FIRE: Frobenius-Isometry Reinitialization for Balancing the Stability-Plasticity Tradeoff
Authors: Isaac Han, Sangyeon Park, Seungwon Oh, Donghu Kim, Hojoon Lee, Kyung-Joong Kim
Paper: https://arxiv.org/abs/2602.08040
Code: https://isaac7778.github.io/fire/
TL;DR
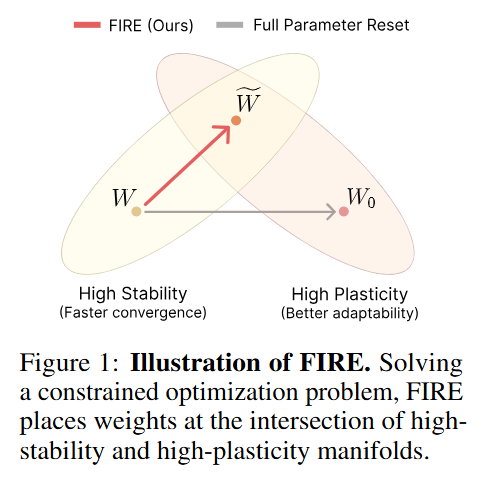
WHAT was done? The authors propose FIRE (Frobenius-Isometry REinitialization), a method that mathematically formalizes weight resetting in continual learning as a constrained optimization problem. Instead of using heuristic noise injection, FIRE projects weights onto an orthogonal manifold to maximize plasticity while minimizing the Frobenius distance to the previous weights to maximize stability. This projection is achieved via an efficient Newton-Schulz iteration that approximates the polar decomposition.
WHY it matters? Neural networks lose the ability to learn (plasticity) over time, particularly in non-stationary environments like Reinforcement Learning (RL) or continual pretraining. Current fixes, such as “Shrink and Perturb,” rely on hand-tuned hyperparameters to guess the right amount of noise to inject. FIRE eliminates this guesswork, providing a theoretically grounded, tuning-free mechanism that demonstrably reduces dormant neurons and improves adaptation in Vision, LLMs, and RL.

Details
The Reinitialization Dilemma
A pervasive issue in continual learning and reinforcement learning is the degradation of plasticity: as a model trains on a non-stationary stream of data, its weights become rigid, effective rank collapses, and it loses the capacity to adapt to new distributions. While catastrophic forgetting (loss of stability) is often the headline problem, the inability to learn new tasks (loss of plasticity) is equally fatal for long-running agents. The field has largely bifurcated into regularization methods, which constrain weights during training, and reinitialization methods, which periodically reset weights.
Reinitialization approaches, such as Shrink and Perturb (S&P) or the more recent DASH, generally outperform regularization by allowing the optimization trajectory to escape local minima. However, they suffer from a significant tuning bottleneck. A “conservative” reset with small perturbations fails to restore plasticity, while an “aggressive” reset or full re-randomization destroys the learned representation, requiring expensive re-learning. The current state-of-the-art relies on heuristics to find a “Goldilocks” zone. FIRE fundamentally alters this landscape by reframing reinitialization not as a heuristic perturbation, but as a precise projection onto a specific geometric manifold.