
[ICML 2025] Conformal Prediction as Bayesian Quadrature
Authors: Jake C. Snell, Thomas L. Griffiths
Paper: https://arxiv.org/abs/2502.13228, ICML submission
Code: https://github.com/jakesnell/conformal-as-bayes-quad
More ICML 2025 papers that received the Outstanding Paper Award!

TL;DR
WHAT was done? This paper reframes frequentist conformal prediction through a Bayesian lens, modeling the problem of bounding expected loss as an application of Bayesian Quadrature. By leveraging a classic result from distribution-free statistics—that the spacings between ordered quantiles of i.i.d. samples follow a Dirichlet distribution—the authors develop a nonparametric framework that remains distribution-free. Instead of producing a single point estimate of risk, their method computes the full posterior distribution of a provable upper bound on the expected loss, which they call L+.
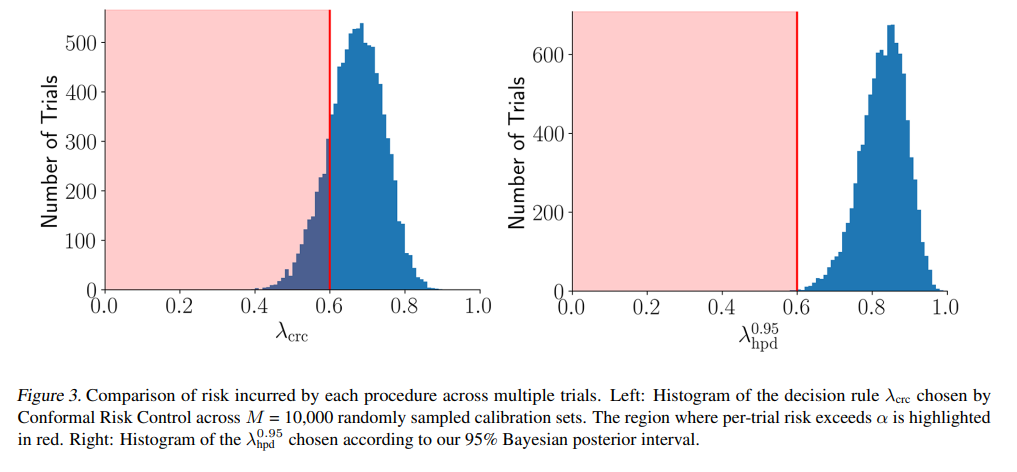
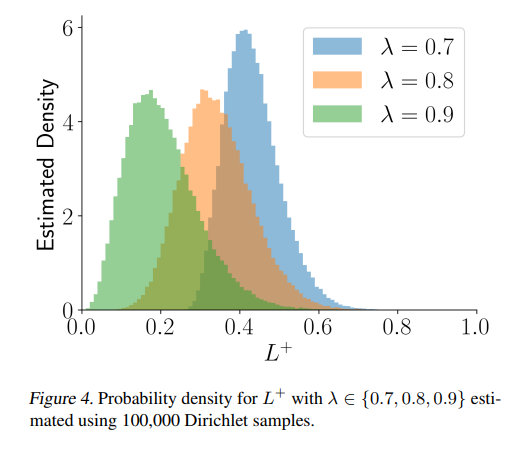
WHY it matters? This approach provides a richer, more practical "data-conditional" guarantee on model performance. While traditional conformal methods offer guarantees that hold on average over many datasets, experiments show they can frequently fail to control risk for individual calibration sets (Table 1, 3). This Bayesian framework yields a more complete view of potential outcomes (Figure 4) and leads to significantly lower failure rates while maintaining competitive (and often smaller) prediction sets. It unifies existing methods like Split Conformal Prediction and Conformal Risk Control as special cases, offering a more robust and interpretable foundation for quantifying uncertainty in high-stakes AI systems.
Details
As machine learning models become integral to high-stakes domains like medical diagnostics and finance, ensuring their reliability is not just a technical challenge but a critical necessity. Distribution-free uncertainty quantification (UQ) techniques like conformal prediction have become popular for providing performance guarantees on black-box models. However, these methods are rooted in frequentist statistics, which can limit their applicability and interpretability. A recent paper, "Conformal Prediction as Bayesian Quadrature," offers a compelling alternative by revisiting these techniques from a Bayesian perspective, leading to more comprehensive and practically useful risk guarantees.
The Shift from Averages to Actuals
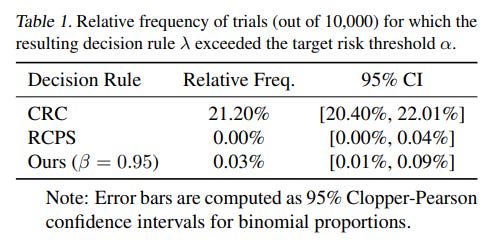
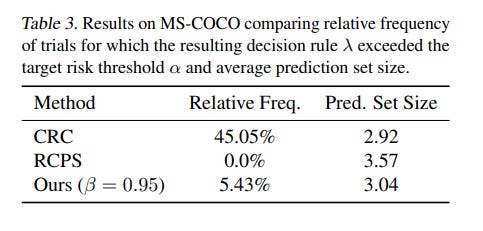
A key limitation of standard conformal methods is their focus on marginal guarantees. This means the promised error rate (e.g., 5%) holds on average over many hypothetical calibration and test sets. While theoretically sound, this can be misleading. In any single, real-world deployment, the actual error rate might be significantly higher. The authors’ experiments highlight this vividly: the popular Conformal Risk Control (CRC) method exceeded its target risk threshold in 21% of trials on one synthetic dataset (Table 1) and a striking 45% of trials on the MS-COCO dataset (Table 3), despite its marginal guarantee being valid. For any application where a single failure is costly, this is a significant concern.
To fully appreciate the paper's contribution, it's helpful to distinguish between three types of guarantees. A marginal guarantee (like in CRC) holds on average across all possible datasets. An input-conditional guarantee is much stronger, holding for a specific input X, but is often impossible to achieve without strong assumptions. This paper carves out a powerful and practical middle ground with a data-conditional guarantee: the guarantee is conditioned on the specific set of calibration data you actually have, providing a far more relevant risk assessment for a given deployment without needing impossibly strong assumptions.
A Bayesian Reinterpretation
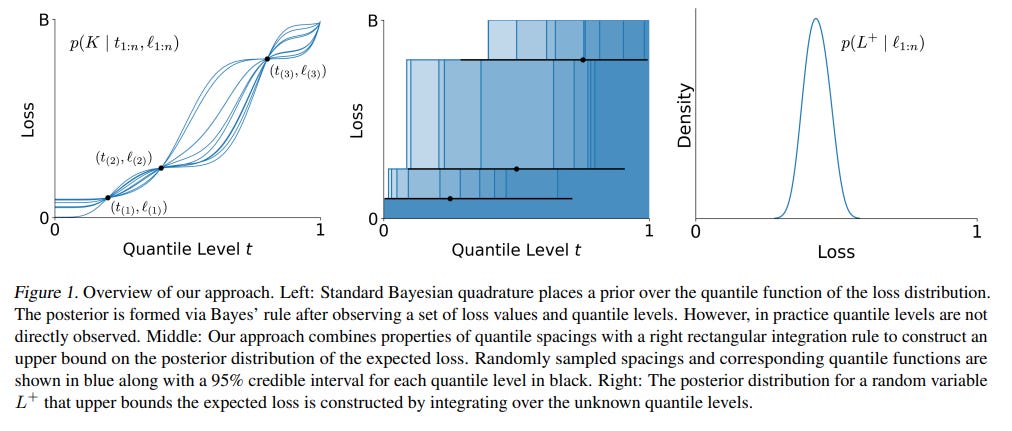
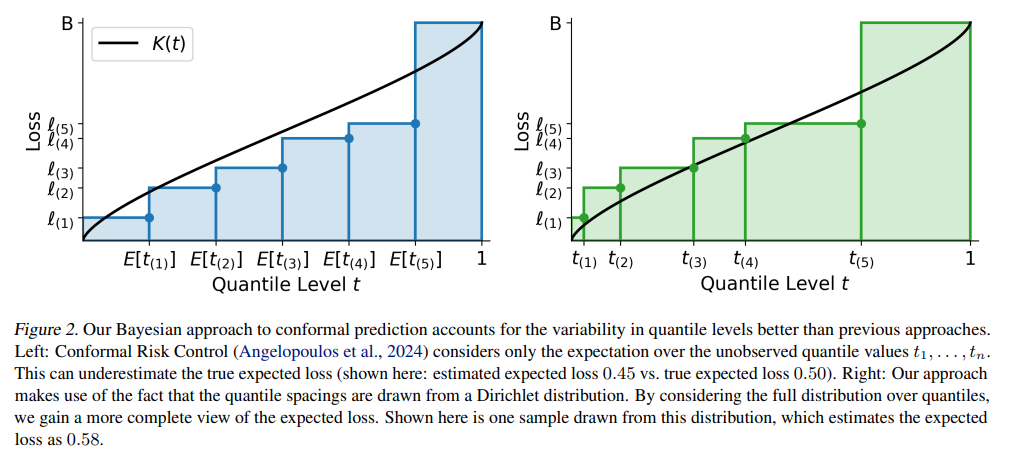
The paper's core innovation is to reformulate the problem of bounding expected loss as a Bayesian Quadrature problem—essentially, using Bayesian inference to estimate an integral. Crucially, while traditional Bayesian Quadrature might place a specific prior (like a Gaussian Process) on the function, this work cleverly avoids that. Instead, it uses a known property of quantile spacings to remain fully distribution-free, gaining Bayesian-style distributional outputs without the usual cost of strong prior assumptions.
The logical flow behind this is elegant. The goal is to find an upper bound on the expected loss, which is the integral of the unknown quantile function of the losses.
We have observed losses from a calibration set, but we don't know their corresponding quantile levels (
t_i).However, a classic statistical result (Lemma 4.2) tells us that the spacings between these unknown quantile levels follow a Dirichlet distribution.
By sampling these spacings and using them as weights for the ordered observed losses, the method constructs a random variable,
L+. ThisL+represents the expected loss under a "worst-case" step-function-like quantile function that is consistent with the data, thereby providing a robust upper bound on the true expected loss (Theorem 4.3).
This approach provides two fundamental advantages:
A Full Distribution of Risk: Instead of collapsing the uncertainty into a single point estimate, the method yields the full posterior distribution of
L+(Figure 1, 4). This gives practitioners a far richer view of the potential outcomes, showing not just the average expected loss but the entire range of plausible values and their likelihoods.Data-Conditional Guarantees: The guarantees are conditioned on the actual observed calibration data, moving beyond the frequentist average. This focus on the data at hand allows for more robust decision-making tailored to the specific deployment scenario.
Ultimately, this work does more than just fix a weakness in existing methods; it provides a more extensible and intuitive foundation for uncertainty quantification. By grounding conformal prediction in Bayesian probability, it opens the door to future work that could incorporate other forms of prior knowledge in a principled way, further tightening guarantees and making AI systems even more reliable.