Fixed-Point Reasoners: Stable and Adaptive Deep Looped Transformers
Authors: Sajad Movahedi, Vera Milovanović, Shlomo Libo Feigin, Alexander Theus, Thomas Hofmann, Valentina Boeva, T. Konstantin Rusch, Antonio Orvieto
Paper: https://arxiv.org/abs/2606.18206
Code: https://github.com/nilskiKonjIzDunava/fprm
Model: N/A
TL;DR
WHAT was done? The authors introduce the Fixed-Point Reasoning Model (FPRM), a looped, non-hierarchical Transformer that replaces standard post-normalization with pre-normalization and introduces learnable, layer-wise and iteration-wise residual scaling to stabilize latent-space trajectories. This architecture enables stable, continuous fixed-point convergence as a native, training-free halting mechanism, augmented at test-time by a patience-based damping algorithm (FPOPT) to eliminate latent oscillations.
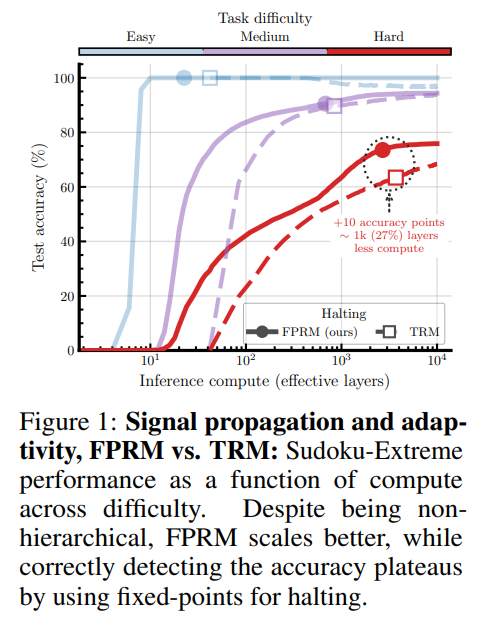
WHY it matters? This work demonstrates that the complex hierarchical looping structures (such as separate slow and fast loops) commonly used in state-of-the-art recursive models are largely redundant workarounds for poor signal propagation caused by post-normalization. By resolving optimization issues at extreme unrolled depths, FPRM achieves superior test-time compute adaptivity and out-of-distribution generalization using a significantly simpler, single-loop architecture.

Details
The Curse of Depth in Latent Recurrence
Looped neural architectures, such as Universal Transformers [review], decouple parameter count from effective depth, introducing architectural flexibility by unrolling computation along the depth dimension. However, when these recurrent systems are unrolled to solve challenging reasoning tasks, they suffer from the same signal propagation difficulties—the “curse of depth”—that plague very deep non-looped networks. To combat this, standard looped models historically relied on post-normalization (PostLN) to bound activation magnitudes as the model iterates, which prevents the hidden states from diverging but severely restricts gradient and representation propagation. Recent recursive architectures like the Hierarchical Reasoning Model (HRM) [review] and the Tiny Reasoning Model (TRM) [review] attempted to mitigate this bottleneck by designing complex, multi-scale hierarchical loops that split compute between fast-looping and slow-looping components. The primary delta of this paper is demonstrating that these elaborate, biologically-inspired hierarchies are largely redundant. By fundamentally fixing the signal propagation pathway using pre-layer normalization (PreLN) paired with learned residual scaling, a simple, flat, non-hierarchical loop can utilize deeper effective layers and easily outperform its hierarchical predecessors.