
From Text to Task
How Text-to-LoRA Enables On-the-Fly Model Adaptation
Text-to-LoRA: Instant Transformer Adaption
Authors: Rujikorn Charakorn, Edoardo Cetin, Yujin Tang, Robert T. Lange
Paper: https://arxiv.org/abs/2506.06105
Code: https://github.com/SakanaAI/text-to-lora
Model: The work utilizes publicly available base models from Mistral, Meta, and Google, and the training data is sourced from https://huggingface.co/Lots-of-LoRAs.
TL;DR
WHAT was done? The paper introduces Text-to-LoRA (T2L), a hypernetwork that generates task-specific Low-Rank Adaptation (LoRA) adapters for Large Language Models (LLMs) in a single, inexpensive forward pass. Instead of requiring task-specific data and a lengthy fine-tuning process, T2L takes only a natural language description of the target task as input. The T2L hypernetwork's design allows it to generate a complete, structured adapter by processing a combined input vector representing the task description, the target module (e.g., query projection), and the specific layer index. The authors propose two training schemes: 1) A reconstruction loss to compress hundreds of pre-trained LoRA adapters, and 2) A supervised fine-tuning (SFT) loss on a diverse set of downstream tasks, which enables the model to generalize to entirely new tasks.
WHY it matters? T2L represents a significant shift from the conventional, resource-intensive paradigm of LLM specialization. By translating human instructions directly into model adaptations, it democratizes the ability to customize foundation models, removing the need for deep ML expertise or vast computational resources. The SFT training approach is particularly impactful, as it unlocks true zero-shot generalization, allowing T2L to create effective adapters for entirely unseen tasks. This "instant adaptation" capability not only makes LLMs more flexible and steerable but also drastically reduces the computational overhead, paving the way for more dynamic, responsive, and accessible AI systems.

Details
The specialization of powerful foundation models remains a central challenge in AI. While parameter-efficient fine-tuning (PEFT) methods like LoRA have reduced the cost compared to full fine-tuning, they still demand a separate, data-intensive training process for every new task. This creates a bottleneck, limiting the agility and accessibility of model customization. A recent paper, "Text-to-LoRA: Instant Transformer Adaption," introduces a compelling solution that re-imagines this process entirely. It proposes a system that can adapt an LLM on the fly, guided by nothing more than a simple text description of the desired task.
A Hypernetwork for Instant Adaptation
The core contribution is Text-to-LoRA (T2L), a hypernetwork designed to generate the parameters of a LoRA adapter in a single forward pass. This approach is built on the foundational work of both LoRA and Hypernetworks, combining them into a powerful and elegant solution.
The T2L hypernetwork is cleverly designed to generate the entire set of LoRA weights for all specified layers in a single, batched forward pass. It achieves this by taking a concatenated input vector that describes not just the task, but also which specific part of the base model to modify. As detailed in the paper's methodology, this input combines an embedding of the task description (the 'what'), a learnable embedding for the module type (e.g., query or value projection, the 'where'), and another for the layer index (the 'which layer'). This design is key to T2L's efficiency, allowing it to produce a complete, structured adapter on the fly.
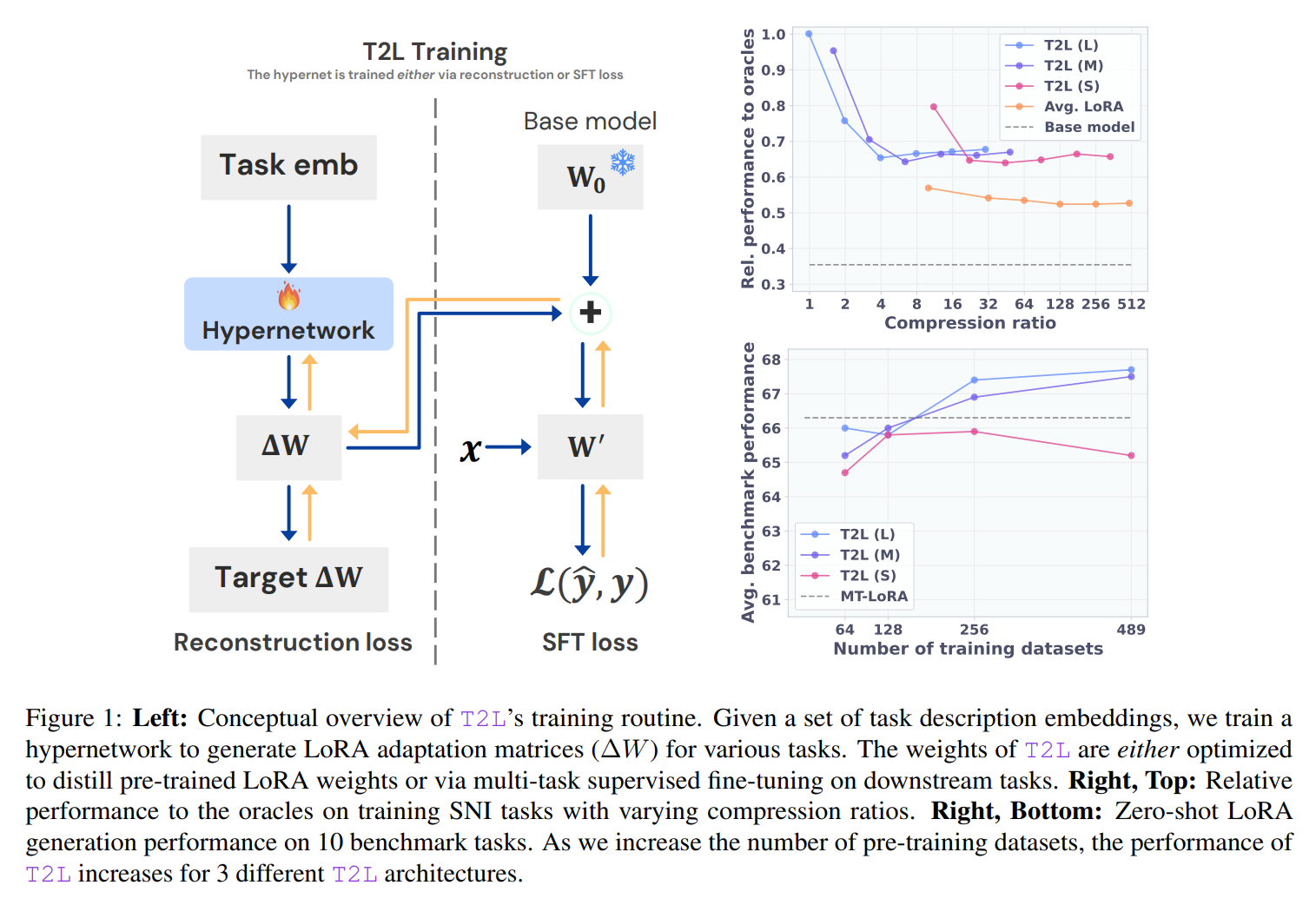
The authors propose two distinct training regimes for T2L:
LoRA Reconstruction: Here, T2L is trained to distill a library of pre-trained, task-specific LoRA adapters. This demonstrates an impressive capability for compression, where T2L can encode hundreds of LoRAs into its own, much smaller set of parameters.
Supervised Fine-Tuning (SFT): In this end-to-end approach, T2L is trained directly on a diverse distribution of downstream tasks. Instead of matching pre-existing weights, it learns to generate LoRA adapters that minimize the fine-tuning loss on those tasks.
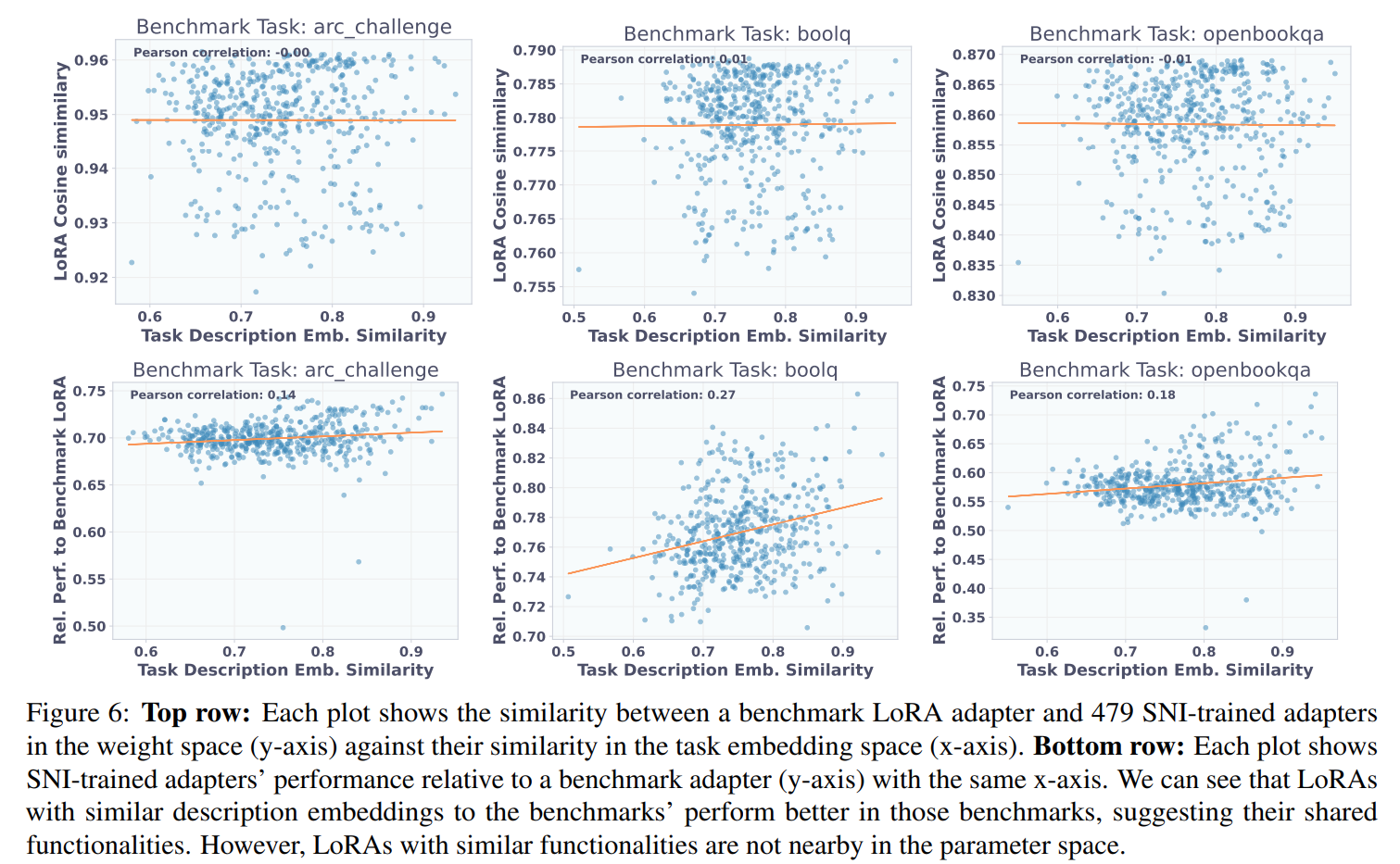
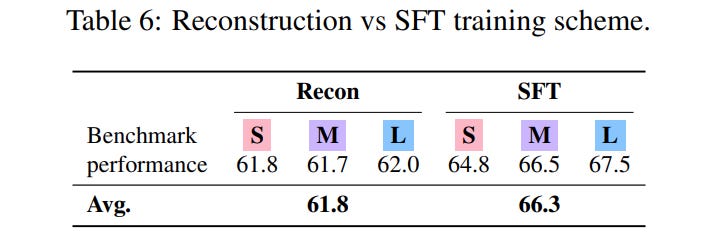
The superiority of the SFT training scheme stems from a critical insight, vividly illustrated in the paper's analysis. The authors show that while tasks might be semantically similar, the corresponding LoRA adapters trained via reconstruction are not necessarily close to each other in the high-dimensional weight space, exhibiting near-zero correlation (as shown in Figure 6). SFT, by contrast, is not forced to reconstruct specific weight layouts. Instead, it learns a more abstract, functional mapping from a task description to any effective adapter, allowing it to discover a more robust and generalizable latent space of adaptations.
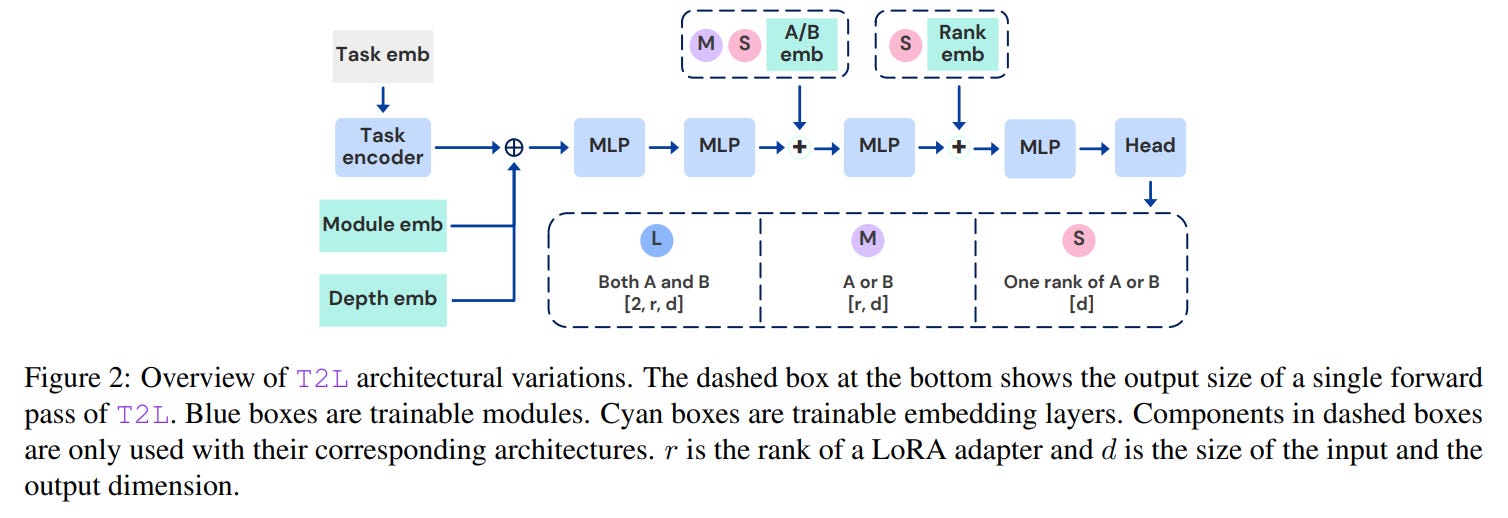
To explore practical trade-offs, the paper also presents three T2L architectural variants (L, M, and S) with different parameter counts. The largest, T2L-L, uses a dedicated output head to generate both low-rank matrices (A and B) simultaneously. T2L-M is more efficient, sharing a single output head, while the most parameter-efficient model, T2L-S, generates only a single rank of a matrix at a time. This exploration provides a practical blueprint for choosing the right hypernetwork size based on available resources and performance needs.
From Theory to Practice: Experimental Findings
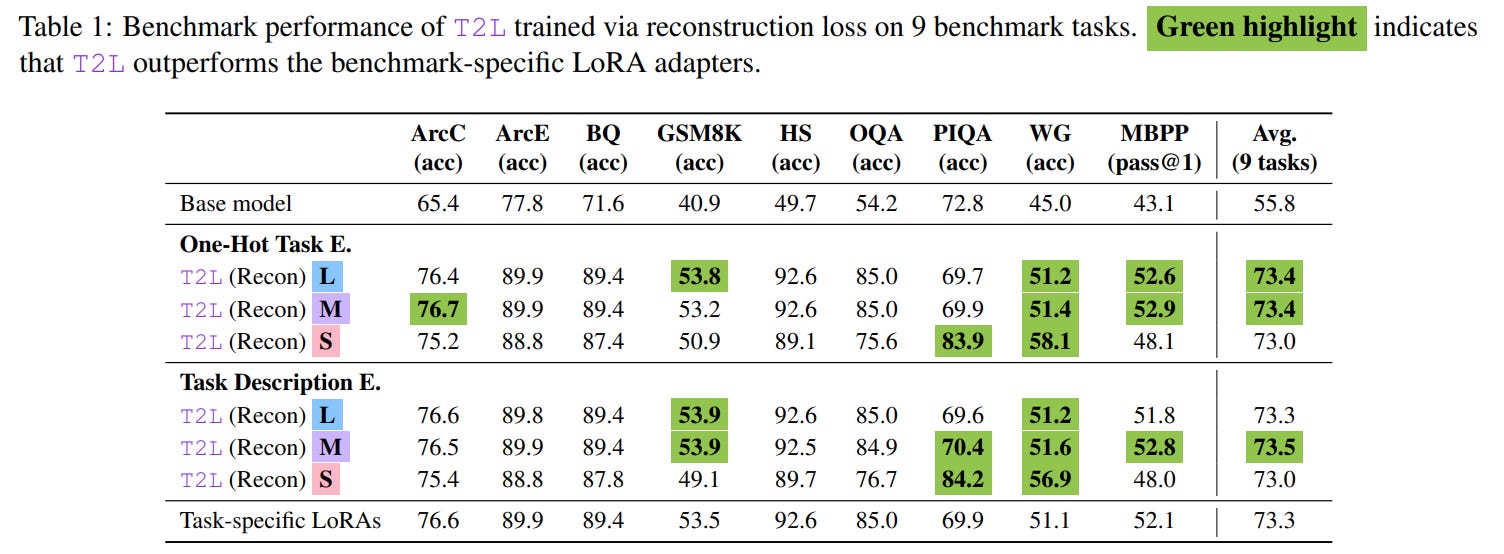
The experimental results validate the promise of the T2L framework. When trained via reconstruction, T2L not only successfully compresses a suite of LoRAs but can even slightly outperform the original, individually trained "oracle" adapters, as seen in Table 1. The authors attribute this to a form of regularization from the lossy compression, which may prevent overfitting present in the original adapters.
However, the most significant results come from the SFT-trained models. In a zero-shot setting, T2L consistently outperforms a range of strong baselines, including multi-task LoRA and few-shot in-context learning. For instance, the T2L-L model improves the average performance of a Mistral-7B-Instruct base from 55.8% to 67.7% across 10 benchmarks, surpassing the 66.3% achieved by a standard multi-task LoRA (as reported in Table 2).
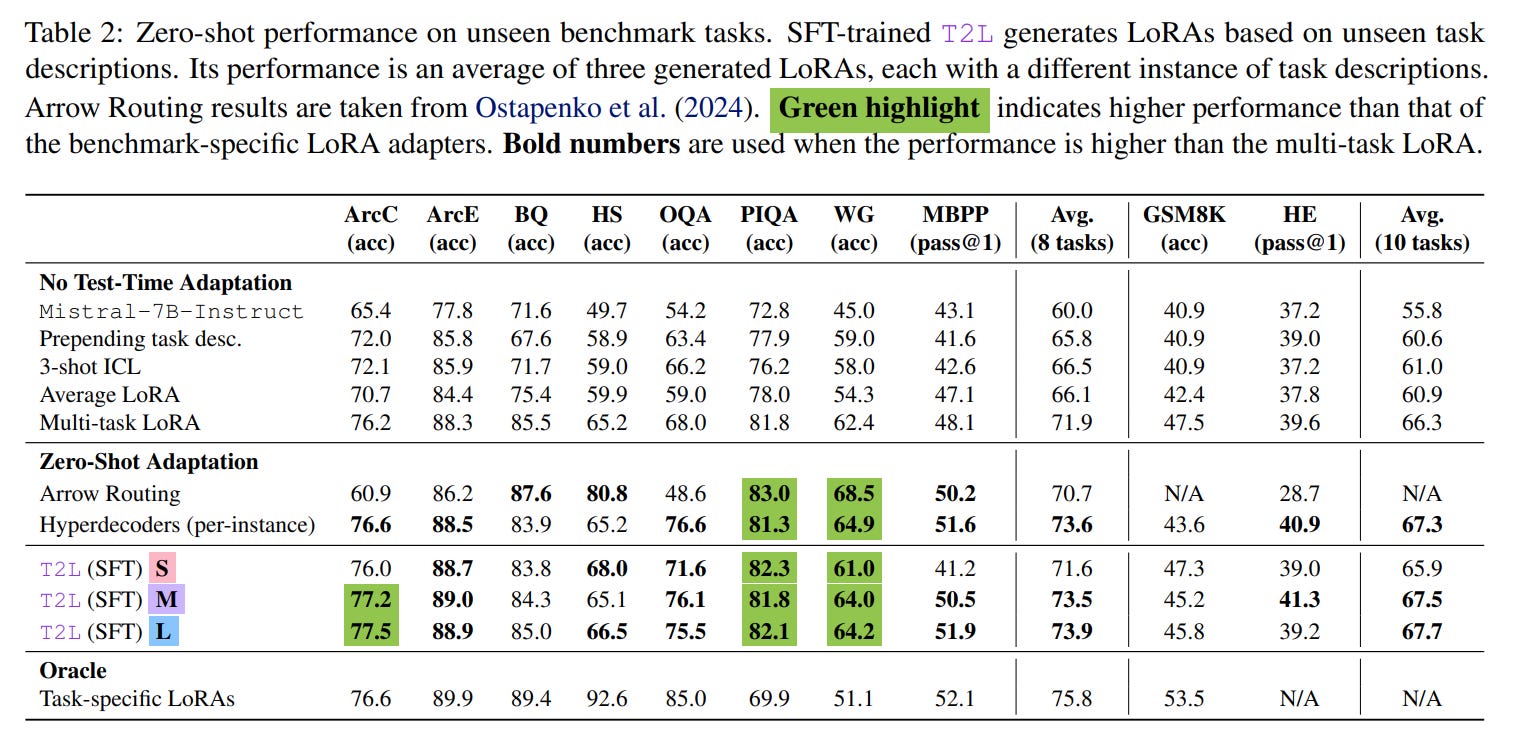
This generalization holds across different base models, including Llama-3.1-8B and Gemma-2-2B (Tables 7 and 8).
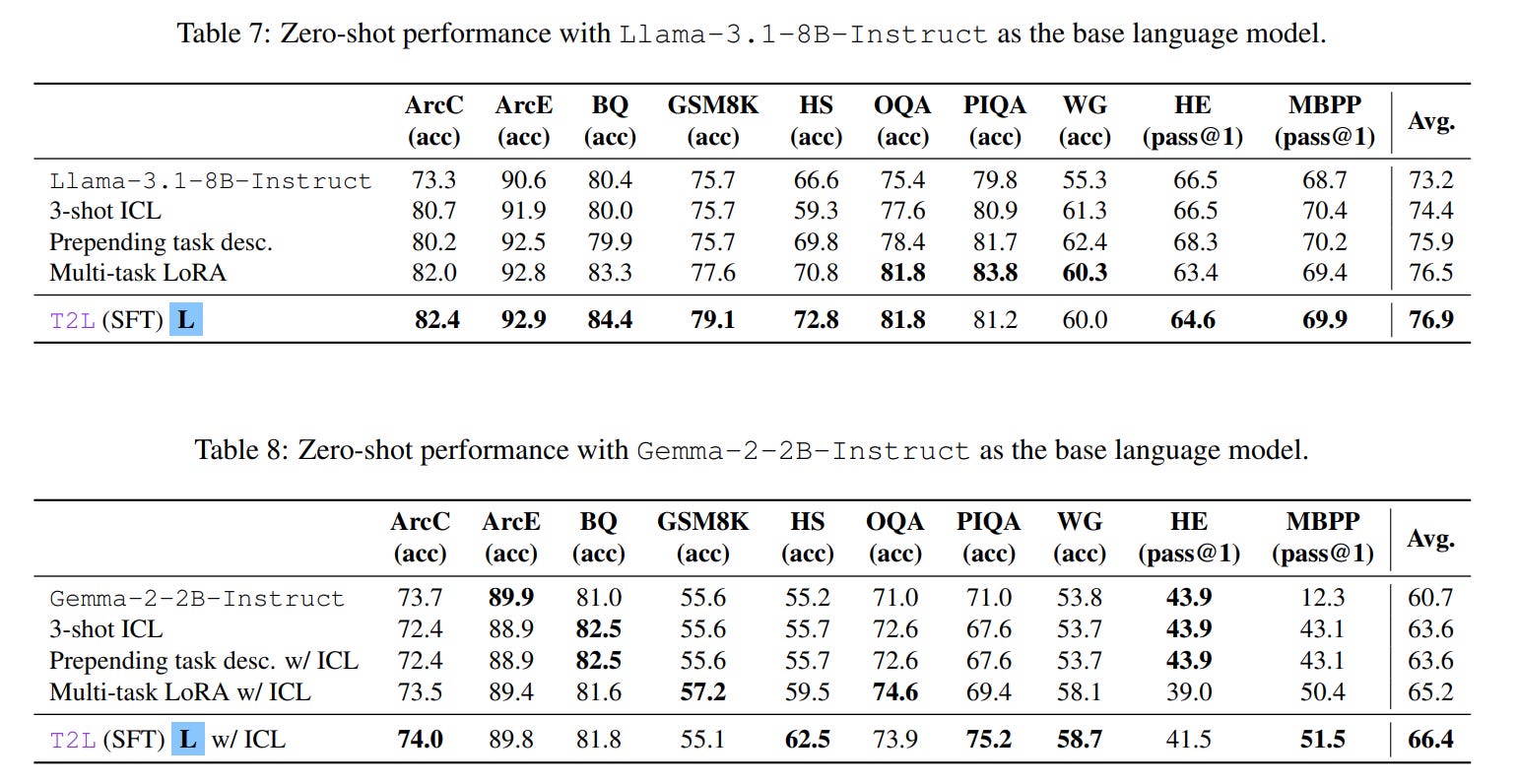
Ablation studies further strengthen these findings. Performance scales positively with the number of training tasks, and SFT proves decisively better than reconstruction for zero-shot generalization (Table 6).
Qualitative examples compellingly demonstrate the model's steerability, showing how different phrasings of a task description can lead the base LLM down different, yet still correct, reasoning paths (Figure 4).

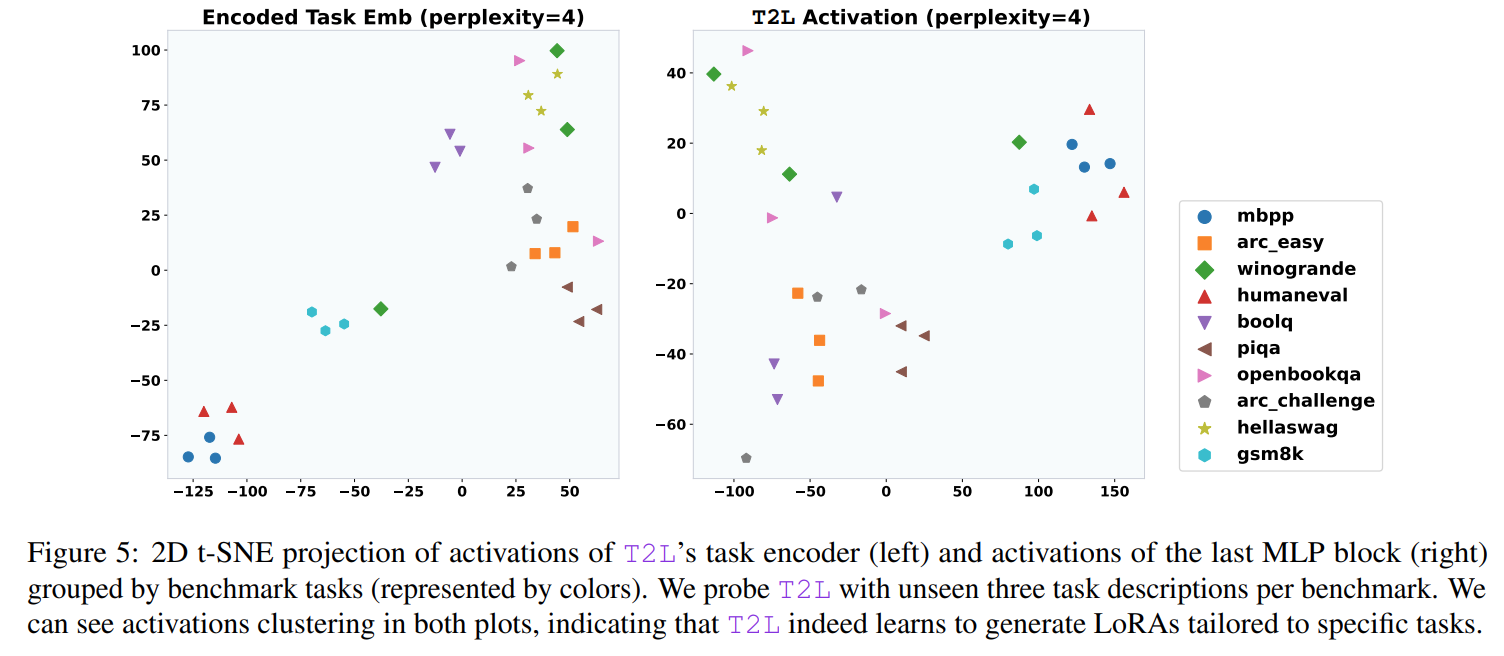
Furthermore, visualizations of T2L's internal activations confirm that it learns to generate distinct adapters for different tasks, with semantically similar tasks clustering together in the latent space (Figure 5).
Limitations and Future Horizons
The paper is commendably transparent about the method's limitations. A performance gap still exists between the zero-shot generated adapters and the oracle task-specific ones, indicating that "potent zero-shot adaptation" is a goal not yet fully reached. The model's effectiveness is also sensitive to the quality of the input task description; vague or unaligned prompts can degrade performance, a crucial consideration for real-world deployment. A noteworthy detail in the methodology is that the authors used GPT-4o-mini to generate the diverse set of task descriptions used for training. While this is a clever way to automate the creation of high-quality training data, it also highlights a potential dependency: the quality of the T2L hypernetwork is, in part, reliant on the quality of another large-scale model.
The authors identify several promising avenues for future work. Can a T2L model trained on a small base LLM be transferred to a larger one? Could this approach be extended beyond generating LoRA parameters to more efficient modulation techniques, such as directly manipulating model activations? These questions point toward a rich research landscape.
Conclusion
"Text-to-LoRA" presents a significant and practical advancement in the field of model adaptation. By enabling instant, on-the-fly specialization from natural language, it offers a compelling path toward more dynamic, accessible, and user-friendly AI systems. Beyond the immediate technical achievement, this work opens the door to a new paradigm of human-AI interaction. Imagine truly personalized AI agents that adapt to a user's specific needs and style in real-time based on simple conversation, or development platforms where new AI capabilities are not coded but simply described in plain English. T2L provides a tangible step toward this future, where the barrier to customizing powerful AI is not technical expertise, but simply the clarity of one's instructions. It is a valuable contribution that is likely to inspire a new wave of research into generative and language-driven model adaptation.
Editor note: I personally expect the next generations of LLMs to have adaptation capabilities like T2L embedded. It’s so cool from a business perspective.