
Flow Reasoning Models: Scaling Reasoning Through Iterative Self-Refinement
Authors: Alec Helbling, Andrey Bryutkin, Mauro Martino, Nima Dehmamy, Hendrik Strobelt
Paper: https://arxiv.org/abs/2606.29150
Code: N/A
Model: N/A
TL;DR
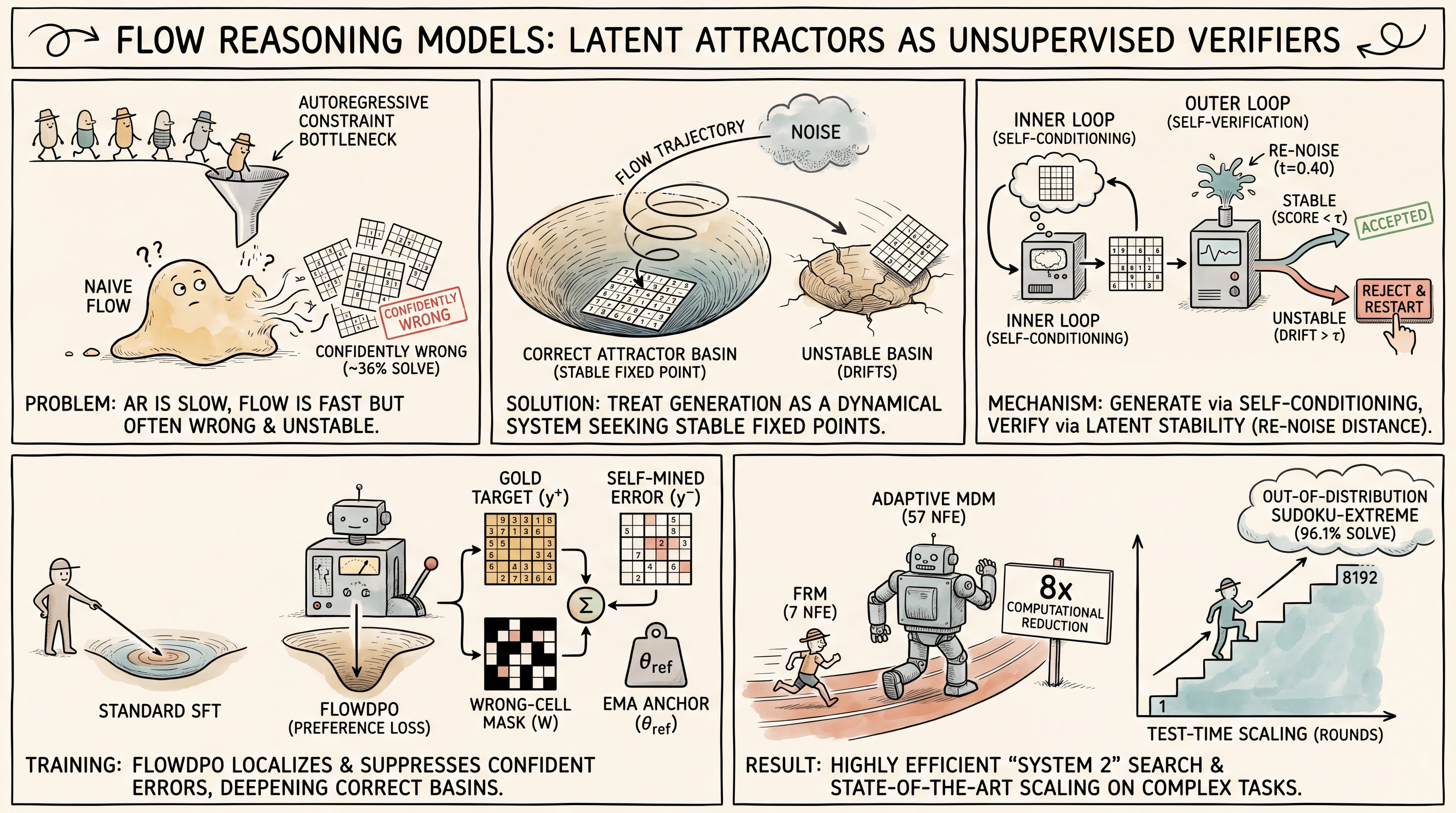
WHAT was done? The authors introduce Flow Reasoning Models (FRMs), a training and test-time-scaling framework designed to solve structured constraint-satisfaction tasks (e.g., Sudoku, Zebra puzzles) using discrete flow models. FRMs leverage fixed-point stability within the model’s own denoising dynamics as an unsupervised, label-free correctness verifier, and introduce a localized preference learning objective called FLOWDPO to actively suppress self-generated mistakes.
WHY it matters? This work establishes that generative flow networks contain latent, highly reliable verification signals (approaching 1.0 AUROC) within their own geometric dynamics, negating the need for separate, expensive reward models or external checkers. By treating generation, verification, and alignment as unified components of a single fixed-point attractor system, FRMs achieve state-of-the-art constraint-solving accuracy while reducing inference compute overhead by over 8× compared to strong masked-diffusion baselines.
Details
The Out-of-Distribution Constraint Bottleneck
Autoregressive models have dominated language and sequential reasoning, yet they remain bottlenecked by their token-by-token, left-to-right generation style when faced with highly structured constraint-satisfaction problems where a globally consistent answer is required. Non-autoregressive discrete flow models show promise for parallel, few-step generation, but naive sampling often causes them to converge confidently to incorrect states, yielding a poor solve rate of only ~36% on standard Sudoku puzzles. This issue stems from a structural misalignment: standard maximum-likelihood training over the entire vocabulary space forces models to learn marginal token distributions without mapping the underlying global logical boundaries. While previous search strategies have attempted to scale test-time compute through vote-based self-consistency or external verifiers, these approaches either fail to generalize to out-of-distribution scenarios or require expensive labeled verification datasets. Flow Reasoning Models address this bottleneck by redefining the generation process not as a single-pass sample, but as a stateful dynamical system that seeks stable attractor basins.
