Authors: Junyoung Seo, Hyunwook Choi, Minkyung Kwon, Jinhyeok Choi, Siyoon Jin, Gayoung Lee, Junho Kim, JoungBin Lee, Geonmo Gu, Dongyoon Han, Sangdoo Yun, Seungryong Kim, and Jin-Hwa Kim
Paper: https://arxiv.org/abs/2603.15583v1
Code: https://seoul-world-model.github.io
Affiliations: KAIST AI, NAVER AI Lab, SNU AIIS
TL;DR
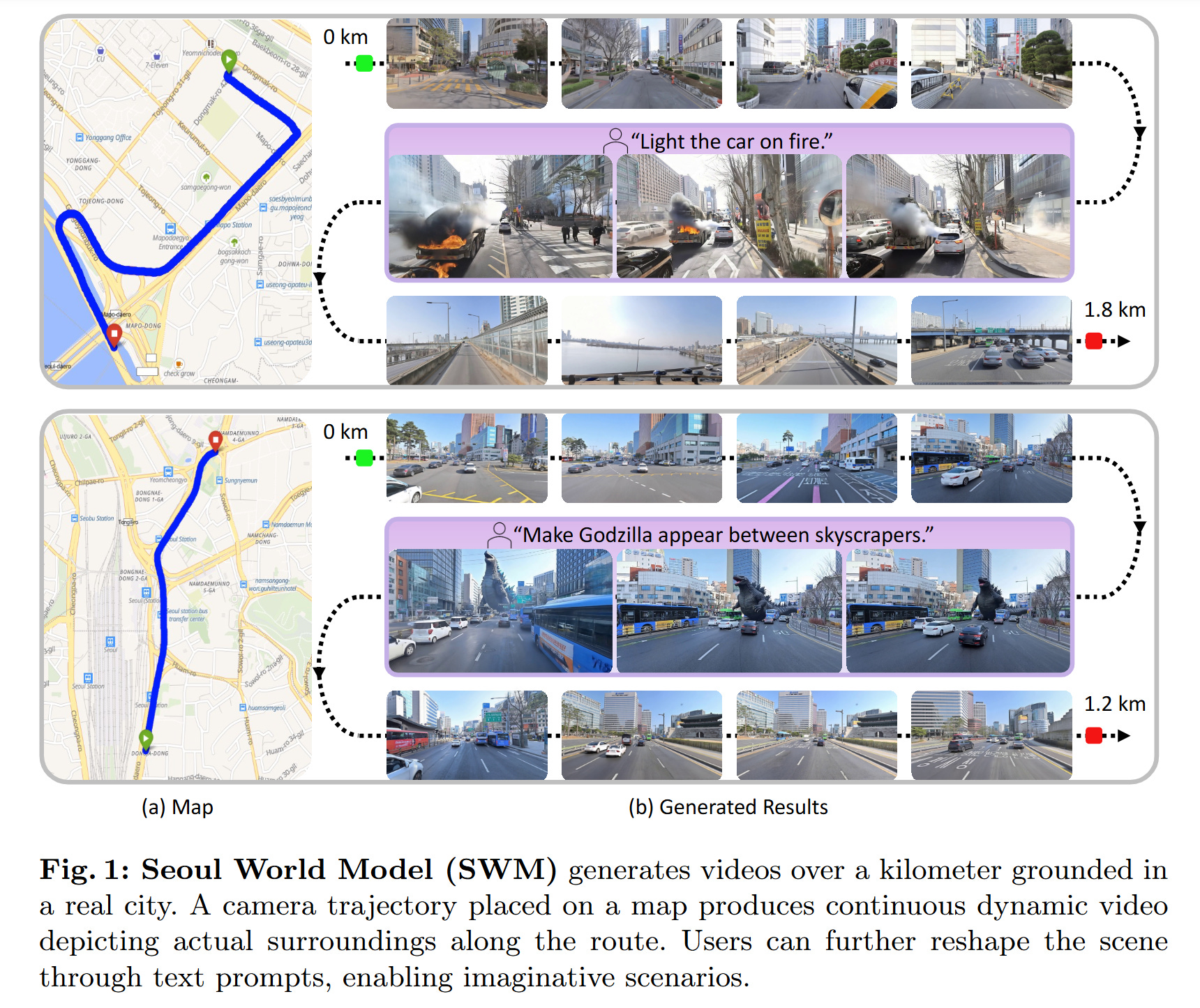
WHAT was done? The paper introduces the Seoul World Model (SWM), a 2-billion parameter city-scale video generation system. Built on a Diffusion Transformer (DiT), SWM uses a geo-indexed retrieval mechanism to anchor its autoregressive video generation to actual, physical street-view data of Seoul, rather than fabricating imagined environments.
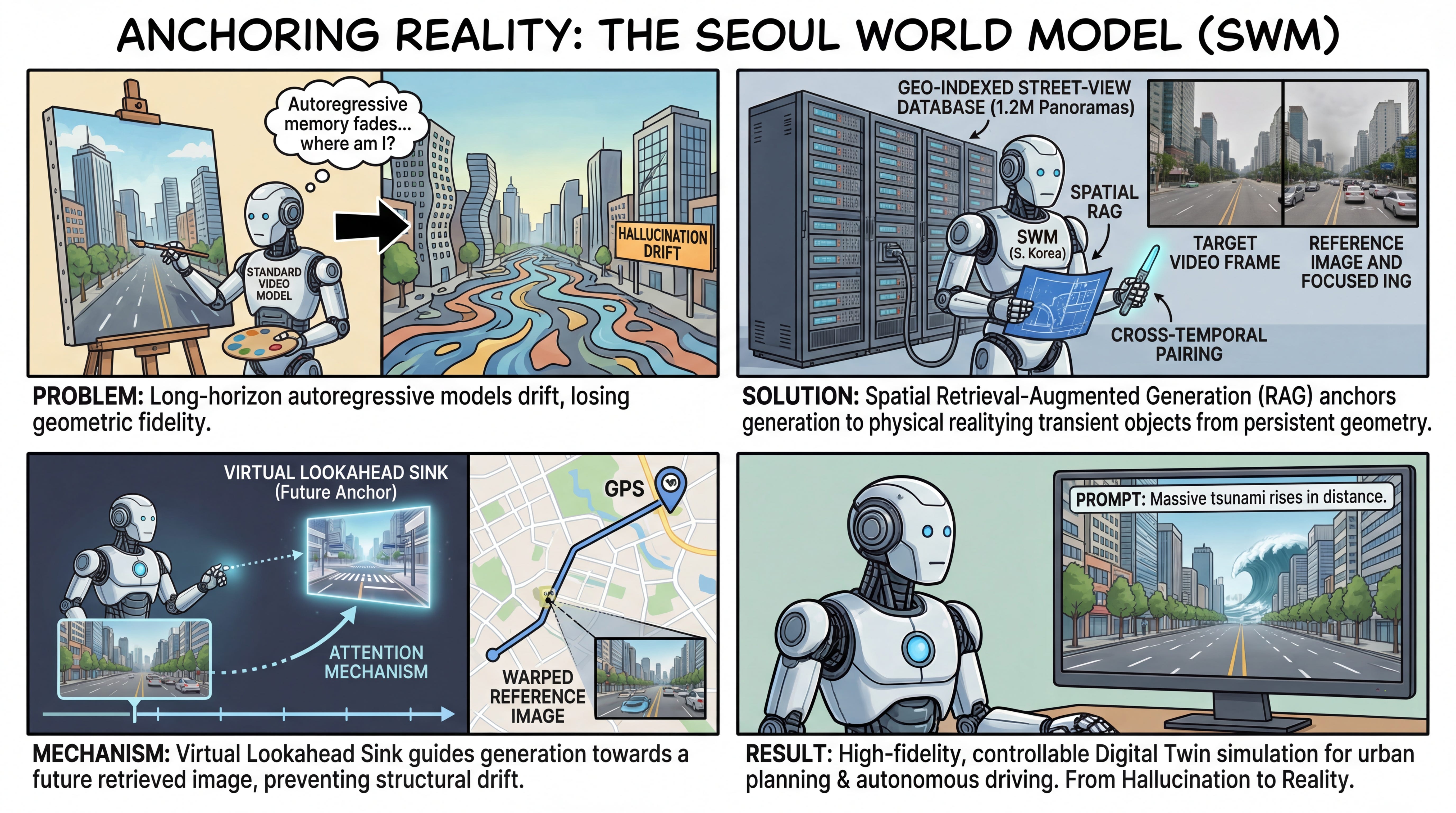
WHY it matters? Existing generative world models suffer from an inability to maintain geographic and topological fidelity over long temporal horizons; once a camera turns a corner, the model invents the street. By grounding generation in real-world spatial data via retrieval-augmented generation (RAG), SWM bridges the gap between static 3D city reconstructions and dynamic video simulation. This provides a structural foundation for high-fidelity urban planning visualizations and reliable edge-case simulation for autonomous driving.
Executive summary: For research leaders and domain experts, this work represents a critical transition from purely parametric, hallucinated world models to physically grounded “digital twins.” By introducing a mechanism to dynamically retrieve future visual frames and inject them as attention anchors, the system effectively solves the long-horizon drift problem typical of autoregressive video generation. This validates spatial RAG as a necessary architecture for persistent, large-scale environmental simulation.
Details
Escaping the Hallucination Bottleneck in World Simulators
The fundamental bottleneck in current video world models is their reliance on pure parametric memory to simulate environments. While recent systems generate visually plausible physics and interactions, they operate in a topographical vacuum. Given a starting image, everything beyond the immediate field of view is imagined. Over long autoregressive rollouts, these models accumulate errors, leading to structural drift and topological morphing. This paper addresses this delta head-on by proposing a method to ground simulated generation in specific, physical locations. Compared to recent baselines like Aether and DeepVerse, which attempt to build geometric consistency from self-generated history, SWM leverages a massive external database of geo-indexed street-view panoramas to anchor the generative process to empirical reality.