
[ICML 2025] The Value of Prediction in Identifying the Worst-Off
Authors: Unai Fischer-Abaigar, Christoph Kern, Juan Carlos Perdomo
Paper: https://openreview.net/forum?id=26JsumCG0z
Code: The paper utilizes the open-source CatBoost library
Data: The study uses a scientific use file from the German Federal Employment Agency (IAB) (see Antoni et al., 2019a and 2019b).
One more paper with the Outstanding Paper Award from the ICML 2025 conference.
TL;DR
WHAT was done? This paper introduces a formal framework to evaluate the trade-off between improving a model's predictive accuracy and expanding bureaucratic capacity (i.e., screening more people) in government programs designed to help the "worst-off." The authors develop the Prediction-Access Ratio (PAR), a novel metric that quantifies the relative welfare benefit of investing in better predictions versus increasing the number of individuals who can be screened and supported. Through theoretical models and a real-world case study on long-term unemployment in Germany, they analyze the conditions under which each policy lever is more effective.
WHY it matters? This work provides a crucial counter-narrative to the "accuracy-first" mindset prevalent in applied machine learning. It demonstrates that in many real-world, resource-constrained scenarios, investing in the operational capacity to act on predictions yields greater societal benefits than marginal improvements in model accuracy. The PAR offers policymakers a principled, data-driven tool to move beyond isolated technical metrics and make holistic, cost-aware decisions about system design. The research signals a maturation of AI for social good, shifting the focus from "how accurate is the model?" to "what is the most effective way to improve welfare, and how does prediction fit in?"
Details
Shifting the Goalposts from Accuracy to Impact
In the drive to apply machine learning to public policy, the default objective has often been to maximize predictive accuracy. Whether identifying students at risk of dropping out or households in need of financial aid, the implicit assumption is that a more accurate model is always a better one. This paper critically examines and ultimately challenges this assumption by asking a more nuanced question: in equity-driven contexts, what is the most effective way to improve the lives of the most vulnerable? Is it always a better algorithm, or could it be something else, like hiring more caseworkers?
The authors develop a comprehensive framework to answer this question, centering on a core policy objective: identifying and supporting the "worst-off" members of a population. This shifts the evaluative lens from aggregate outcomes to a targeted, welfare-centric goal.
A Framework for Principled Decisions: The Prediction-Access Ratio
The cornerstone of the paper's methodology is the Prediction-Access Ratio (PAR), a metric designed to quantify the trade-off between two key policy levers:
Improving Predictions: Enhancing a model's predictive power (measured by R²).
Expanding Access: Increasing the screening capacity (α), or the proportion of the population that can be evaluated and supported.
The PAR is defined as the marginal gain in welfare from expanding access divided by the marginal gain from improving prediction (Equation 3). This leads to an elegant decision rule: a social planner should expand access whenever the marginal cost ratio of access to prediction (C_Access / C_Pred) is less than the PAR. This formula provides a direct, quantitative bridge between the welfare gains measured by the PAR and the real-world budget constraints of a public agency.

To build intuition, the authors first develop this framework within a simplified theoretical model assuming Gaussian distributions. This allows them to derive clear analytical insights, revealing that the value of prediction is not uniform.
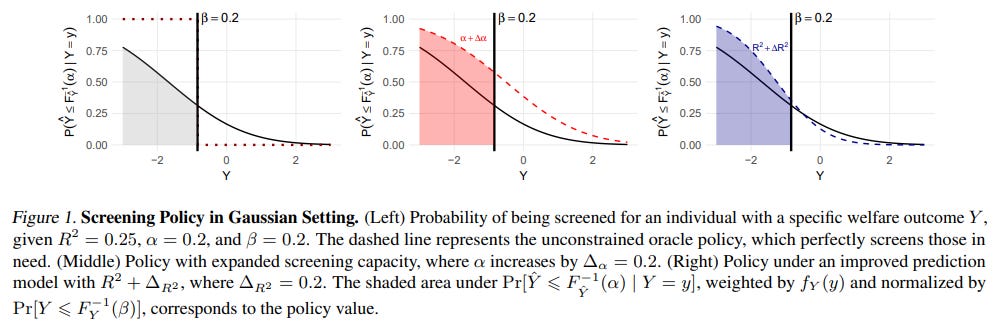
Their theoretical findings (Theorems 3.1 and 3.2) characterize prediction as a "first and last-mile effort." This means its value is highest at the extremes: when predictive power is very low (R² → 0), any small improvement provides a huge signal boost over random chance (the "first mile"). When predictive power is nearly perfect (R² → 1), a final bit of accuracy helps precisely target the last few individuals, eliminating waste and perfecting the allocation (the "last mile"). For the vast middle ground, where most real-world systems operate, expanding access often holds the advantage.
From Theory to Practice: A Case Study in German Unemployment
To ensure these theoretical insights are not mere artifacts of a simplified model, the authors apply their framework to a large-scale, real-world case study: identifying jobseekers at risk of long-term unemployment in Germany. Using administrative data and a CatBoost model, they empirically calculate the PAR under various scenarios.
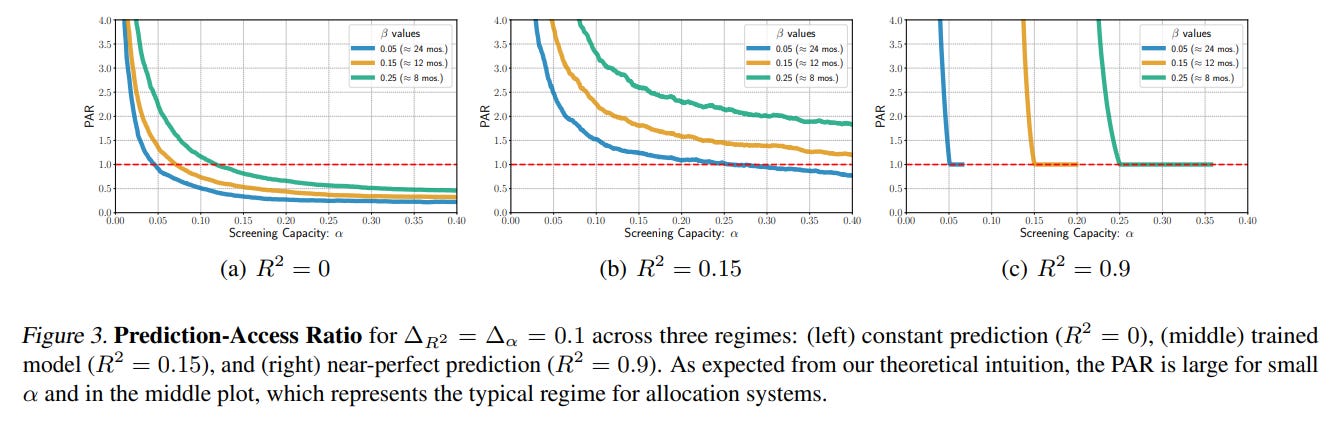
The results are striking and align with the theory. The trained model achieved an R² of 0.15 on the test set. This is not a sign of a "bad" model; rather, it's a realistic level of performance for complex social prediction tasks, a finding consistent with large-scale studies like the Fragile Families Challenge (Salganik et al., 2020). For this model, the PAR consistently remained above one, indicating that expanding screening capacity offers a greater marginal benefit than improving the model's predictive accuracy (Figure 3). For example, to guarantee that 75% of high-risk individuals are screened, the system needs the capacity to screen about 25% more people than the at-risk group itself, a direct overhead caused by imperfect prediction.
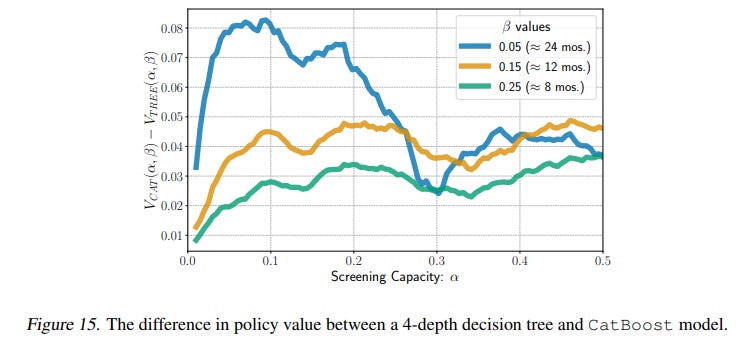
Furthermore, a comparison between the complex CatBoost model and a simple 4-depth decision tree showed that the significant increase in model complexity yielded only a minor (1-8%) improvement in policy value (Figure 15). This suggests that in many practical settings, the pursuit of marginal accuracy gains with sophisticated models may offer diminishing returns when compared to more straightforward operational investments.
The Broader Implications: A New Paradigm for AI in Public Service
The findings of this paper have significant implications for how we design, deploy, and evaluate AI in the public sector.
System-Level Thinking: The research pushes the field beyond model-centric optimization toward a more holistic, system-level perspective. The value of an AI component cannot be assessed in a vacuum; it is fundamentally tied to the capacity of the broader socio-technical system to act on its outputs.
"Good Enough" Models: It provides a quantitative argument for the concept of "good enough" modeling. When the bottleneck is not identification but intervention capacity, a simpler, more interpretable, and less costly model may be the superior choice, freeing up resources for expanding access.
Actionable Guidance for Policymakers: The PAR framework is not just a theoretical construct but a practical tool. It allows decision-makers to conduct data-driven, cost-benefit analyses to guide investments, ensuring that limited public funds are allocated in the most impactful way.
Limitations and Future Directions
The authors are transparent about the limitations of their work, which also point toward rich avenues for future research. The current framework relies on a simplified cost model and makes certain idealized assumptions in its theoretical derivations (e.g., Gaussian distributions). Future work could explore more complex cost structures, including fixed vs. recurring costs, and investigate dynamic environments where feedback loops and model drift are present. Furthermore, while the paper is grounded in an equity objective, future extensions could more explicitly model fairness across different demographic subgroups, ensuring that improvements do not come at the cost of exacerbating disparities.
Conclusion
"The Value of Prediction in Identifying the Worst-Off" is a significant and timely contribution to the field of AI for social good. By providing a rigorous framework to quantify the trade-offs between prediction and access, the paper offers a powerful tool for policymakers and a compelling argument for a more nuanced and system-aware approach to deploying AI in the public sector. It successfully bridges the gap between theoretical machine learning and practical policy, presenting a clear-eyed view that the most valuable investment isn't always in a smarter algorithm, but sometimes in the human-led systems that surround it. This paper is essential reading for anyone moving beyond algorithmic performance to the responsible and impactful application of AI in society.