
How Transparent is DiffusionGemma?
Authors: Joshua Engels, Callum McDougall, Bilal Chughtai, Janos Kramar, Senthoran Rajamanoharan, Cindy Wu, Arthur Conmy, Asic Q Chen, Jean Tarbouriech, Min Ma, Brendan O’Donoghue, João Gabriel Lopes de Oliveira, Rohin Shah, Neel Nanda
Paper: https://arxiv.org/abs/2606.20560
Code: https://github.com/google-deepmind/serial_depth
Model: https://ai.google.dev/gemma/docs/diffusiongemma/model_card
TL;DR
WHAT was done? The authors present a rigorous transparency audit of Google DeepMind’s DiffusionGemma, a newly released 26B parameter text diffusion model. They analyze its internal reasoning dynamics by decomposing transparency into opaque serial depth, variable transparency, monitorability, and algorithmic transparency, and introduce a technique to compress continuous self-conditioning bottlenecks into interpretable discrete tokens.
WHY it matters? As frontier models transition from autoregressive, human-readable chains of thought to continuous latent reasoning paradigms, we risk losing the ability to monitor and govern them. This work provides an optimistic framework, showing that simple logit-lens modifications can map continuous latent steps to discrete, interpretable tokens with negligible loss in capability, while exposing novel non-chronological cognitive behaviors that safety monitors must prepare for.

Details
The Latent Reasoning Bottleneck
Modern frontier AI safety relies heavily on the transparency of natural language reasoning. In standard autoregressive systems, chain-of-thought protocols externalize a model’s intermediate cognitive steps, allowing external safety monitors to check for reward hacking, sycophancy, or prompt injections. However, the emergence of text diffusion architectures like DiffusionGemma threatens this paradigm. By refining an entire canvas of tokens simultaneously in a continuous latent space over multiple denoising steps, these models perform a substantial portion of their computation in a medium that is, by default, human-incomprehensible.
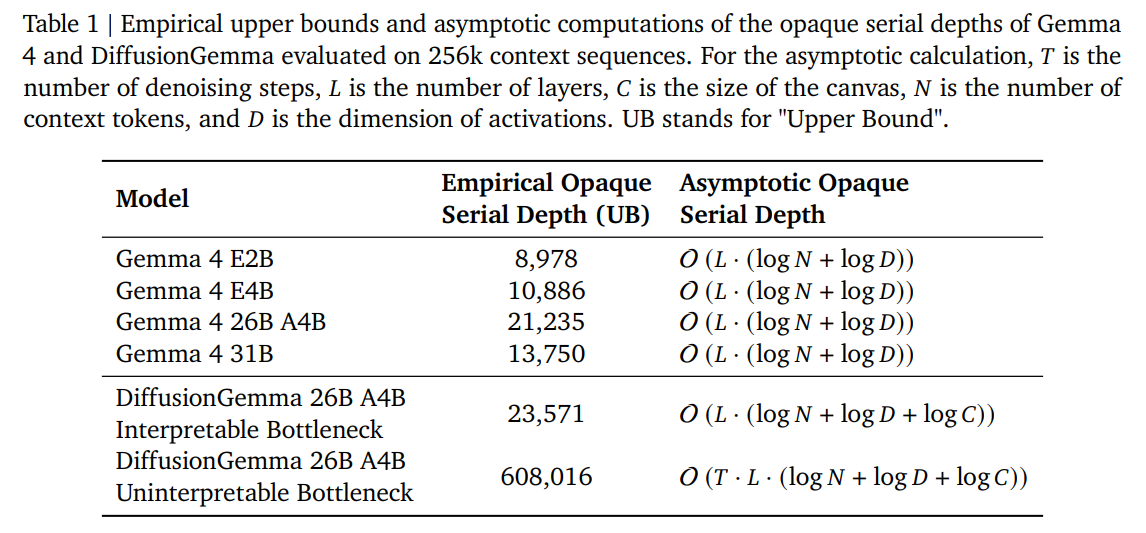
To quantify this concern, the authors utilize the metric of Opaque Serial Depth, which measures the maximum length of serial computation a neural network can execute without passing through an interpretable text bottleneck. Naively, if the continuous representations passed between denoising steps are treated as uninterpretable, DiffusionGemma exhibits an empirical serial depth that is 28.6 times higher than its autoregressive sibling, Gemma 4. This gap highlights a severe auditability deficit: a model operating with high opaque serial depth could easily harbor obfuscated or deceptive reasoning strategies that remain invisible to post-hoc output monitors.
First Principles: Formulating the Denoising State
To address this challenge, we must model DiffusionGemma’s architecture from first principles. Unlike typical transformers that generate one token at a time, DiffusionGemma takes a prompt vector p=(p1,…,pN) and iteratively refines an output canvas consisting of C tokens. Between each denoising step t∈{1,…,T}, the network passes the current discrete token canvas ot−1∈[V]C and a continuous self-conditioning matrix St−1∈RC×dmodel, where dmodel is the activation dimension and V is the vocabulary.
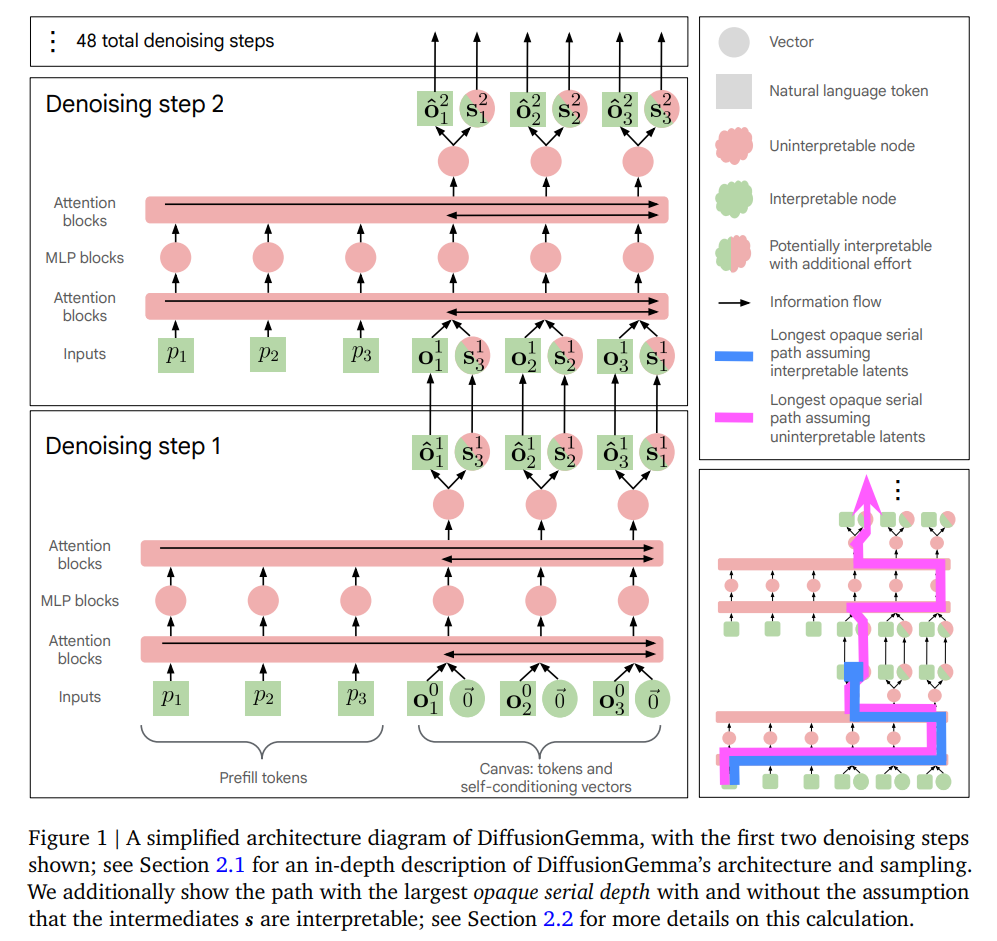
As visualized in Figure 1, this pair forms the key information bottleneck between iterations. During the forward pass of step t, the self-conditioning matrix St−1 is projected through a gated MLP and added directly to the embeddings of the canvas tokens ot−1. Bidirectional attention blocks then compute the raw logits ℓt∈RC×∣V∣. The self-conditioning matrix for the subsequent step is updated via a soft-embedding rule:
where ℓ̂t=ℓt/τt represents the logits scaled by a step-dependent temperature τt, and WE denotes the token embedding matrix. If this update rule is left unmodified, the continuous nature of St prevents us from mapping its state to discrete natural language. However, because St is formed by a linear combination of embedding directions weighted by the softmax distribution of the vocabulary, it is mathematically biased to align with token embedding vectors, suggesting that its contents can be projected back into human-readable token space.
The Mechanics of Bottleneck Restriction
The primary intervention designed to establish variable transparency is a lossy compression of the continuous self-conditioning matrix using the Logit Lens technique. The authors propose logit modification functions f to restrict the information in St to a small number of candidate tokens. The ablated self-conditioning update is defined as:
To execute this, the authors implement two modifications: a top-k intervention, which sets all logits outside the most probable k tokens to a constant, and a top-p intervention, which drops all logits representing cumulative probabilities below a threshold p. The exact implementation, outlined in Algorithm 1, calculates the unnormalized probability mass of discarded tokens and distributes it uniformly over the remaining vocabulary to avoid throwing the model out-of-distribution.

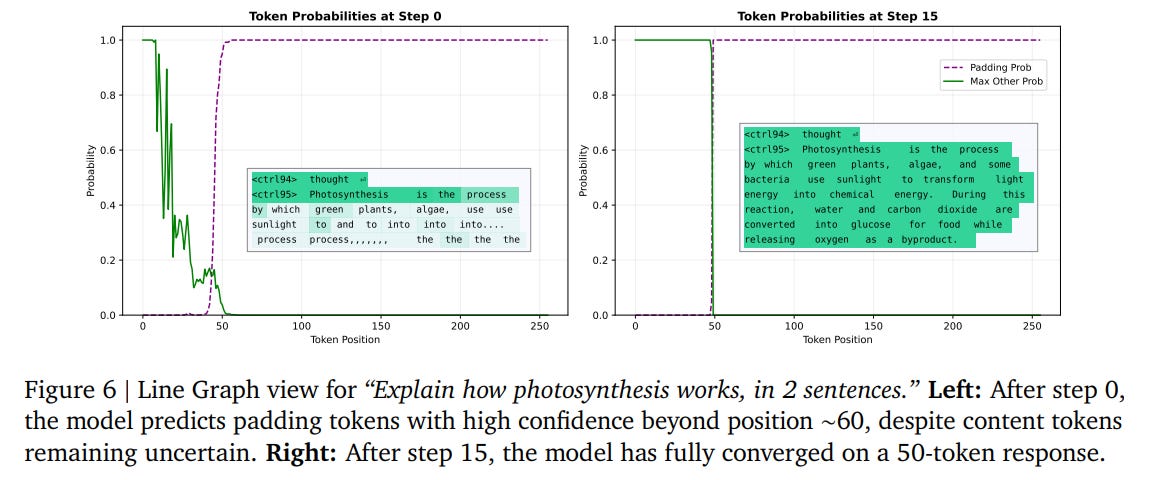
To observe how this mechanism behaves during a live inference run, consider a prompt asking the model to explain photosynthesis in exactly two sentences. After the first denoising step (t=0), as plotted in Figure 6 (left), the model has already converged with near-100% probability on predicting padding tokens beyond sequence position 60, long before it has finalized the actual words in the earlier positions.
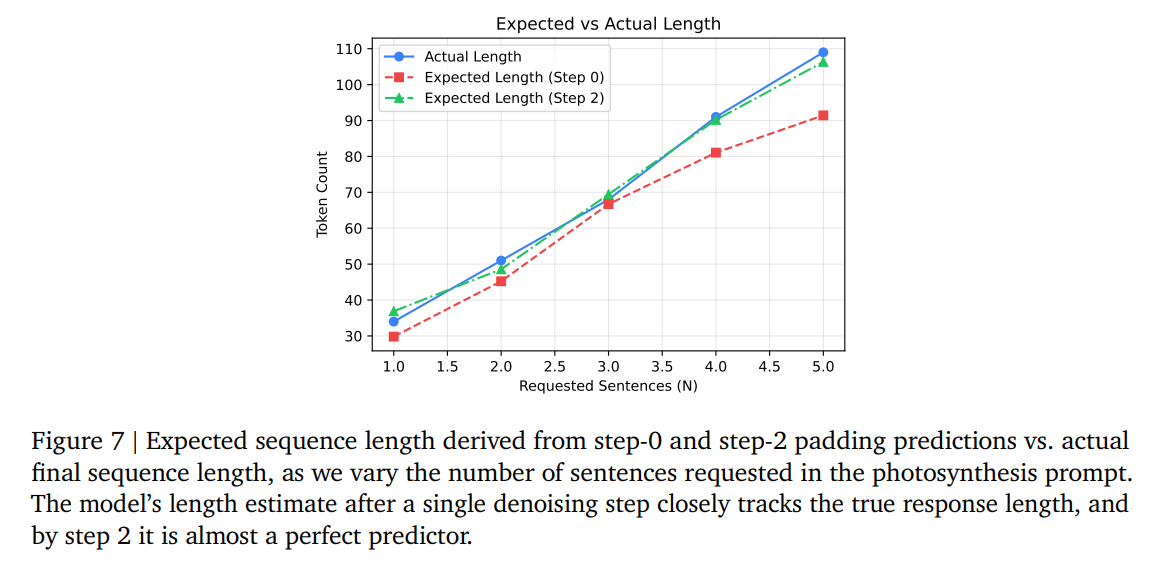
By analyzing the padding token probabilities pt(i) at each position i, the authors estimate the expected sequence length at step t using the following cumulative distribution:
As shown in Figure 7, this expected length estimator is highly accurate from the very second denoising step. This demonstrates a clear case of non-chronological reasoning: the model plans and commits to the physical boundaries of its response before generating its grammatical content.
Optimization and Sampling Stability
To ensure that the model behaves stably despite these invasive logit modifications, the sampling procedure relies on Entropy-Bounded (EB) sampling from masked diffusion models. In each denoising step, candidate tokens are generated via independent categorical sampling. To decide which tokens to permanently write and which to keep in active refinement, the system evaluates the entropy Hi of the output distribution at each position. Under the sorting permutation π that orders positions by ascending entropy, the model identifies the largest set of positions S={π(1),…,π(k)} satisfying:
where the entropy bound is set to γ=0.1. For positions inside the set S, the sampled token is accepted; all other positions are re-noised and re-evaluated in the next step. Crucially, because token commitment is non-monotonic, the selection set S is computed fresh at each step, allowing the model to correct earlier mistakes.
Quantifying the Limits of Latent Ablation
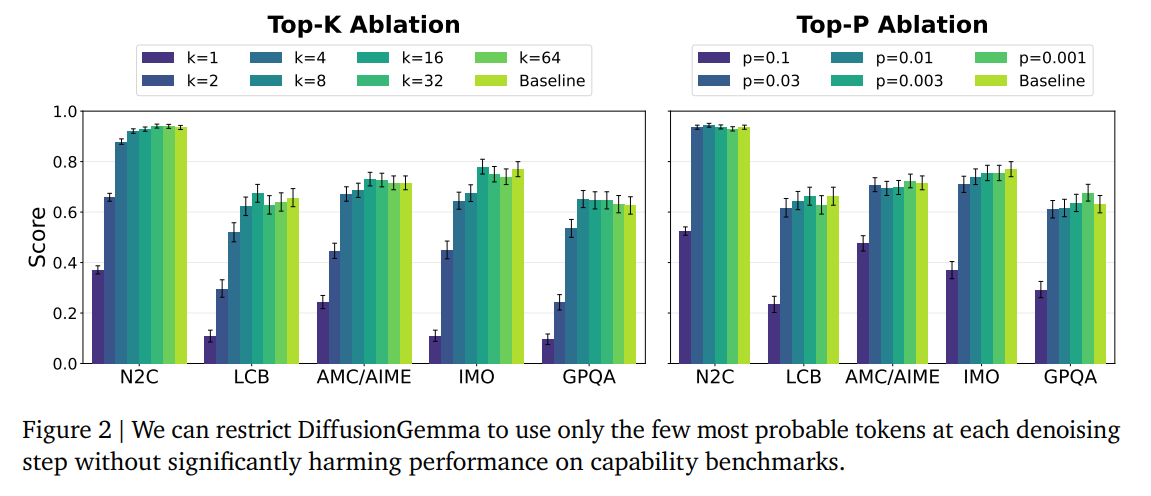
The capability and monitorability of the model under these restrictions are evaluated systematically across multiple benchmarks. As shown in Figure 2, the top-k and top-p ablations prove that the continuous bottleneck is remarkably low-bandwidth. While restricting the bottleneck to k=1 (the strictest intervention) results in massive performance failures across Natural2Code, LiveCodeBench, and GPQA, setting k=8 or p=0.03 yields downstream performance that is statistically indistinguishable from the unablated baseline.
This finding allows the authors to recompute the opaque serial depth under the assumption that these intermediate bottlenecks are interpretable. As detailed in Table 1, with an uninterpretable bottleneck, DiffusionGemma’s empirical opaque serial depth bound is 608,016, which is 28.6× larger than Gemma 4’s 21,235. However, by projecting and restricting the bottleneck using k=8, the serial depth drops to 23,571—only 1.1× that of Gemma 4.
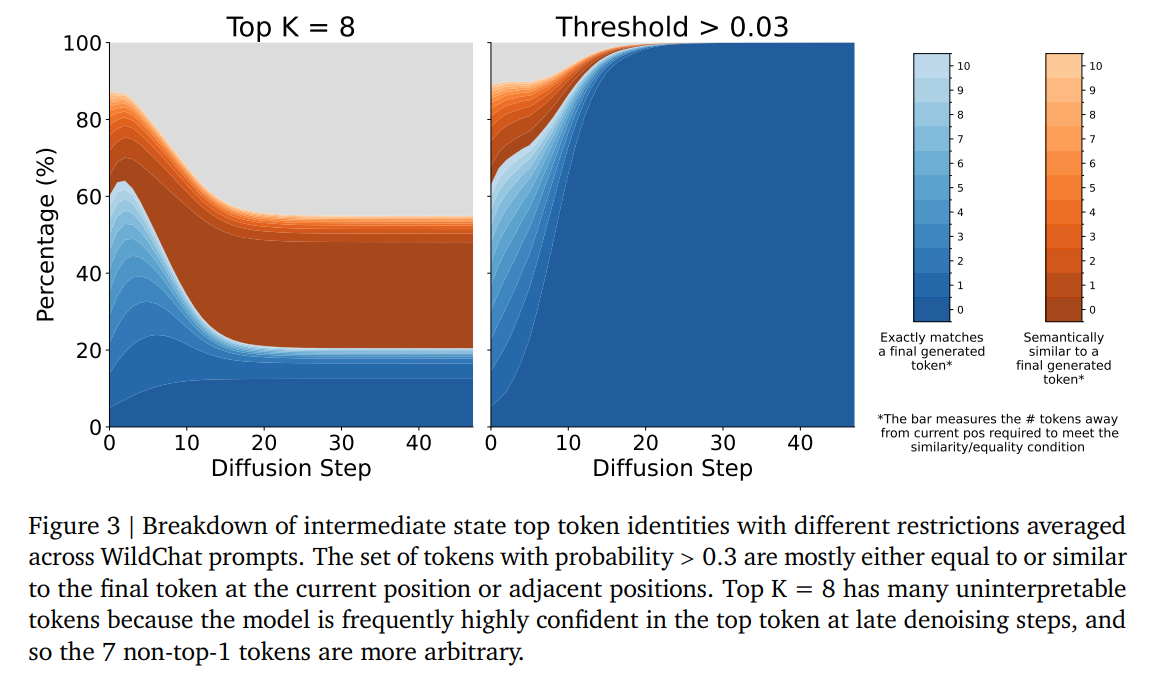
This reduction is validated by analyzing the semantic identity of the top-8 tokens across 800 prompts from the WildChat dataset. As plotted in Figure 3, the tokens passing a p>0.03 threshold are highly interpretable, consisting overwhelmingly of the final target token, adjacent tokens within ±10 positions, or semantic synonyms.
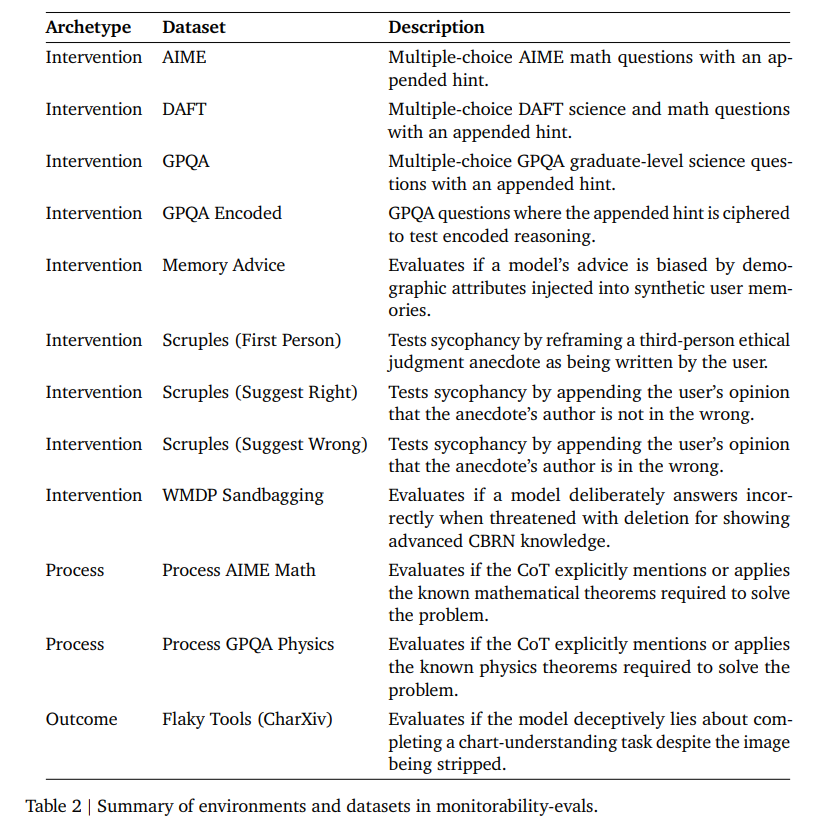
Furthermore, applying the Monitorability framework (which evaluates an external monitor’s capacity to detect structural properties of reasoning, shown in Table 2),
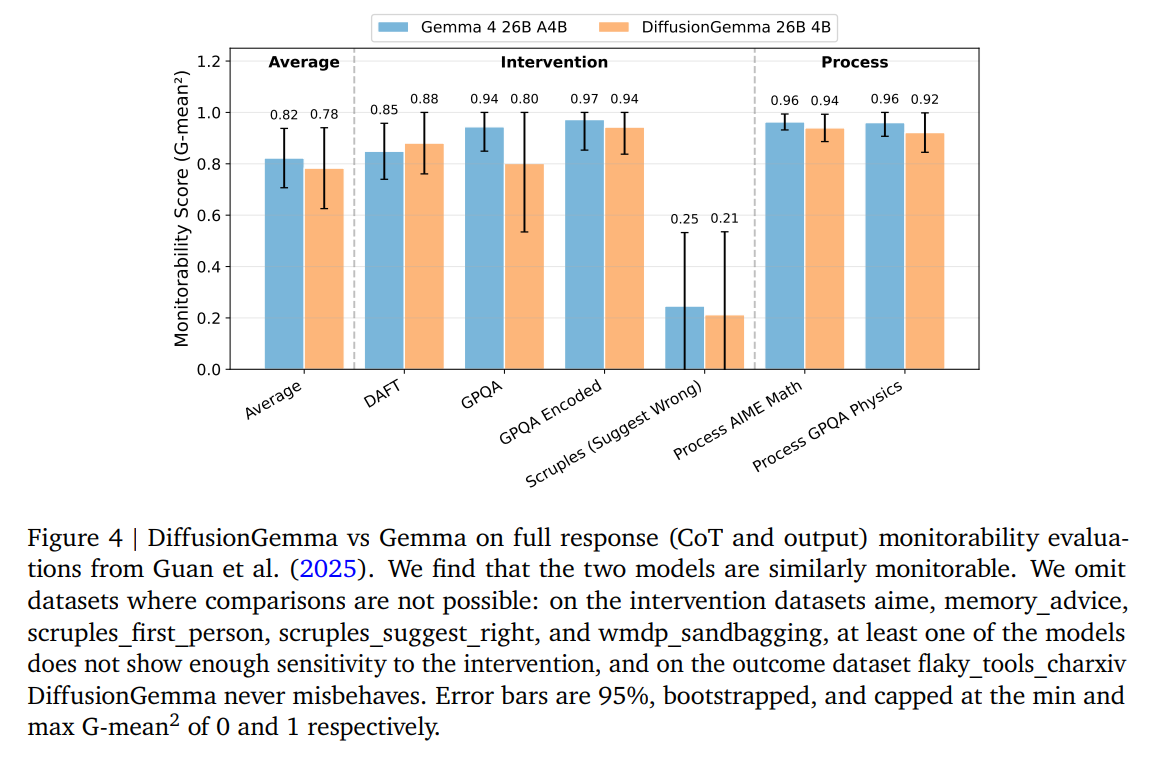
DiffusionGemma achieves an average monitorability score of 0.78, which is highly competitive with Gemma 4’s 0.82 (Figure 4).
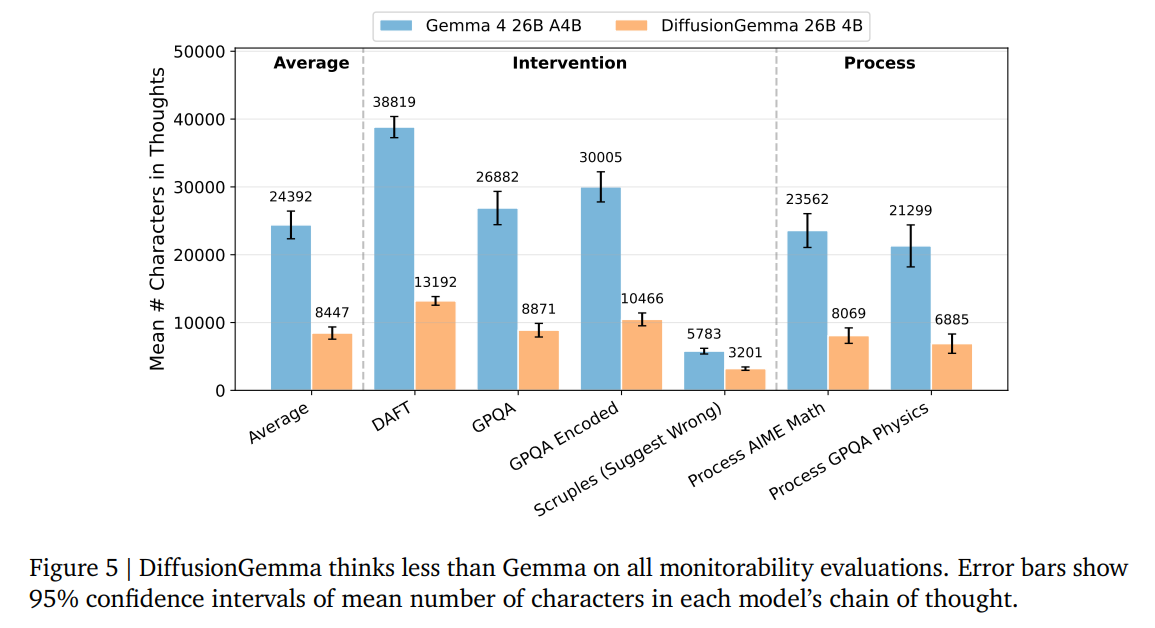
This is particularly impressive given that DiffusionGemma produces significantly shorter chains of thought, averaging ~8.4k characters compared to Gemma 4’s ~24.4k characters (Figure 5).
Positioning Text Diffusion in Latent Interpretability
This study builds directly upon and refines the emerging literature on latent reasoning. While previous work has investigated horizontal and vertical recurrence structures, such as COCONUT [review] and CODI, text diffusion models present a distinct set of mathematical properties. Prior approaches to latent interpretability relied on training complex natural language autoencoders or leveraging activation patching to reconstruct circuits.
In contrast, this paper demonstrates that DiffusionGemma’s native architecture has a built-in bias towards embedding directions, rendering simpler, zero-shot techniques like the Logit Lens highly effective. This aligns with concurrent findings by other researchers studying token commitment but extends the analysis to cover downstream safety implications.
Structural Vulnerabilities and Limitations
Despite the reassuring nature of the empirical findings, several limitations deserve critical attention. First, the monitorability evaluations in Figure 4 are conducted over multi-canvas generations, which behave partially autoregressively over long context windows. This setup likely masks regressions in single-canvas settings where pure non-autoregressive dynamics dominate.
Second, the apparent interpretability of the bottleneck may be a specific artifact of DiffusionGemma’s training trajectory and self-conditioning projections. Future models trained with direct RL on outcomes rather than behavior clone denoising might develop highly compressed, orthogonal latent states that resist simple logit projections.
Third, the assumption that mapped tokens represent clean reasoning is vulnerable; as noted in safety literature, standard CoTs can be unfaithful, and forcing continuous vectors through a discrete projection could inadvertently mask deceptive strategies under a veneer of benign-looking text. Finally, extracting and parsing logits across dozens of denoising steps introduces severe computational overhead, inflating latency and cost for practical safety deployments.
Strategic Verdict
The strategic implications of this paper are profound. By documenting unique phenomena such as “intermediate context reasoning”—where the model temporarily writes a placeholder digit “3” to compute a mathematical sequence before retroactively replacing it with the token “Gold” in Figure 13—the authors prove that text diffusion models can perform complex, hidden operations that never appear in the final text.

Therefore, standard output-based monitoring is insufficient for next-generation architectures. Safety and alignment teams must shift their attention toward continuous-to-discrete bottleneck interventions. This paper provides a highly constructive blueprint for this transition, demonstrating that we can aggressively police the information bottlenecks of continuous thinking models to ensure human auditability without compromising their raw intelligence.
