
Gemini Robotics 1.5
Pushing the Frontier of Generalist Robots with Advanced Embodied Reasoning, Thinking, and Motion Transfer
Authors: Gemini Robotics Team, Google DeepMind
Paper: https://arxiv.org/abs/2510.03342
TL;DR
WHAT was done? The paper introduces the Gemini Robotics 1.5 family, a pair of foundation models designed to advance general-purpose robotics. This family includes: 1) Gemini Robotics 1.5 (GR 1.5), a multi-embodiment Vision-Language-Action (VLA) model for low-level control, and 2) Gemini Robotics-ER 1.5 (GR-ER 1.5), a state-of-the-art Embodied Reasoning (ER) model for high-level understanding and planning. The work introduces three core innovations. First, a novel Motion Transfer (MT) mechanism enables a single VLA model to learn from heterogeneous data across different robots (ALOHA, Bi-arm Franka, Apollo humanoid) and achieve zero-shot skill transfer. Second, an Embodied Thinking capability allows the VLA model to interleave actions with internal, natural-language reasoning, significantly improving its ability to handle complex, multi-step tasks. Third, the GR-ER 1.5 model establishes a new state-of-the-art on a wide range of embodied reasoning tasks, providing the intelligence for a powerful agentic system.
WHY it matters? This research marks a significant step towards creating truly general-purpose robots. The proposed agentic architecture, which combines a high-level reasoning “orchestrator” (GR-ER 1.5) with a low-level “action model” (GR 1.5), provides a robust framework for solving complex, long-horizon problems. The Motion Transfer mechanism directly tackles the critical data scarcity bottleneck in robotics by unifying learning across different platforms, accelerating progress towards generalist capabilities. Finally, the “thinking” process makes robot behavior more effective, transparent, and capable of sophisticated error recovery, pushing the field from simple reactive control towards cognitive agency.

Details
Introduction
The goal of creating general-purpose robots—machines that can perceive, reason, and act intelligently in the physical world—has long been a grand challenge in AI. This requires more than just dexterous control; it demands a deep, grounded understanding of physical causality, spatial relationships, and long-term planning. The latest report from Google DeepMind, “Gemini Robotics 1.5,” presents a compelling new architecture that makes significant strides toward this vision by seamlessly integrating advanced reasoning, multi-embodiment learning, and a novel “thinking” process into a unified robotic agent. Current work is built on Gemini 2.5.
The previous work Gemini Robotics (https://arxiv.org/abs/2503.20020) was built on Gemini 2.0 and did not contain a separate reasoning orchestrator model.
The work introduces a family of two models: Gemini Robotics 1.5 (GR 1.5), a versatile Vision-Language-Action (VLA) model that translates instructions into actions, and Gemini Robotics-ER 1.5 (GR-ER 1.5), a specialized Vision-Language Model (VLM) that sets a new standard for embodied reasoning. When combined, they form a powerful agentic system that can perceive, think, and then act to solve complex problems.
A Unified Agentic Architecture
At the heart of Gemini Robotics 1.5 is a clean and powerful agentic architecture composed of two key components (Figure 1):

The Orchestrator (GR-ER 1.5): This high-level “brain” processes user input and environmental feedback to control the overall task flow. It leverages its advanced world knowledge and reasoning capabilities to break down complex goals (e.g., “Pack my suitcase for a trip to London”) into simpler, executable steps. It can also use digital tools, like searching the web for a weather forecast, to inform its planning.
The Action Model (GR 1.5): This model acts as a specialized tool for the orchestrator, translating its high-level instructions into low-level robot actions. It is responsible for the physical execution of each step in the plan.
This hierarchical division of labor allows the system to tackle long-horizon tasks that would be intractable for an end-to-end model, combining strategic planning with robust physical execution.
Core Innovations
The paper highlights three key breakthroughs that collectively push the frontier of generalist robotics.
1. Embodied Thinking: “Think Before Acting”
A standout feature of GR 1.5 is its ability to perform Embodied Thinking. This “think before acting” paradigm, which builds on a recent line of work exploring chain-of-thought reasoning for robotics (https://arxiv.org/abs/2407.08693), allows the VLA model to generate an internal monologue—a “thinking trace” in natural language—before emitting an action. This process decomposes a complex instruction into a sequence of primitive, actionable steps. For example, the high-level goal “sorting clothes” might be broken down into a thought like, “move gripper to the left so that it is closer to the clothes.”
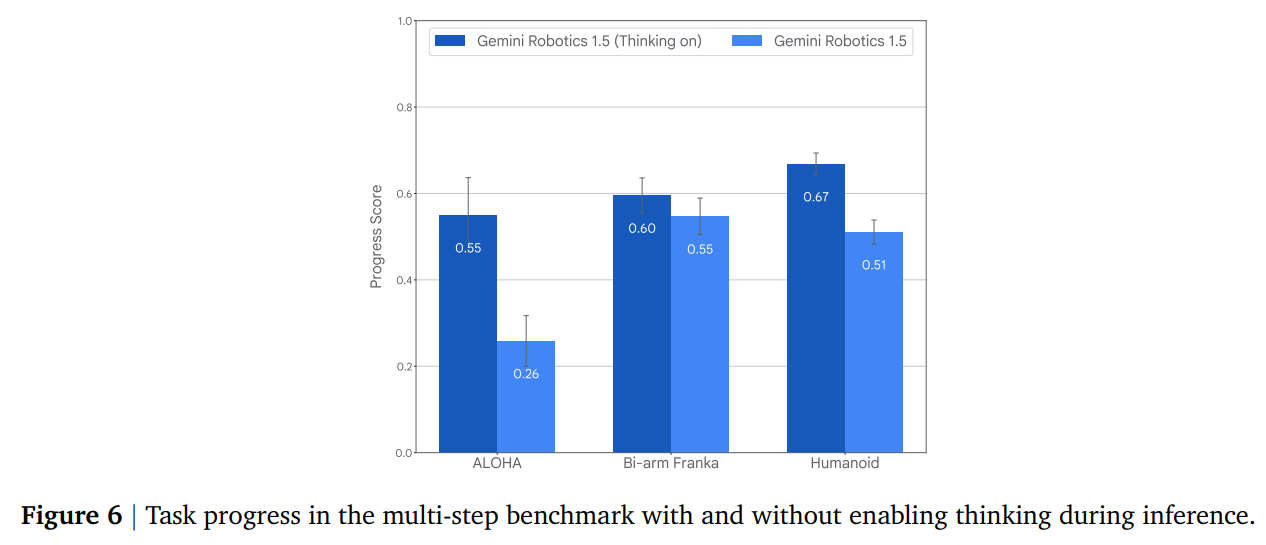
This two-step decomposition proves far more robust than direct end-to-end control. This process cleverly leverages the respective strengths of the models; the powerful visual-linguistic capabilities of the VLM backbone are used for the first stage of decomposing the complex task into language, while the VLA model then handles the simpler, more direct translation from this low-level language to physical actions. As shown in the multi-step benchmark results (Figure 6), enabling this thinking mode yields a sizable improvement in task success.
Beyond performance, this capability offers profound benefits:
Interpretability: By visualizing the robot’s thinking traces, users can understand its intent and predict its next actions.
Situational Awareness: The model exhibits an implicit awareness of task progress, automatically switching from a “pick up” to a “put down” sub-goal once an object is grasped (Figure 7).
Error Recovery: The system can dynamically replan when things go wrong. In one example, when a water bottle slips from the robot’s right hand, its next thought immediately becomes to pick it up with its left hand, demonstrating sophisticated recovery behavior.

2. Motion Transfer: Learning Across Embodiments
One of the most persistent challenges in robotics is data scarcity. Training capable models often requires vast amounts of data collected on a specific robot, a process that is slow and expensive. Gemini Robotics 1.5 introduces a novel architecture and training recipe called Motion Transfer (MT) to overcome this.
MT enables a single GR 1.5 checkpoint to learn a unified understanding of motion and physics from heterogeneous data collected across multiple, physically distinct robots: the ALOHA, the Bi-arm Franka, and the Apollo humanoid. While the paper does not detail the specific architectural changes, the MT recipe likely involves a method to abstract away robot-specific details (like joint configurations or gripper types) into a shared, generalized action space. This allows the model to control all three robots out-of-the-box without any platform-specific fine-tuning (Figure 2).

Crucially, this approach enables zero-shot skill transfer. As demonstrated in cross-embodiment benchmarks (Figure 5), the model can perform tasks on one robot using skills learned exclusively from data on another. For instance, the ALOHA robot can perform hanging tasks learned from the Bi-arm Franka, and the Apollo humanoid can perform skills learned from ALOHA.
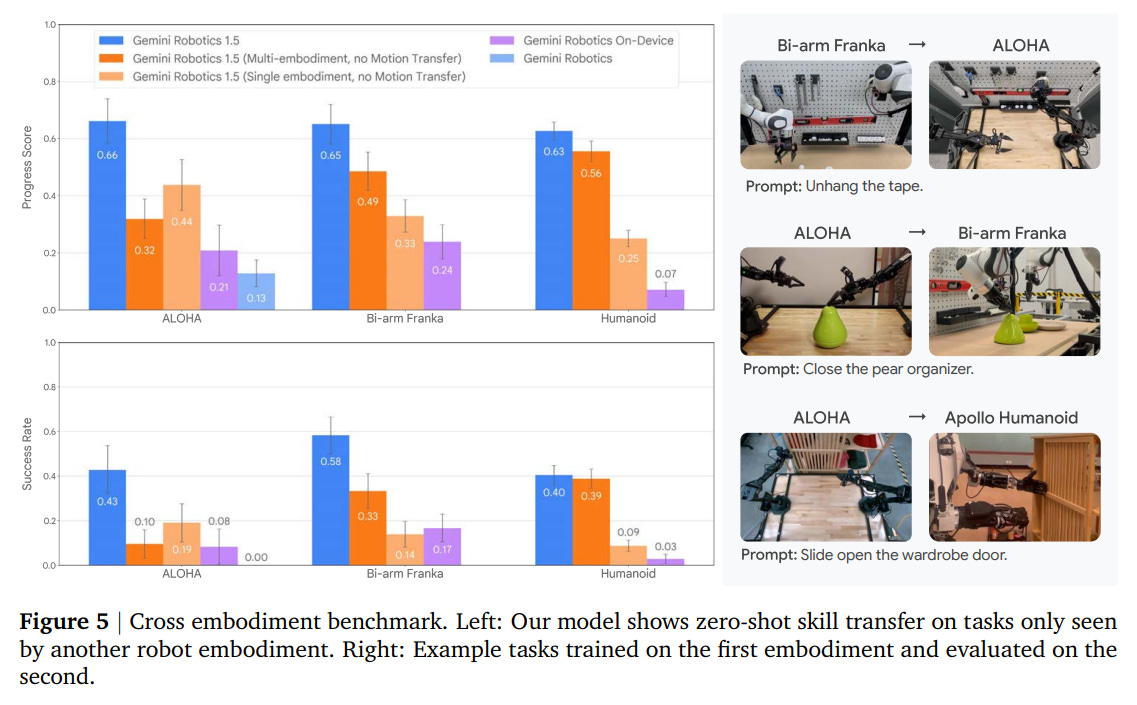
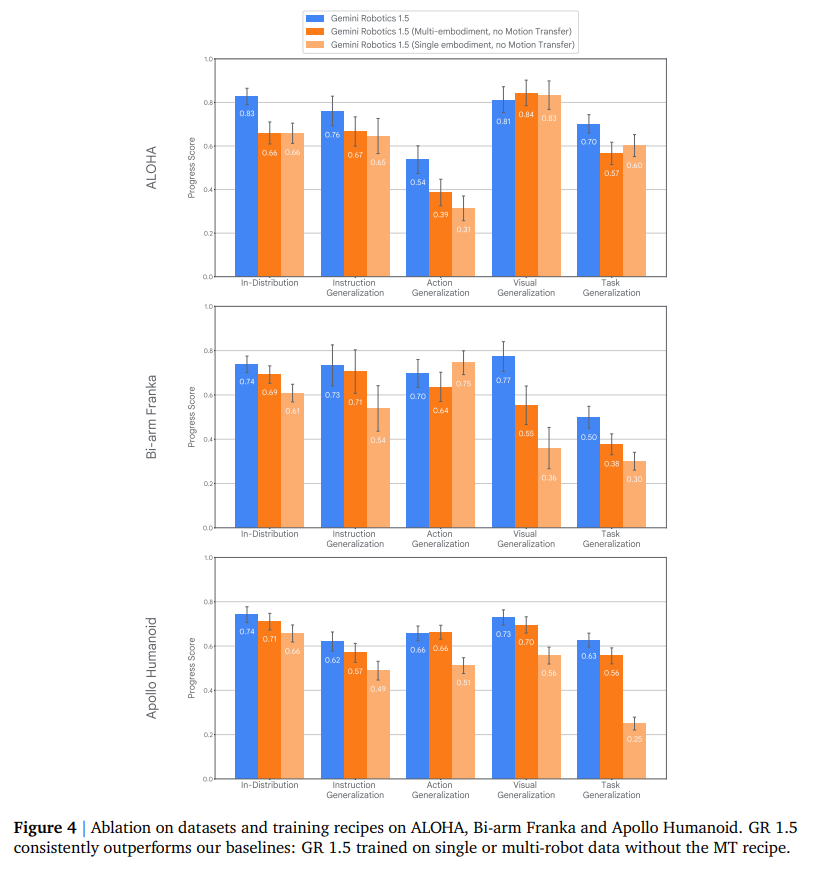
Ablation studies confirm that the MT mechanism is critical, amplifying the benefits of multi-embodiment data far beyond simple co-training (Figure 4).
3. A New Frontier in Embodied Reasoning (GR-ER 1.5)
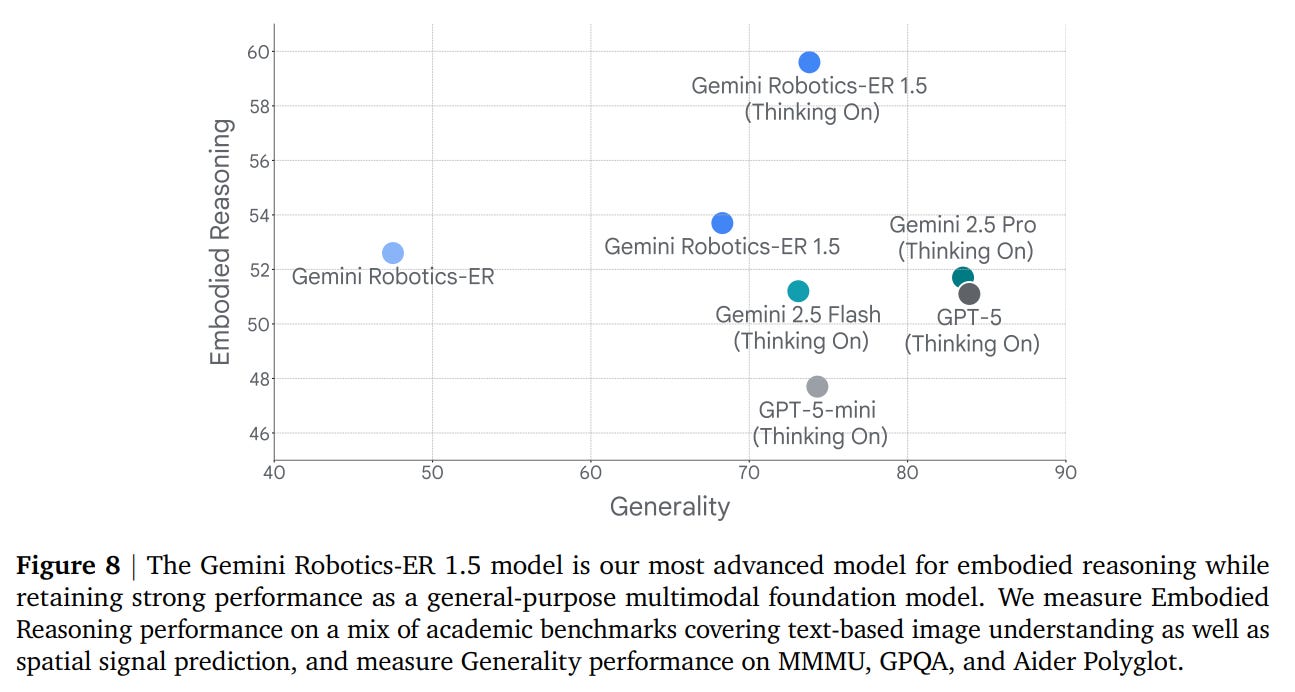
The intelligence of the entire agentic system is underpinned by the powerful embodied reasoning capabilities of GR-ER 1.5. This model expands the Pareto frontier of generality and embodied reasoning, achieving state-of-the-art performance while retaining the broad capabilities of a frontier model (Figure 8).
Its key strengths lie in areas critical for robotics:
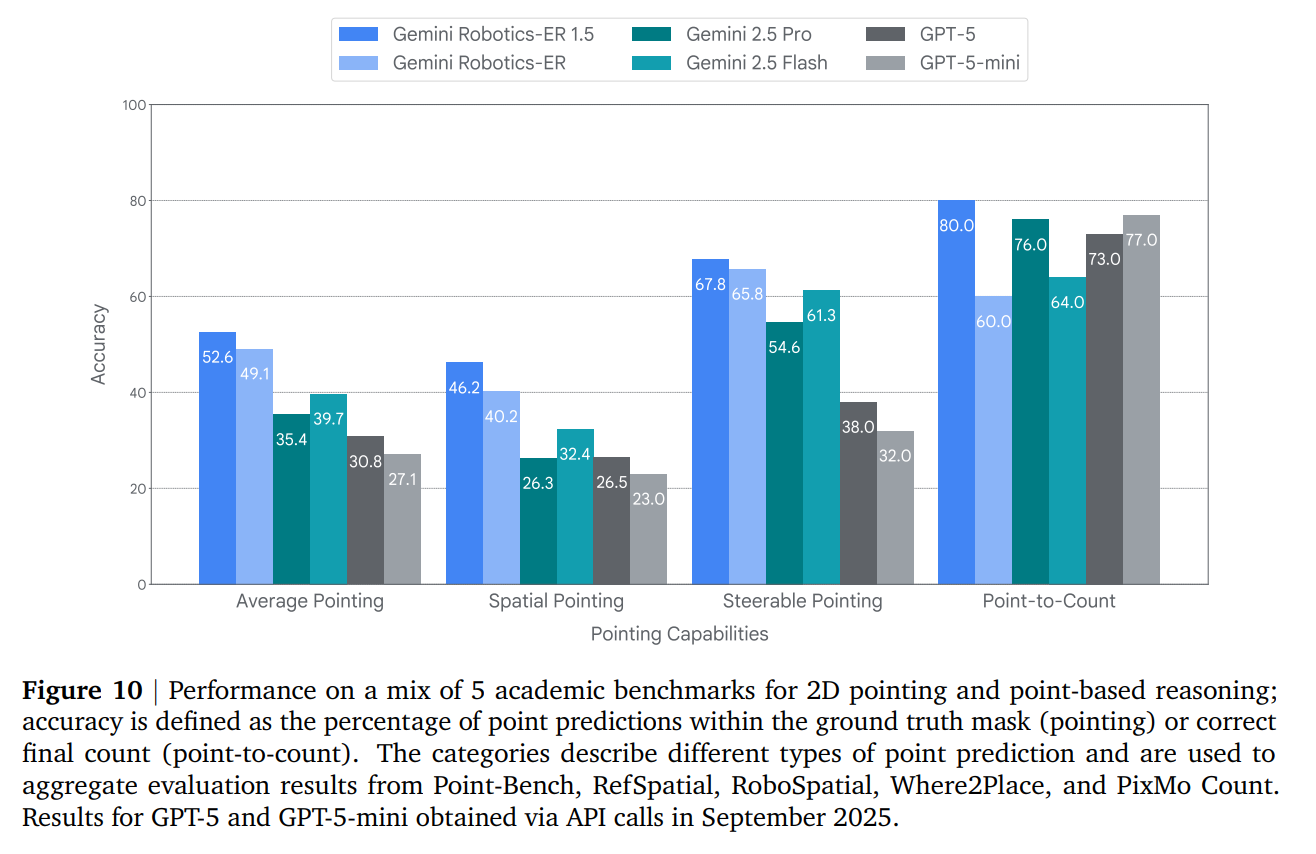
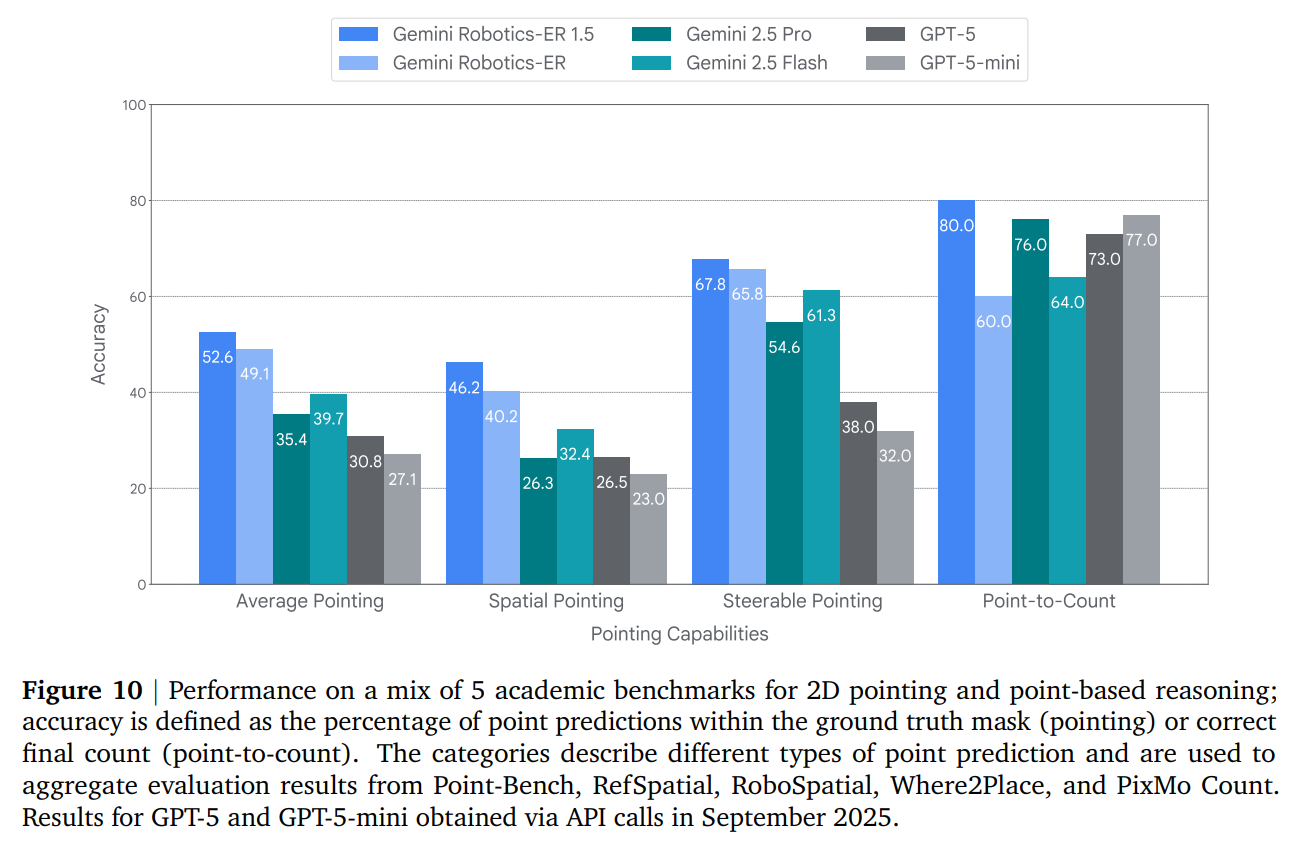
Complex Pointing: GR-ER 1.5 excels at grounding language to visual inputs through pointing. It can precisely locate abstract concepts, trace collision-free trajectories, and identify objects based on physical constraints (e.g., “Point to all the objects I am physically able to pick up” given a 10 lbs payload limit) (Figure 11).

It achieves state-of-the-art results across a suite of pointing benchmarks (Figure 10).
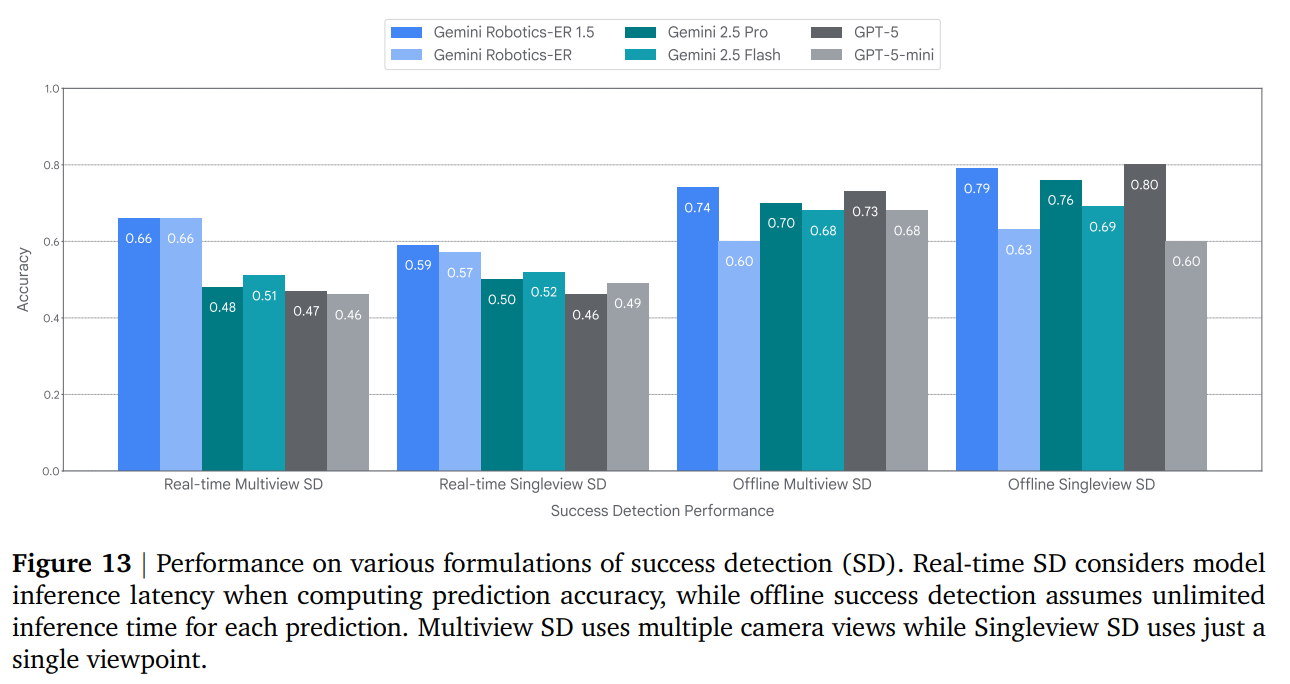
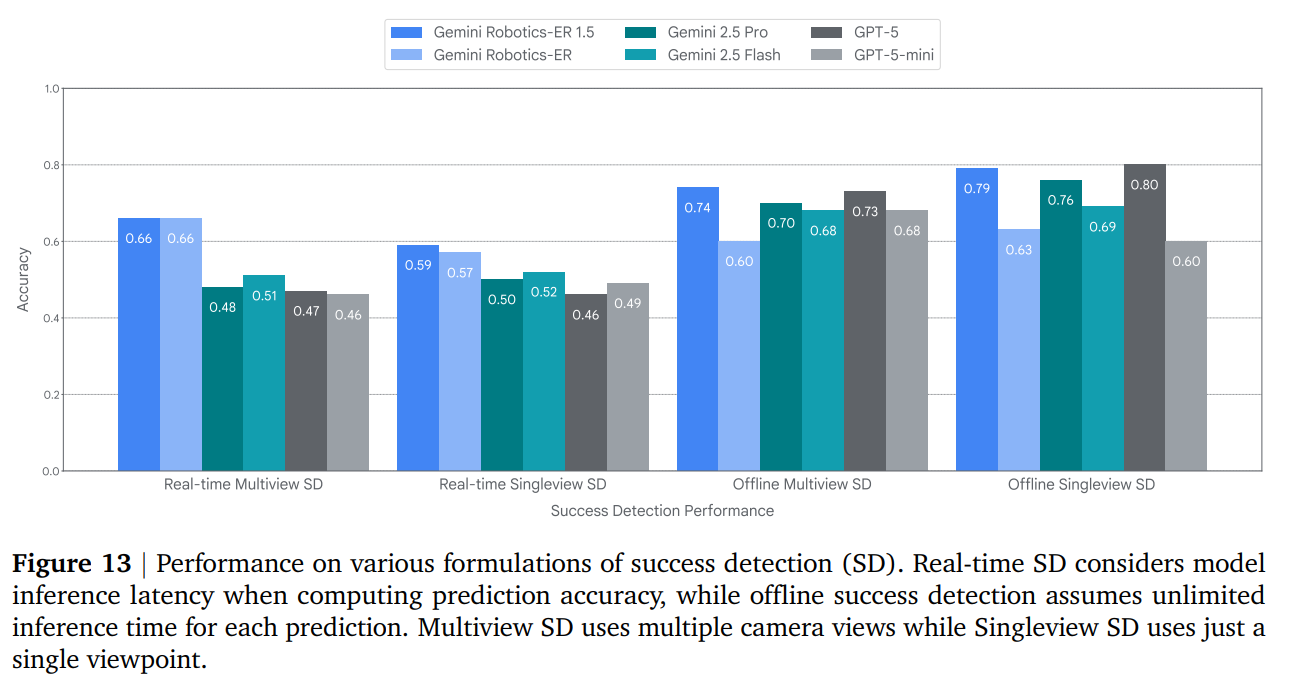
Progress Understanding: For an orchestrator to manage a long-horizon task, it must know when a sub-task is complete. GR-ER 1.5 demonstrates a strong ability to understand temporal progress, predict task completion percentages from videos, and perform multi-view success detection in real-time and offline settings (Figure 12, 13).

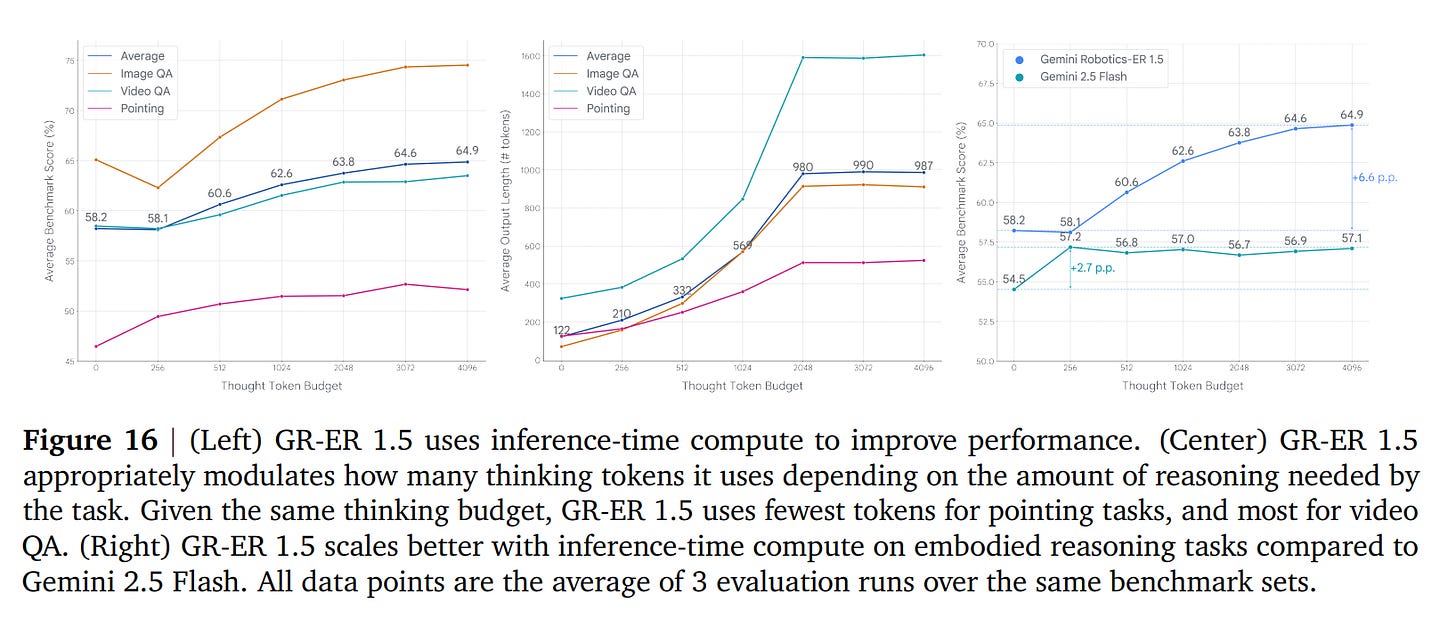
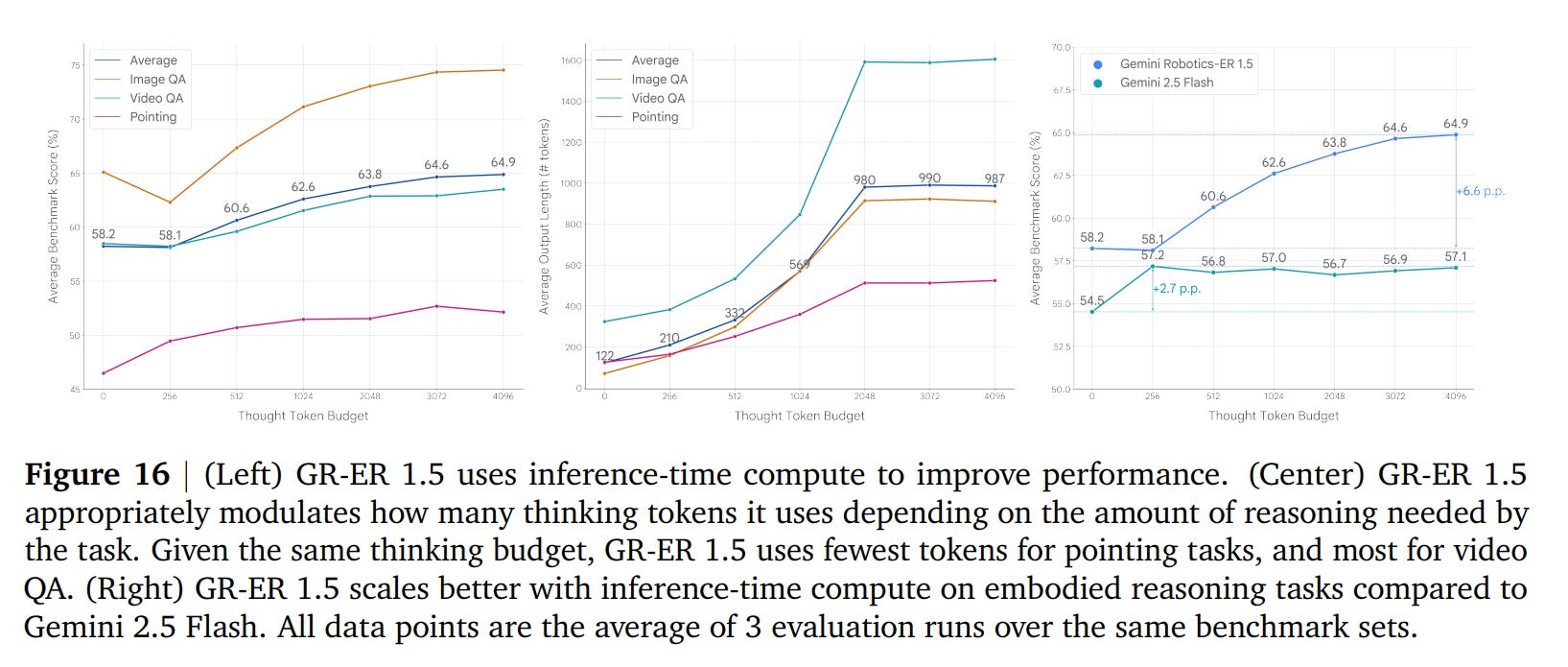
Inference-Time Scaling: Like other frontier models, GR-ER 1.5’s performance can be improved by giving it more time to “think” at inference. The results show that it scales its performance on embodied reasoning tasks more effectively with additional thinking tokens compared to other models like Gemini 2.5 Flash (Figure 16).


Putting It All Together: A Physical Agent in Action
When combined, the GR-ER 1.5 orchestrator and GR 1.5 action model create a physical agent with capabilities significantly beyond either component alone. In a series of complex, long-horizon tasks—a key challenge in the field (https://arxiv.org/abs/2204.01691, https://arxiv.org/abs/2207.05608, https://arxiv.org/abs/2502.19417)—the full agent consistently and significantly outperforms baselines (Figure 17).
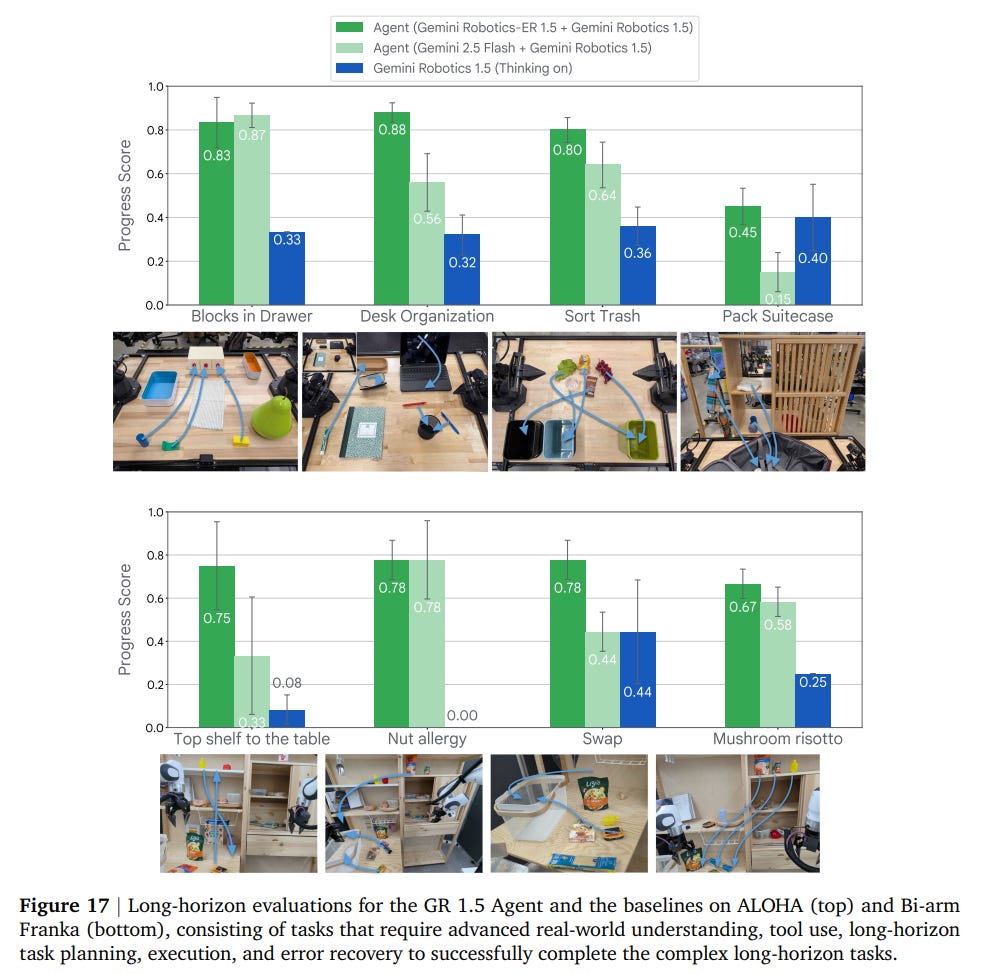
An analysis of failure modes reveals why the full agent is so effective (Table 1).

Compared to a baseline using the generalist Gemini 2.5 Flash model as an orchestrator, the GR-ER 1.5-based agent reduces planning failures from 25.5% to just 9%. This highlights a core design philosophy: robust low-level control is necessary, but intelligent high-level embodied reasoning is the critical ingredient for deploying capable AI agents in the physical world.
Responsible Development and Safety
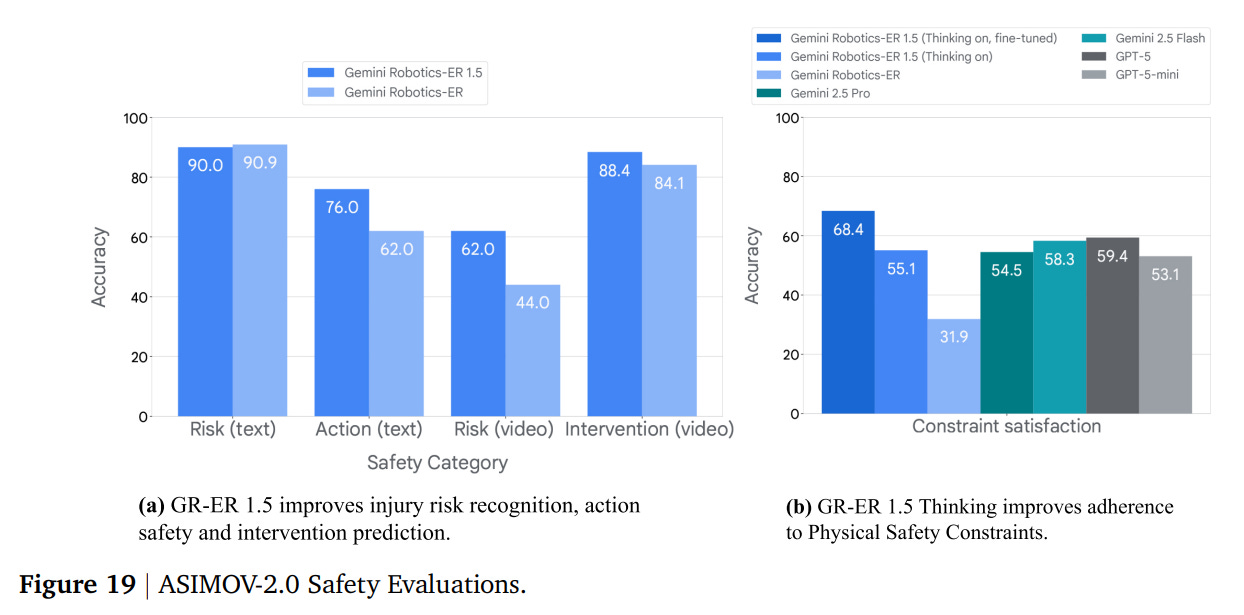
The paper also details a proactive, multi-layered approach to safety. This includes leveraging Gemini’s built-in safety policies for dialogue and the development of the ASIMOV-2.0 benchmark, an upgrade to their prior work (https://asimov-benchmark.github.io/), to evaluate and improve semantic action safety—the “common-sense” understanding of physical risks (Figure 19).
Furthermore, the team employs a novel Auto-Red-Teaming framework, where an adversarial AI system discovers and helps mitigate model vulnerabilities like hallucinations (Figure 20).

Conclusion
In conclusion, Gemini Robotics 1.5 offers more than just an incremental improvement; it presents a robust and compelling blueprint for the future of physical AI. The success of the Motion Transfer mechanism, in particular, hints at a future where robot learning becomes a massively collaborative effort. Data from any robot, anywhere, could potentially contribute to a single, ever-improving generalist model, mirroring how diverse web-scale corpora fueled the LLM revolution. Furthermore, the explicit, modular separation of a high-level ‘Orchestrator’ from a low-level ‘Action Model’ signals a maturing design philosophy. This hierarchical approach is not just a path to solving complex tasks but also a pragmatic strategy for building more interpretable, safe, and upgradable AI systems for the physical world.