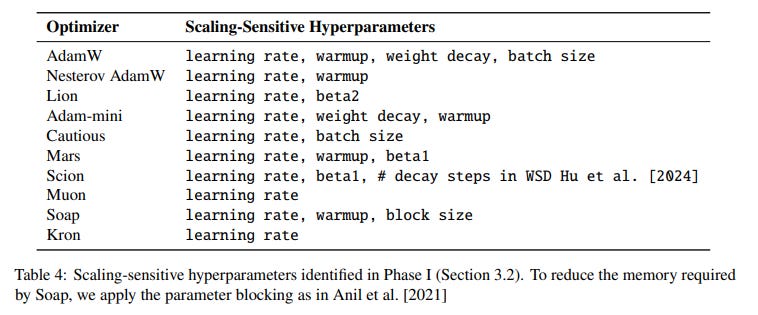
Phase I: Fine-grained Coordinate Descent: To avoid weak baselines, the authors perform an exhaustive, one-at-a-time sweep over each hyperparameter (e.g., learning rate, weight decay, β₁, β₂, batch size) for each optimizer on small-to-mid-scale settings. The process is iterated until no further significant improvement is found, ensuring a coordinate-wise local optimum. An example of this meticulous process for AdamW is shown below (Table 3).

Phase II: Focusing on Scaling-Sensitive Hyperparameters: From the initial sweeps, the authors identify "scaling-sensitive" hyperparameters—those whose optimal values change significantly with model or data scale (Table 4). Subsequent tuning efforts are focused on these critical parameters, making the search process more efficient for larger settings. Combined, the first two phases involved finding near-optimal configurations for 11 optimizers across 12 distinct settings (combinations of model size and data ratio), a testament to the study's methodological depth.
Phase III: Extrapolating with Scaling Laws: To test performance at the 1.2B scale without incurring prohibitive computational costs, the authors fit a smooth scaling law to predict optimal hyperparameter values. The optimal value for a hyperparameter
his modeled as a function of model sizeNand data budgetD:h(N, D) = αN⁻ᴬD⁻ᴮ + βThis principled extrapolation allows the study to probe optimizer behavior at larger scales.

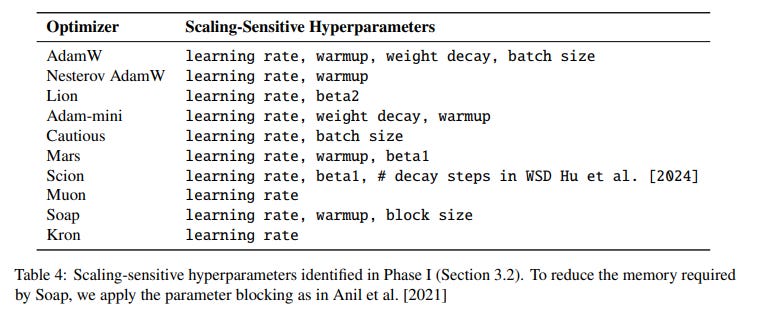
Crucially, all evaluations are performed at the end of the target training budget, as the authors demonstrate that optimizer rankings can flip during training, making early-stage loss curves a misleading metric (Figure 5).
Key Findings: A Sobering Reality Check
The results from this comprehensive study temper the excitement around many new optimizers and offer several critical insights.
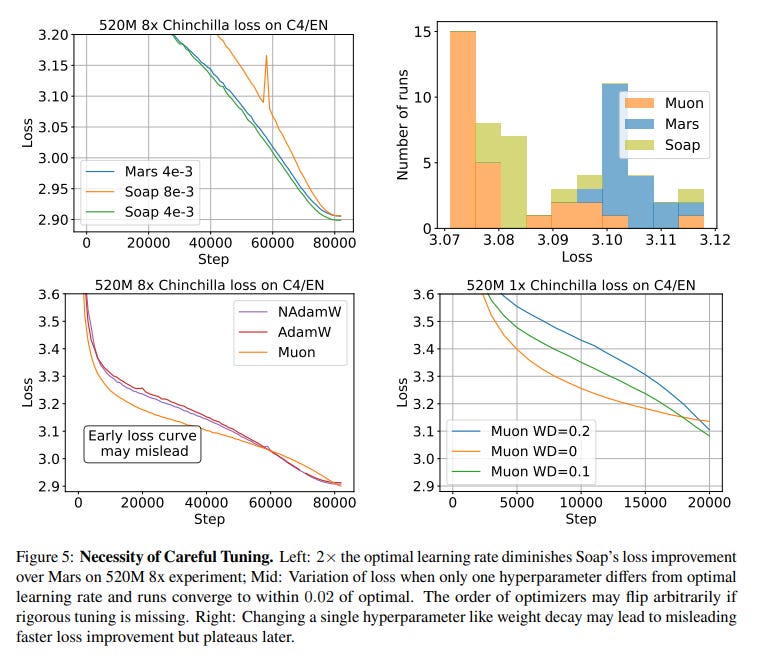
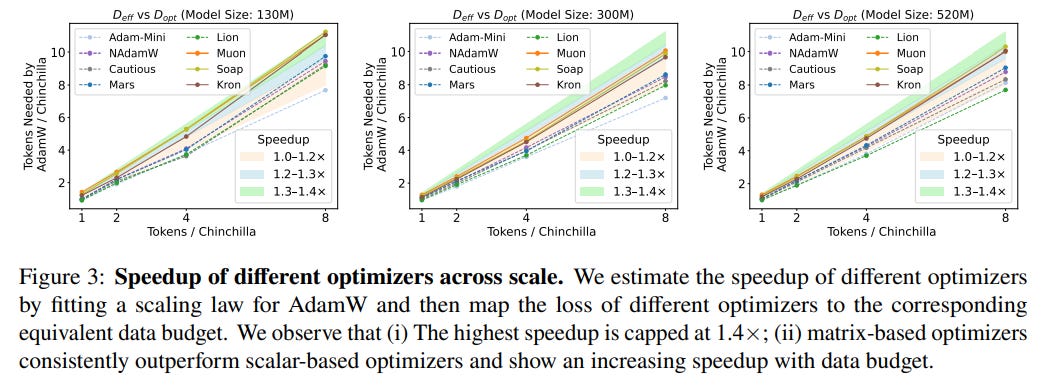
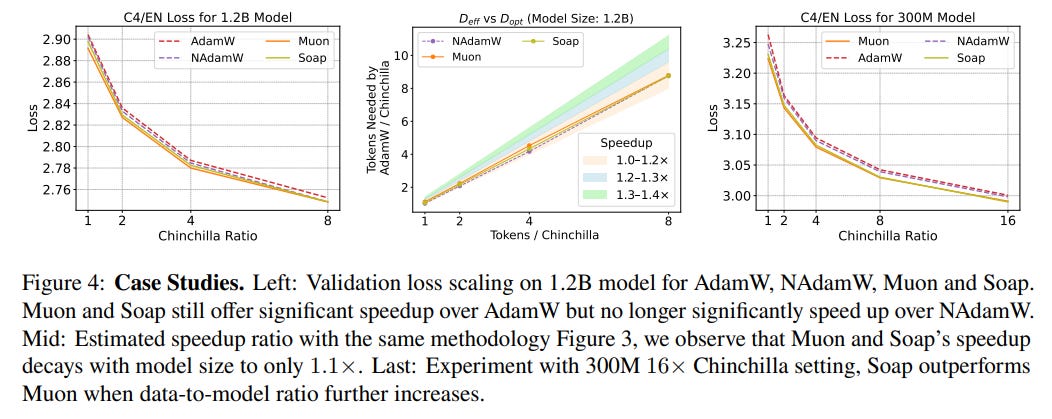
1. Claimed Speedups are Lower and Diminish with Scale The most striking finding is that after rigorous tuning of the AdamW baseline, the speedups offered by alternative optimizers are much smaller than often claimed. While matrix-based optimizers like Muon and Soap show a respectable 1.4x speedup for 130M parameter models, this advantage shrinks dramatically with scale, dropping to a modest 1.1x speedup for 1.2B parameter models (Figure 1, Figure 4). This trend suggests that current "state-of-the-art" optimizers may not offer a meaningful advantage for training frontier-scale models.
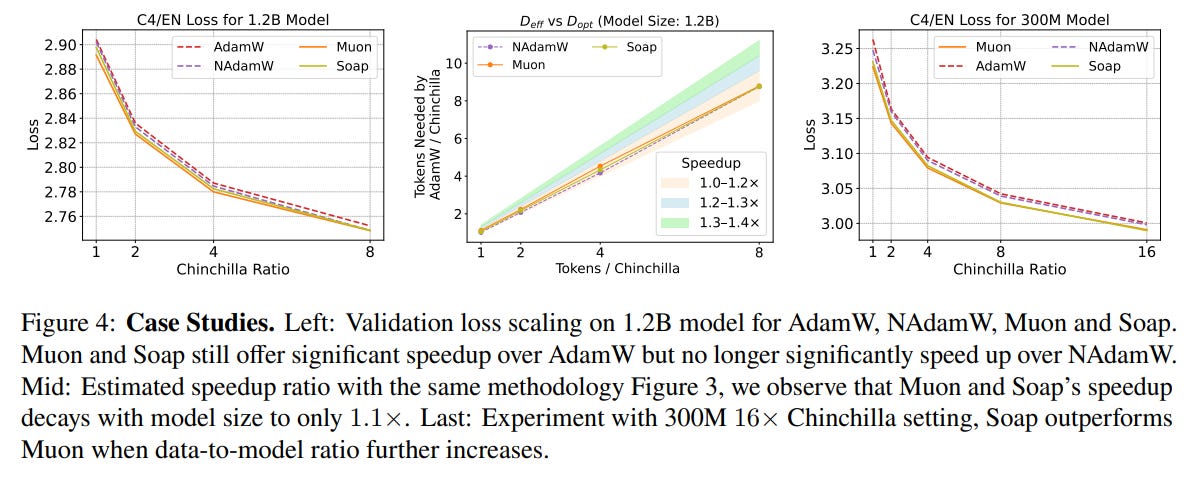
2. Matrix-Based Optimizers Lead, but Context is Key Matrix-based optimizers (e.g., Kron, Muon, Soap), which leverage the matrix structure of neural networks to precondition gradients, consistently outperform scalar-based counterparts. In simple terms, instead of adjusting each parameter's update with a single scalar value, these methods use entire matrices to rotate and stretch the update direction, aligning it more intelligently with the complex geometry of the loss landscape. However, the "best" optimizer is not universal; its performance depends on the training regime. For instance, while Muon excels in lower data-to-model ratios, it is outperformed by Kron and Soap when the ratio increases to 8x or more (Figure 3, Figure 4). This highlights that there is no one-size-fits-all solution.
3. The Critical Importance of Methodological Rigor The paper provides compelling evidence for its initial thesis:
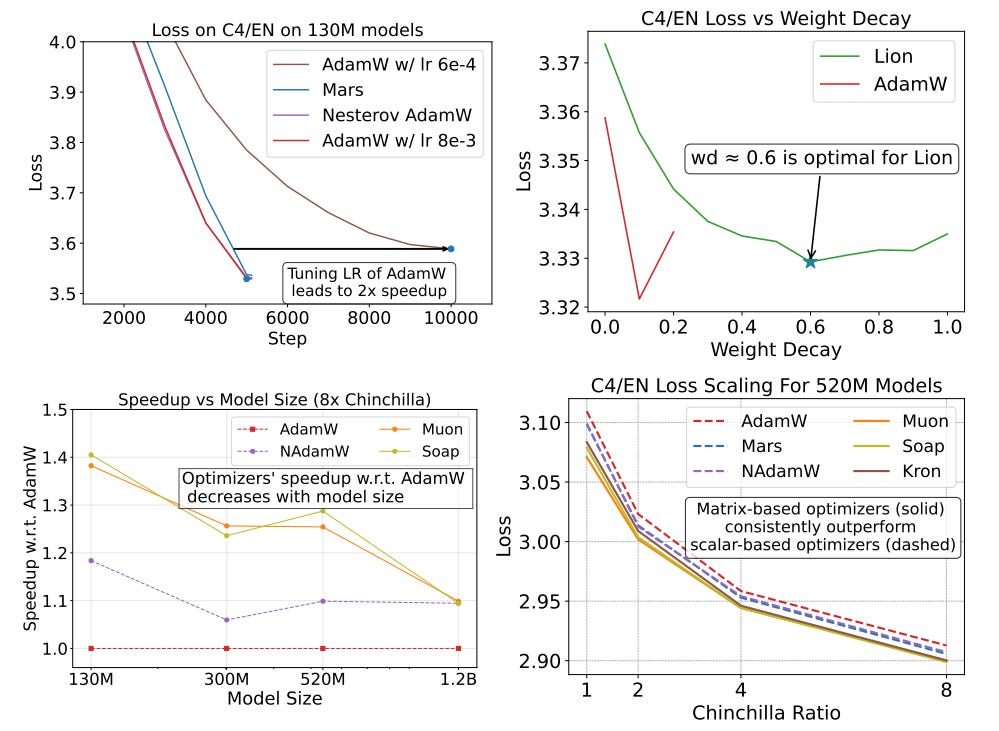
Tuning Matters: Simply tuning the learning rate of the standard AdamW baseline in a common GPT-3 recipe can yield a 2x speedup, demonstrating that many reported gains may stem from an under-tuned baseline (Figure 1).
Hyperparameters Don't Transfer: Even similar optimizers may require vastly different optimal hyperparameters. For example, the optimal weight decay for Lion was found to be ~0.6, while AdamW's was ~0.1. Blindly transferring hyperparameters is an unfair practice (Figure 1).
Early-Stage Loss is Misleading: Optimizer rankings can change multiple times throughout training due to learning rate decay. Final performance at the target training budget is the only reliable measure of effectiveness (Figure 5).
The Path Forward
This work is a significant contribution not for introducing a new optimizer, but for its role as a scientific course correction. It sets a new, higher standard for how optimizers should be benchmarked and challenges the community to move beyond incremental gains that do not scale.
The findings suggest that the next major breakthrough in training efficiency may not come from the current generation of complex optimizers. Instead, the authors point toward a more challenging but necessary direction for future research: designing optimizers whose efficiency is stable and predictable under scaling laws, ensuring that their benefits persist as we push the frontiers of model size and data.
While the study is limited to models up to 1.2B parameters, its meticulous methodology and sobering results provide a foundational reference for anyone working on—or choosing—an optimizer for large-scale AI. It reminds us that in the quest for "fantastic optimizers," rigorous and transparent evaluation is where they are truly found. This work follows in the footsteps of other critical re-evaluations, such as Schmidt et al. (2021), which reached similar conclusions about the importance of fair tuning for an earlier generation of optimizers, highlighting this as a vital and recurring theme in machine learning research.