


INTUITOR: Unlocking AI Reasoning with Self-Certainty
Learning to Reason without External Rewards
Authors: Xuandong Zhao, Zhewei Kang, Aosong Feng, Sergey Levine, Dawn Song
Paper: https://arxiv.org/abs/2505.19590
Code: https://github.com/sunblaze-ucb/Intuitor
TL;DR
WHAT was done? The paper introduces Reinforcement Learning from Internal Feedback (RLIF), a framework where LLMs improve their reasoning skills without external supervision. The authors propose INTUITOR, a novel RLIF method that uses the model's own "self-certainty"—defined as the KL divergence between its output distribution and a uniform one—as its sole intrinsic reward signal. This signal is integrated into the Group Relative Policy Optimization (GRPO) framework, replacing external, verifiable rewards and enabling fully unsupervised learning.
WHY it matters? This work offers a compelling alternative to the costly and domain-specific nature of existing methods like RLHF and RLVR. By learning from its own confidence, INTUITOR matches the performance of supervised methods on in-domain math tasks while demonstrating superior generalization to out-of-domain tasks like code generation. The approach also fosters the emergence of structured reasoning and is robust to reward exploitation, a common failure mode in RL. INTUITOR represents a significant and scalable step towards more autonomous AI systems that can learn and refine complex skills in environments where external validation is scarce or impossible.

Details
The High Cost of Supervised Reasoning
The reasoning capabilities of Large Language Models (LLMs) have been significantly advanced by reinforcement learning. Paradigms like Reinforcement Learning from Human Feedback (RLHF) and Reinforcement Learning with Verifiable Rewards (RLVR) have become standard for fine-tuning models on complex tasks. However, these methods share a critical dependency: external supervision. RLHF relies on expensive and potentially biased human preference data, while RLVR requires domain-specific, verifiable ground truth, such as correct answers in math or executable test cases in code. This reliance creates a bottleneck, limiting scalability and hindering a model's ability to generalize to new domains where such supervision is unavailable.
This paper confronts this challenge head-on, asking a fundamental question: Can LLMs learn to reason without any external rewards or labeled data? The authors propose that they can, by turning the model's focus inward.
The INTUITOR Approach: Learning from Internal Confidence
The paper introduces a new paradigm called Reinforcement Learning from Internal Feedback (RLIF), where models learn from self-generated signals. The primary contribution is INTUITOR, a concrete implementation of RLIF that cleverly uses the model's own confidence as its only reward.
The core idea is based on the observation that LLMs tend to be less confident when faced with difficult or unfamiliar problems. INTUITOR operationalizes this by defining an intrinsic reward called "self-certainty," which is the average KL divergence between the model's next-token predictions and a uniform distribution (Equation 4).

A key technical insight here is that this specific formulation of self-certainty, KL(U || P), is "mode-seeking." This property encourages the model to generate sharp, high-confidence probability distributions for its chosen tokens, effectively rewarding conviction. It is a critical distinction from other intrinsic metrics like negative entropy, which are "mode-covering" and can undesirably reward verbose or uncertain outputs—a common pitfall in unsupervised reinforcement learning.
The optimization process is both elegant and efficient. INTUITOR integrates this self-certainty signal into the well-established Group Relative Policy Optimization (GRPO) algorithm. The workflow is as follows (Figure 2):
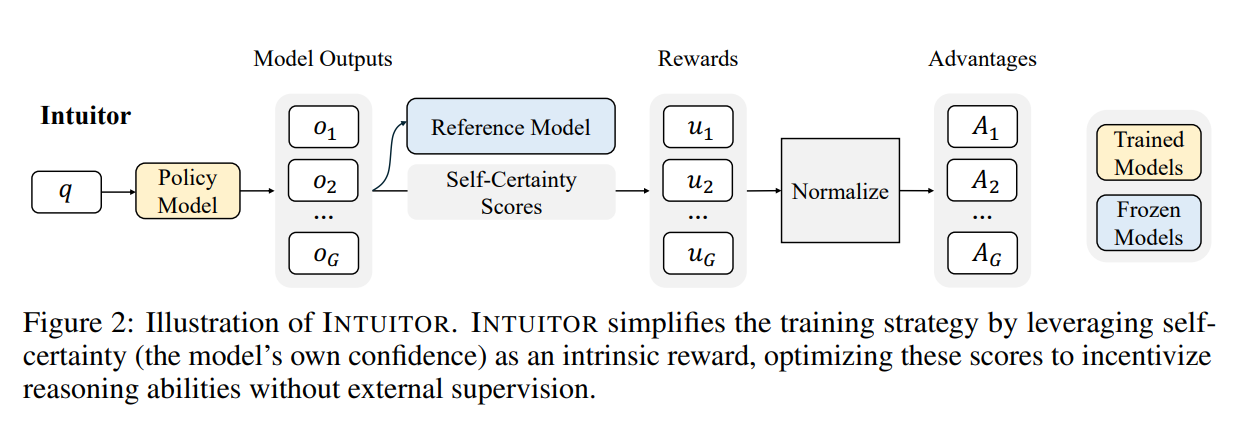
For a given prompt, the model generates a group of several candidate responses.
Each response is scored using the self-certainty metric.
These scores are normalized within the group to calculate advantages.
The policy is then updated using GRPO to favor outputs that achieve higher self-certainty.
Crucially, the reward signal is generated "online," meaning it co-evolves with the policy model. This dynamic approach proves vital for stability, preventing the model from learning to "hack" a static reward function—a common failure in RL.
Unsupervised Learning Unlocks Generalization and Robustness
The experimental results provide strong evidence for the efficacy of this unsupervised approach.
Performance and Generalization: On in-domain mathematical benchmarks (GSM8K, MATH500), INTUITOR achieves performance comparable to the supervised GRPO baseline, which uses gold-standard answers as rewards. The truly surprising result, however, lies in out-of-domain generalization. When a model trained on the MATH dataset was evaluated on code generation tasks (LiveCodeBench, CRUXEval), INTUITOR significantly outperformed GRPO (Table 1). This suggests that learning from an intrinsic signal like self-certainty encourages a deeper, more transferable understanding of reasoning processes, rather than just optimizing for a specific task's answers.

Emergent Structured Reasoning: A fascinating outcome of training with INTUITOR is the emergence of structured, long-form reasoning. Without being explicitly instructed, models learn to first articulate their reasoning steps before providing a final answer (Figure 5, Figure 6).


This self-explanation behavior appears to be a strategy the model develops to increase its own confidence. Even weaker base models, initially prone to generating nonsensical "gibberish," learned to produce coherent and instruction-following outputs after being fine-tuned with INTUITOR (Figure 3).

Robustness to Reward Hacking: The paper compellingly demonstrates INTUITOR's robustness. An experiment comparing the online self-certainty reward to an offline (static) one showed that the offline model quickly learned to exploit its reward by generating irrelevant, long-winded answers, causing performance to collapse. In contrast, the online signal used by INTUITOR remained stable, preventing such reward hacking and ensuring meaningful learning (Figure 7).

The Path Toward Autonomous AI
This research marks a significant step toward more autonomous AI systems. By demonstrating that LLMs can improve their reasoning skills through introspection, the paper opens a path for training agents in complex domains where external feedback is impractical or even impossible. The authors suggest several promising directions for future work, including scaling the approach to larger models, combining intrinsic signals with sparse external rewards, and exploring other policy optimization algorithms.
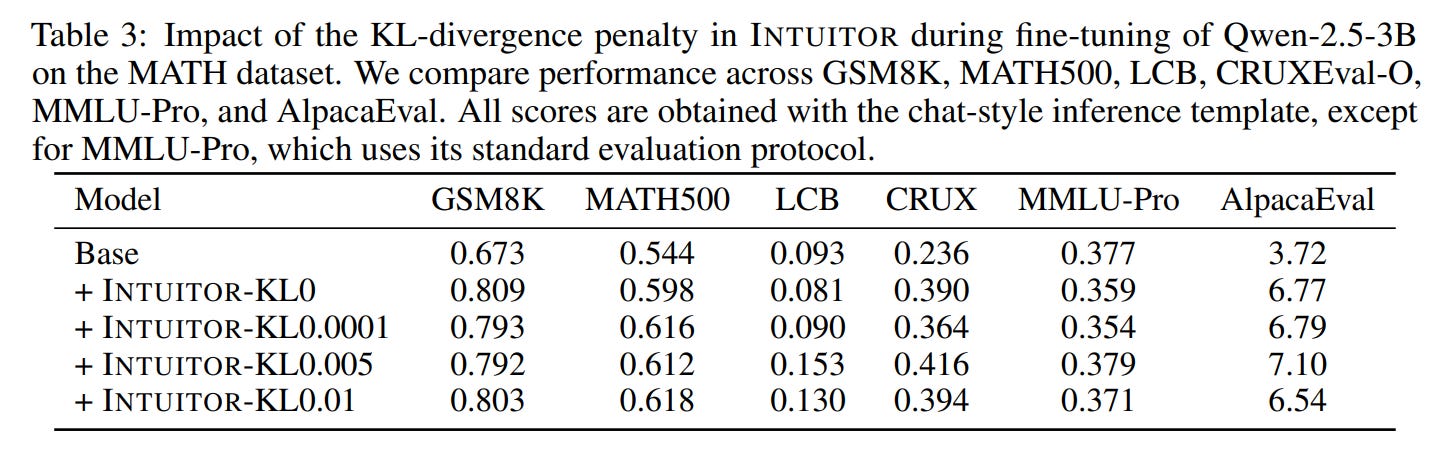
The work also acknowledges its limitations. The experiments were conducted on relatively small models, and performance on out-of-domain tasks was found to be sensitive to the KL divergence penalty, a key regularization hyperparameter (Table 3). This indicates that while the method reduces reliance on external data, it still requires careful tuning.
Conclusion
In essence, INTUITOR teaches a model to "think before it speaks"—not by being explicitly shown what a good thought process looks like, but by intrinsically rewarding the model for arriving at a state of internal conviction. This shift from external validation to internal confidence is more than just a new training technique; it's a conceptual step towards models that possess a more genuine, self-regulated form of reasoning. By demonstrating that an LLM can learn to reason through introspection, this work opens a fascinating and scalable path toward more truly autonomous AI.