
[ICML 2025] CollabLLM: From Passive Responders to Active Collaborators
Authors: Shirley Wu, Michel Galley, Baolin Peng, Hao Cheng, Gavin Li, Yao Dou, Weixin Cai, James Zou, Jure Leskovec, Jianfeng Gao
Paper: https://arxiv.org/abs/2502.00640, ICML submission
Code: http://aka.ms/CollabLLM
Model: https://huggingface.co/collabllm
We are continuing reviewing ICML 2025 papers that received the Outstanding Paper Award.
TL;DR
What was done? This paper introduces CollabLLM, a training framework designed to transform Large Language Models (LLMs) from passive instruction-followers into active collaborators. The key innovation is "Multiturn-aware Rewards" (MR), a forward-looking reward mechanism. Instead of optimizing for the immediate next response, CollabLLM estimates the long-term impact of a response by simulating future conversational turns with an LLM-based user simulator. This simulation allows it to calculate a holistic reward that balances task success (extrinsic metrics) with user experience factors like efficiency and engagement (intrinsic metrics). The model is then fine-tuned using reinforcement learning (PPO/DPO) to maximize these long-term gains.
Why it matters? This work addresses a fundamental limitation of current LLMs: their passive nature in complex, multi-turn conversations. Real-world users often have ambiguous or evolving goals, leading to frustrating and inefficient interactions. By training models to proactively clarify intent, ask guiding questions, and optimize for the entire conversational outcome, CollabLLM makes a significant leap toward more human-centered AI. The approach is validated not just in simulations but through a large-scale study with 201 real users, which demonstrated a 17.6% increase in user satisfaction and a 10.4% reduction in task completion time. This research provides a scalable and effective blueprint for building genuinely helpful AI assistants that can act as strategic partners rather than just reactive tools.
Details
The Problem: The Passivity of Modern LLMs
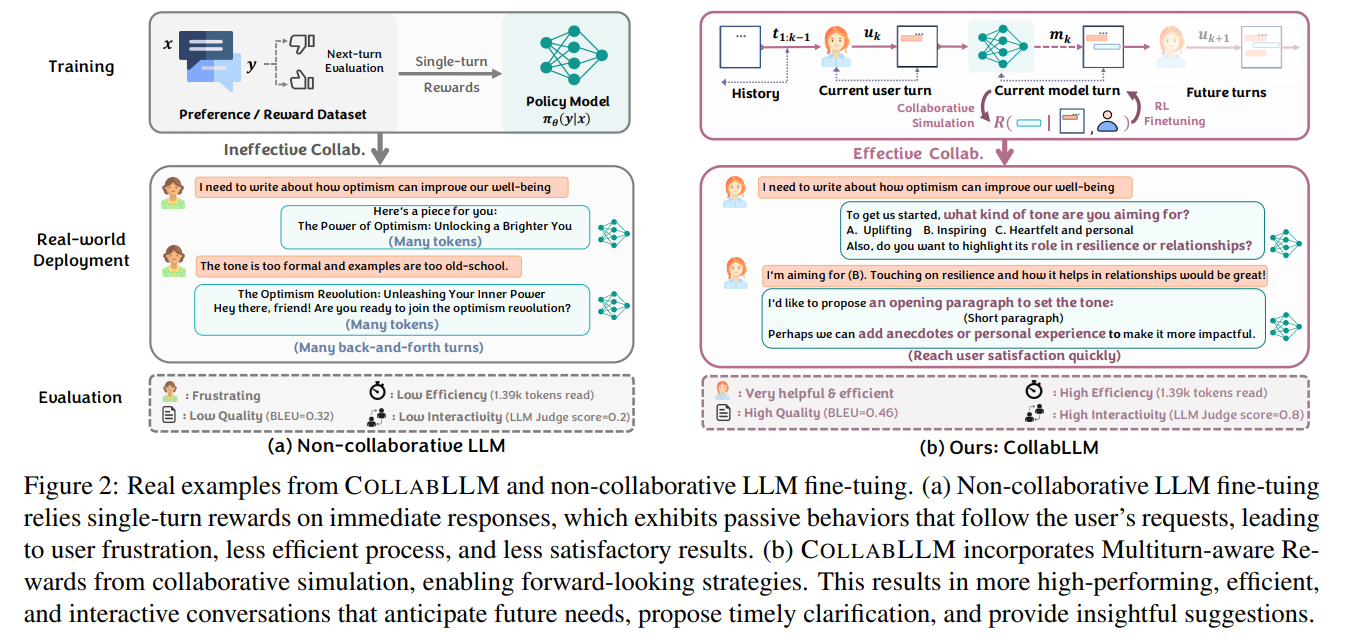
Think about the last time an AI assistant frustrated you. Perhaps you asked it to help plan a vacation, and it gave a generic itinerary, forcing you to tediously specify every single preference ("No, I'm a vegetarian," "No, I prefer museums over beaches"). This back-and-forth is a symptom of a deeper issue. Large Language Models (LLMs), despite their remarkable capabilities, often falter in the messiness of real-world, multi-turn interactions. The reason, as this paper compellingly argues, lies in their training. Frameworks like Reinforcement Learning from Human Feedback (RLHF) typically optimize for the quality of the immediate next response, creating models that are excellent passive responders but poor active collaborators. When faced with an ambiguous or open-ended user request, these models often make unsafe assumptions or wait for the user to provide corrections, leading to inefficient dialogue and user frustration (Figure 2). This work tackles this core issue, aiming to evolve LLMs from mere responders to proactive partners.
The CollabLLM Framework: A Forward-Thinking Approach
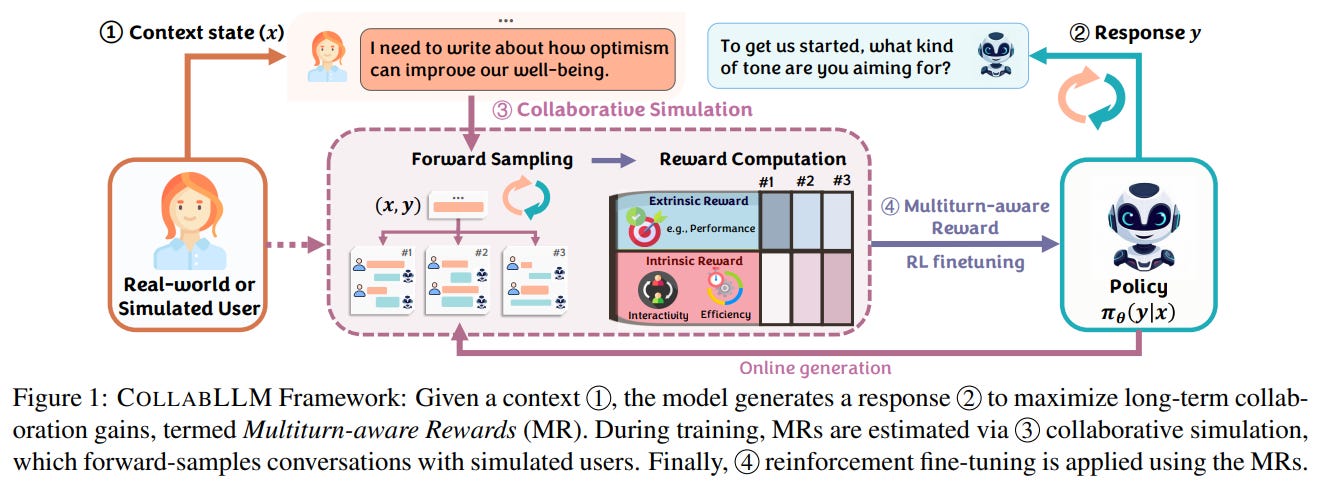
The authors introduce CollabLLM, a novel training framework designed to instill forward-looking, collaborative behaviors in LLMs. The methodology revolves around a few key innovations that collectively shift the optimization objective from short-term appeasement to long-term success, as detailed in the overall framework overview (Figure 1).
1. Multiturn-aware Rewards (MR) via Collaborative Simulation
The cornerstone of CollabLLM is the concept of Multiturn-aware Rewards (MR). Instead of evaluating a model's response in isolation, MR quantifies its long-term contribution to the entire conversation. To achieve this, the framework employs a collaborative simulation module. For a given response, the system forward-samples multiple potential future conversational trajectories by interacting with a sophisticated user simulator (GPT-4o-mini in the experiments).
This approach is fundamentally different from other trajectory-level optimization methods, which are purely observational. Those methods learn by observing which completed conversations were successful but cannot disentangle the specific contribution of any single response. In contrast, CollabLLM's simulation is interventional; it directly estimates the counterfactual impact of a response—'what would happen to the conversation if I chose this response instead of another?'—allowing for more precise, turn-level credit assignment. To make this simulation computationally tractable, the framework uses a limited lookahead window w, sampling only a set number of future turns, which provides a strong balance between capturing long-term impact and maintaining training efficiency.
The reward for the entire simulated conversation is a holistic function combining:
Extrinsic Reward (
R_ext): Measures task-specific success, such as the accuracy of a final math solution or the BLEU score of a generated document.Intrinsic Reward (
R_int): Captures user experience by rewarding conversational efficiency (penalizing excessive token counts) and engagement (measured by an LLM judge).
2. Scalable Training and Optimization
A major practical hurdle for training on multi-turn interactions is the prohibitive cost of human data collection. CollabLLM cleverly sidesteps this by using its MR mechanism to generate high-quality synthetic datasets (Figure 8).
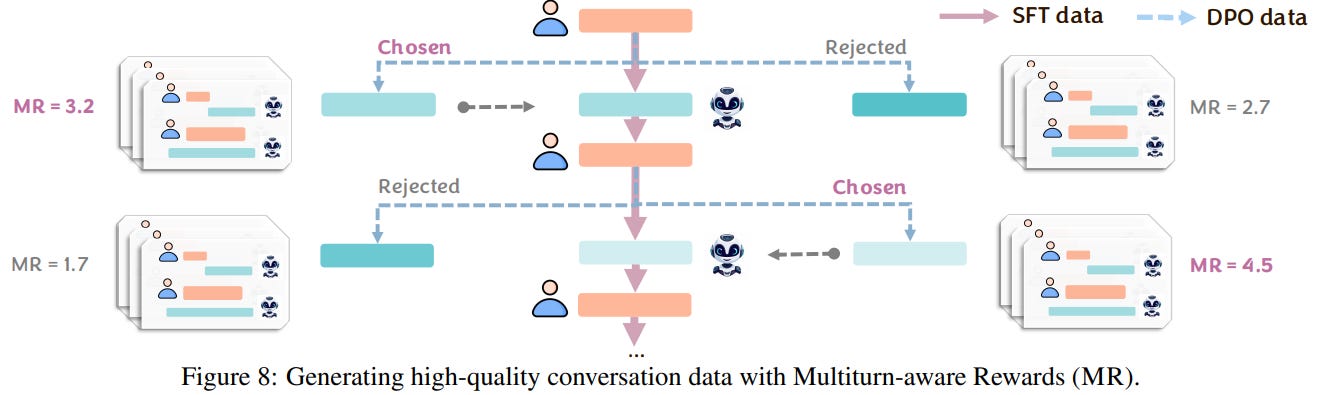
By ranking multiple sampled responses based on their MR scores, the framework can automatically create "chosen" and "rejected" pairs for Direct Preference Optimization (DPO) or generate high-quality trajectories for Supervised Fine-Tuning (SFT). This allows for scalable and efficient fine-tuning of a base model (Llama-3.1-8B) without requiring any human labels for the training process itself.
Experimental Validation: From Simulation to the Real World
The paper's claims are backed by a comprehensive set of experiments, demonstrating the framework's effectiveness in both simulated and real-world settings.
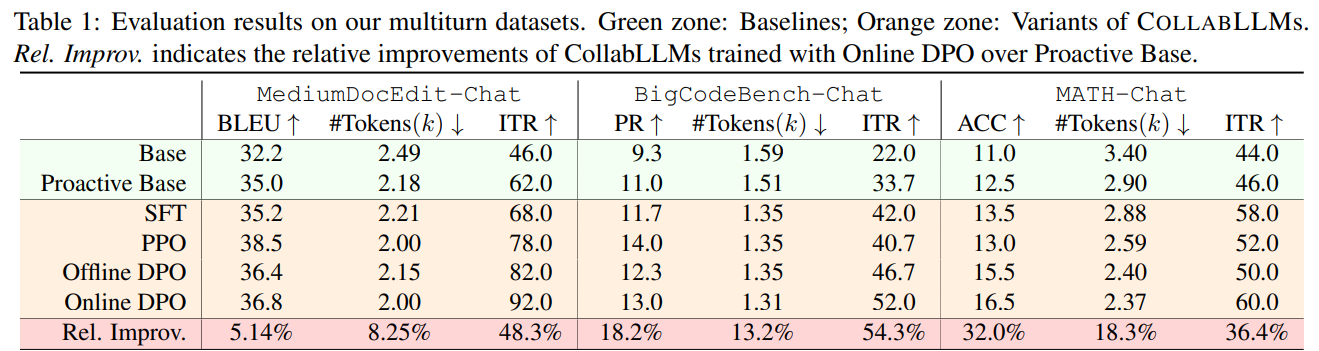
Simulated Performance: On a new benchmark of three challenging multi-turn tasks—document editing, code generation, and math problem-solving—CollabLLM significantly outperformed baselines. Compared to a proactively prompted base model, the best COLLABLLM variant achieved an average of 18.5% higher task performance and a 46.3% improvement in interactivity as judged by an LLM (Table 1).
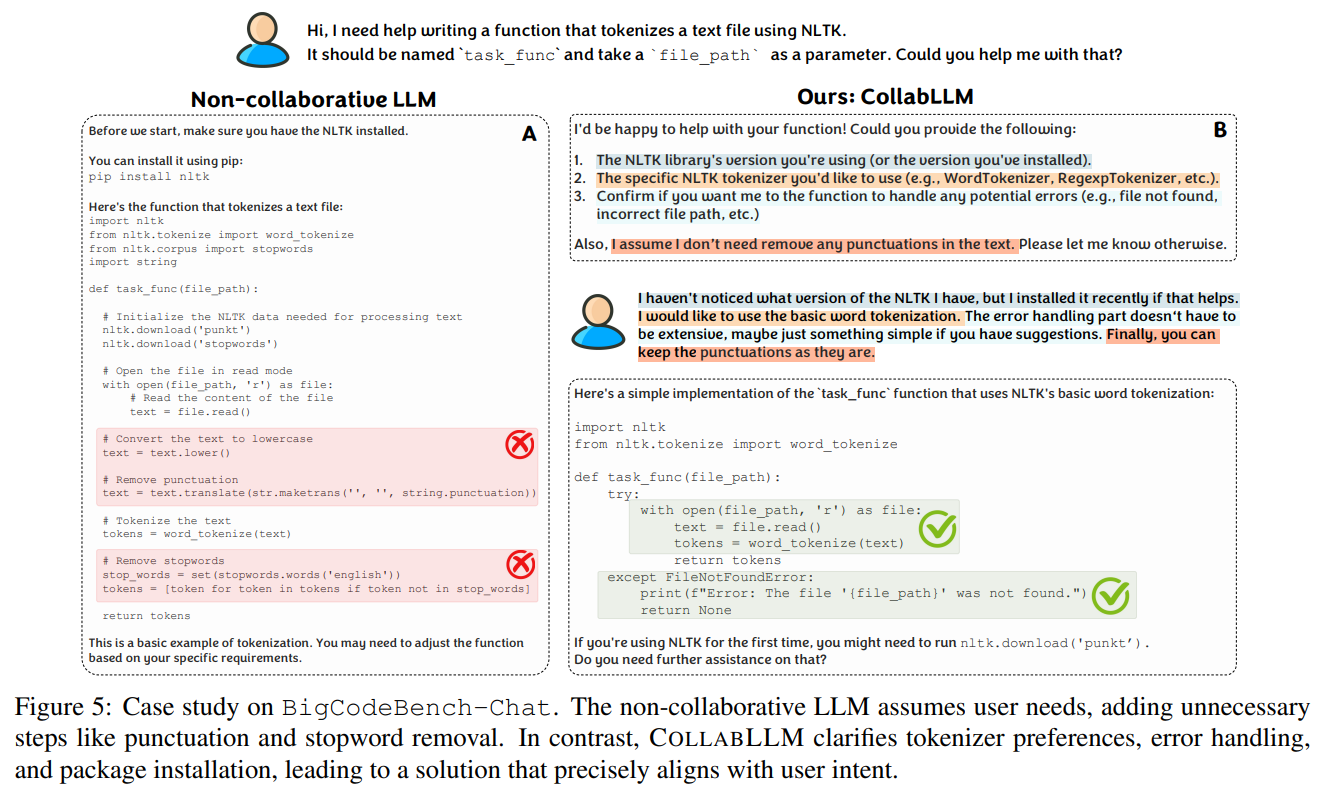
A case study on a coding task powerfully illustrates this difference: where a standard LLM makes incorrect assumptions, CollabLLM proactively clarifies requirements to deliver a correct solution with less user effort (Figure 5).
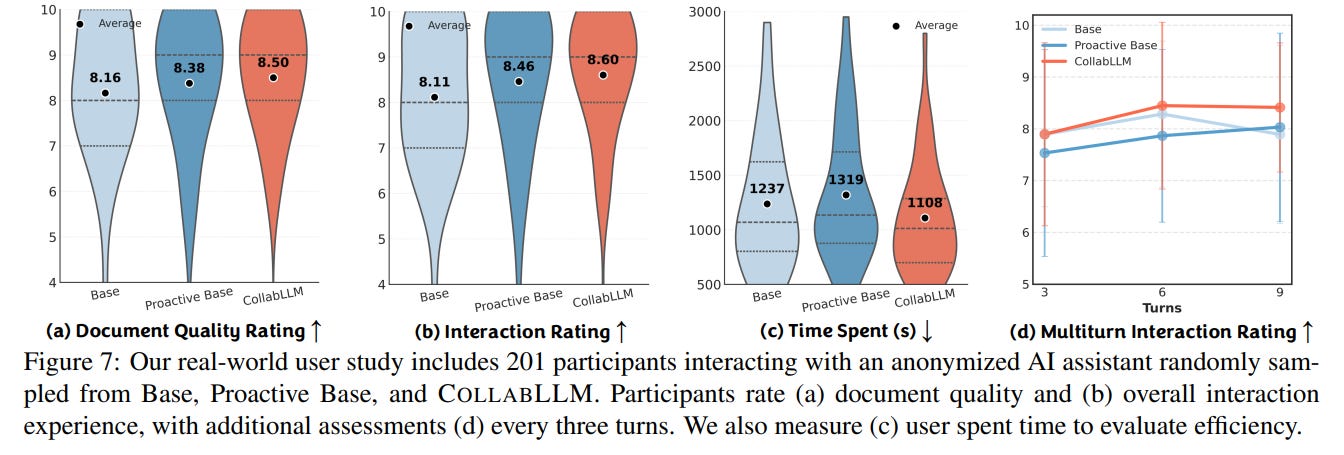
Real-World User Study: The most compelling evidence comes from a large-scale study with 201 real users tasked with writing documents. The results were striking:
CollabLLM increased user satisfaction by 17.6%.
It reduced the time users spent on the task by 10.4%.
It maintained high engagement over longer conversations, a stark contrast to the base model, whose ratings declined over time (Figure 7).
Qualitative feedback from users reinforced these numbers. While the base model was seen as passively agreeable, CollabLLM was praised for "asking questions and making you think of things you never thought of" and for helping users navigate the writing process effectively (Table 3).

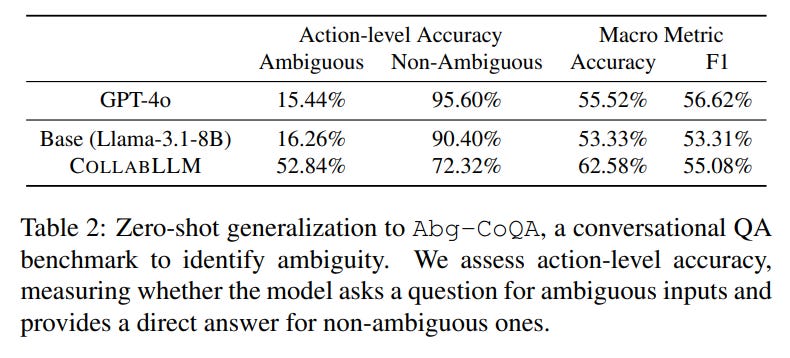
Generalization and Safety: The collaborative behaviors learned by CollabLLM were also shown to generalize effectively to a new, unseen conversational QA task (Table 2).
Encouragingly, a dedicated safety evaluation confirmed that this collaborative training did not compromise the underlying model's safety alignment, maintaining a 99.7% pass rate on adversarial queries (Table 8).

Limitations and Future Horizons
The authors are transparent about the method's current limitations. The framework's performance is tied to the quality of the user simulator. The paper notes that creating high-fidelity simulators is a significant challenge in itself; when attempting to use current open-source models for this role, they found the models often get "confused" and revert to acting like an assistant rather than realistically mimicking a user's sometimes-unpredictable behavior. This highlights a key bottleneck for the research community. Furthermore, analysis shows a gap between simulated and real user behavior, as real users are often more erratic, emotional, and use more fragmented language (Table 9). Finally, user feedback indicated that CollabLLM could sometimes feel "bland" or lack up-to-date knowledge.

These limitations point toward clear future research directions, including building more realistic open-source user models and integrating greater personalization, creativity, and real-time knowledge into collaborative AI systems.
Conclusion
"CollabLLM: From Passive Responders to Active Collaborators" presents a significant and well-executed contribution to the field of conversational AI. By shifting the training paradigm from myopic, next-turn rewards to long-term, collaborative gains, the authors provide a robust and scalable framework for building more effective and human-centered LLMs. The strong validation, especially through the extensive real-world user study, convincingly demonstrates that this forward-thinking approach can lead to AI assistants that are not just powerful tools but truly valuable collaborators. This paper offers a valuable blueprint for the next generation of interactive AI.