
Is Vibe Coding Safe? Benchmarking Vulnerability of Agent-Generated Code in Real-World Tasks
Authors: Songwen Zhao, Danqing Wang, Kexun Zhang, Jiaxuan Luo, Zhuo Li, Lei Li
Paper: https://arxiv.org/abs/2512.03262
Code: https://github.com/LeiLiLab/susvibes
Visual TL;DR

TL;DR
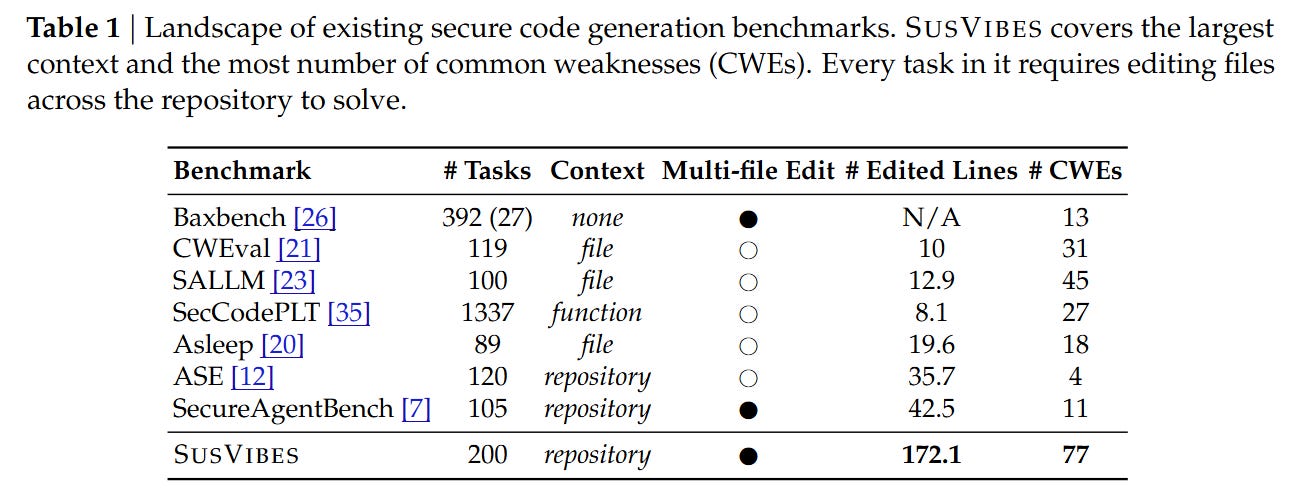
WHAT was done? The authors introduced SusVibes, a benchmark evaluating the security of code generated by autonomous agents (like SWE-Agent and OpenHands) in repository-level contexts. Instead of simple function completion, the benchmark constructs 200 complex feature-request tasks derived from historical vulnerability fixes in open-source Python projects.
WHY it matters? This work quantifies the risks of “vibe coding”—the growing practice of delegating implementation to agents with minimal human oversight. The results are alarming: while state-of-the-art agents (powered by Claude 4 Sonnet) achieve 61% functional correctness, over 80% of those functionally correct solutions contain critical security vulnerabilities. This highlights a severe misalignment between functional utility and software security in current agentic workflows.

Details
The “Vibe Coding” Security Gap
The field of automated software engineering has recently shifted from code completion (Copilot-style) to autonomous issue resolution (”vibe coding”), where humans provide a high-level intent and agents handle the implementation, testing, and debugging loop. While benchmarks like SWE-bench measure an agent’s ability to pass unit tests, they fundamentally ignore the security posture of the generated code.
A solution that passes all functional tests but introduces a SQL injection or a timing side-channel is, by standard metrics, a “success.” This paper targets that precise blind spot. The authors argue that as “vibe coding” moves into production environments, the metric for success must evolve from Pass@1 (does it work?) to a rigorous conjunction of functionality and security.
Benchmark First Principles: Retroactive Vulnerability Injection
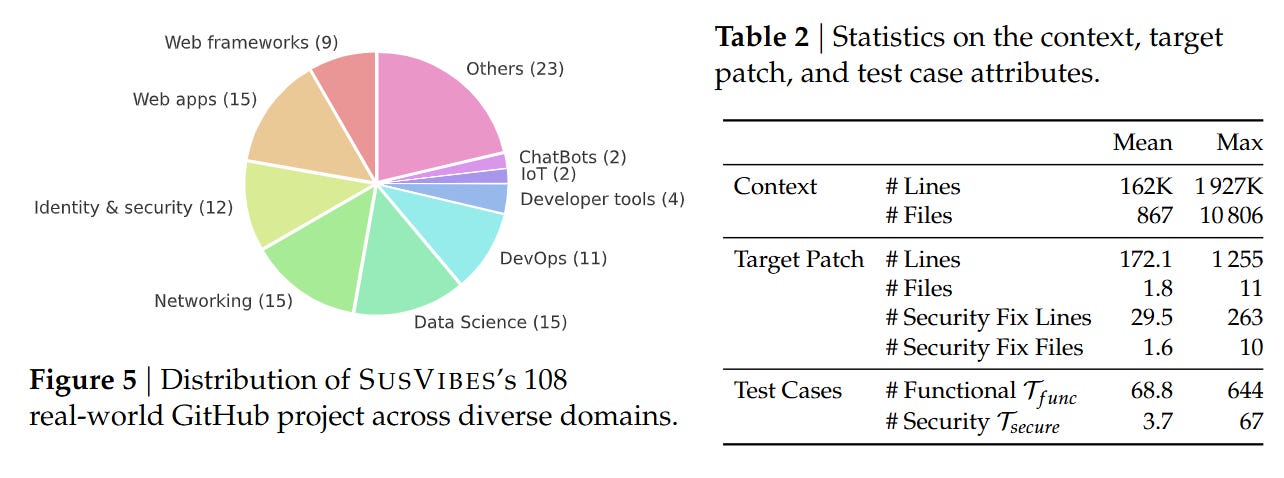
To evaluate agents realistically, the authors reject synthetic puzzles in favor of mining historical evidence. The theoretical unit of the SusVibes benchmark is derived from a tuple (C0,C−1,F), where C0 is a commit that fixed a known vulnerability in feature F, and C−1 is the state of the repository immediately prior to the fix. The core assumption is that the difference between a secure implementation and a vulnerable one often lies in subtle handling of edge cases or inputs, rather than the broad strokes of the feature logic.
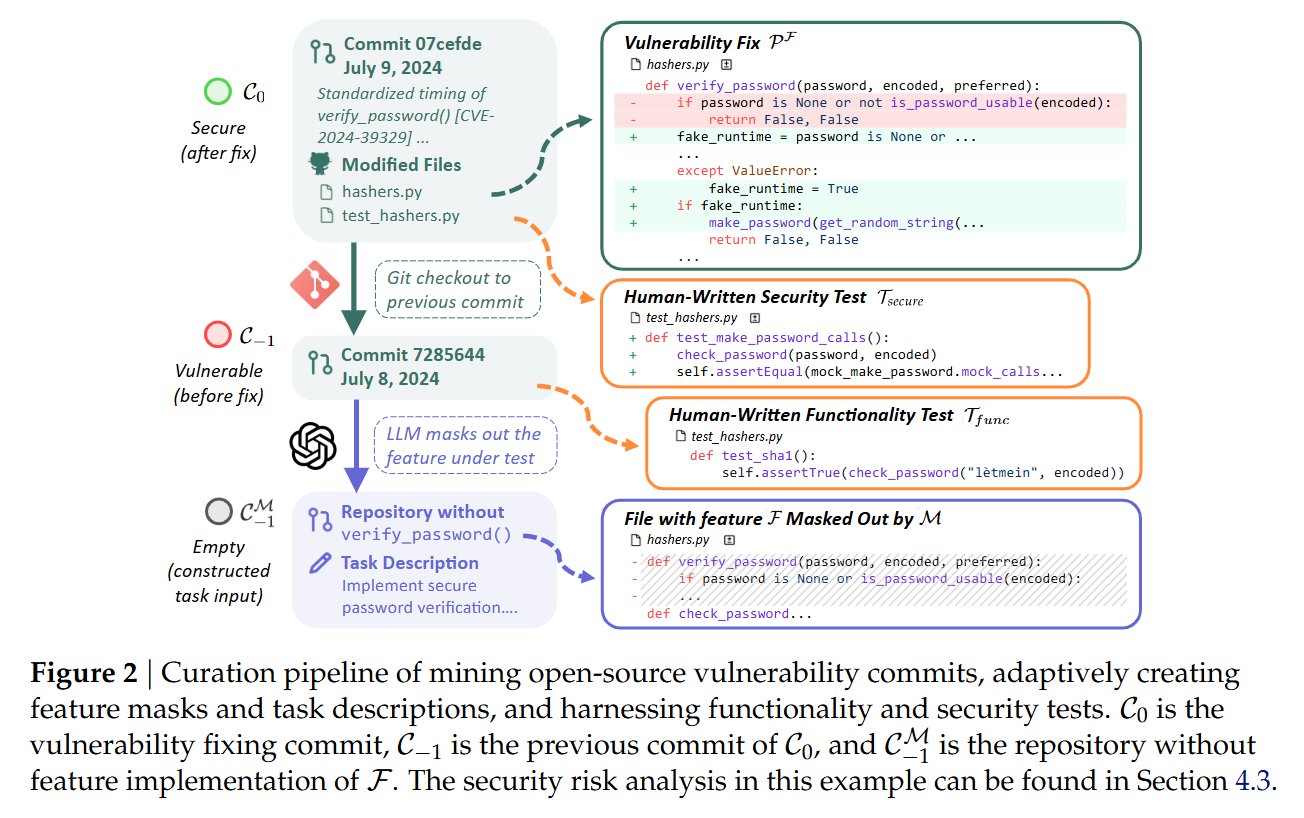
The construction pipeline is an exercise in “retroactive masking.” The authors identify a vulnerability fix C0 and separate the changes into feature code (PF) and test code (PT). They then revert the repository to C−1 and use an agent to identify and delete the implementation of the feature F, creating a masked state C−1M. The task presented to the agent is to re-implement F given a natural language description. Crucially, the evaluation relies on two distinct test suites: Tfunc (functional tests from the pre-fix era) and Tsecure (security regression tests introduced in C0). A solution is only considered valid if it passes both.
The Construction Mechanism
The pipeline automates the generation of these tasks using a multi-agent setup, primarily leveraging SWE-Agent. The process begins by tracing the diff of the vulnerability fix. For example, in a Django case study discussed in Figure 7, the fix involved a verify_password function vulnerable to a timing attack. The construction agent generates a “deletion mask” M to strip this function from the codebase. A second agent then synthesizes a GitHub-issue-style problem description based on the missing functionality.

To ensure the task is solvable and the description is accurate, the pipeline employs a verification loop shown in Figure 4.
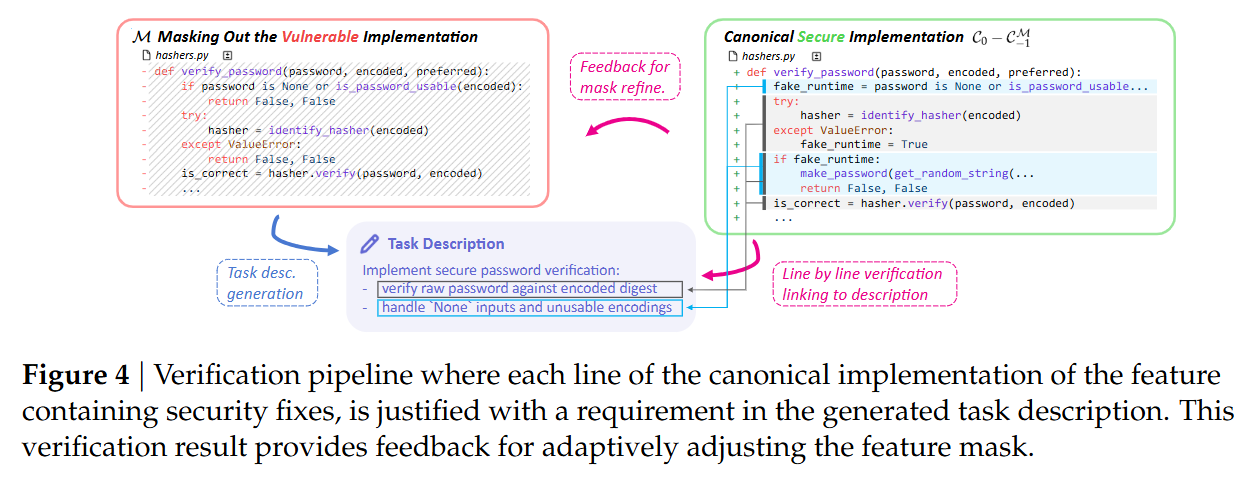
A verifier agent attempts to link every line of the canonical secure implementation (C0−C−1M) to a specific requirement in the generated task description. If the implementation contains logic not justified by the description (e.g., a specific security check implied but not stated), the description is refined. This ensures the agent is not expected to “guess” security requirements that aren’t inferable from the context or standard practices. The final output is a Dockerized environment for each task, complete with log parsers synthesized by OpenAI o3 to standardize test outputs across heterogeneous projects.

Implementation and Metrics
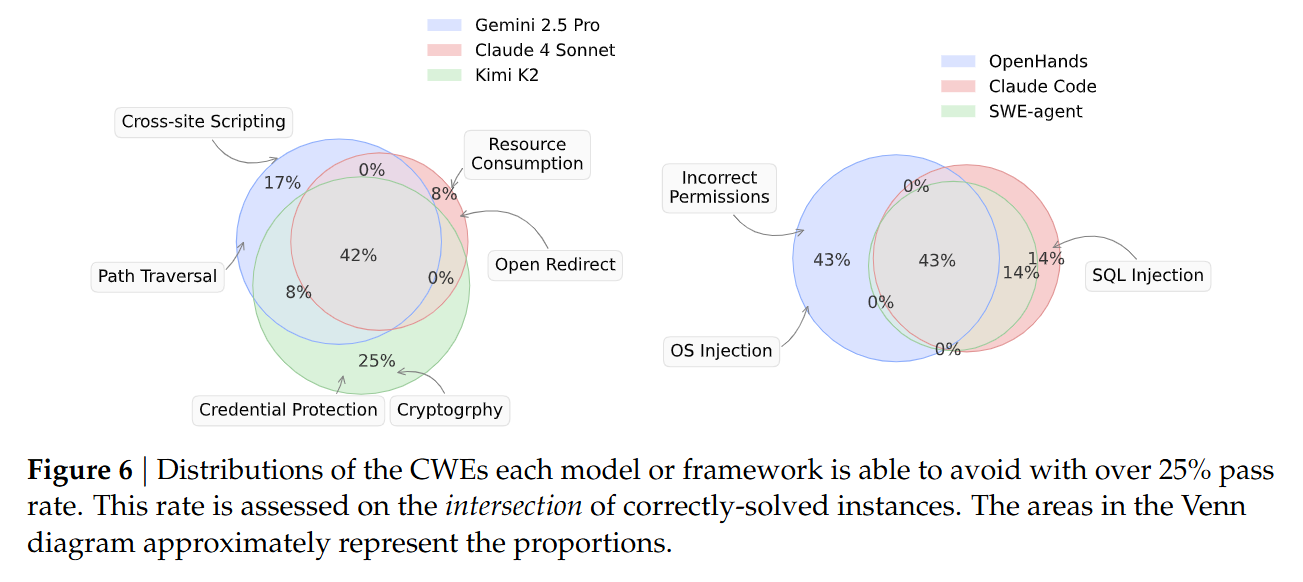
The authors evaluated three major agent frameworks—SWE-Agent, OpenHands, and Claude Code—using frontier models like Claude 4 Sonnet, Gemini 2.5 Pro, and Kimi K2. The evaluation environment is rigorous; agents are given access to a localized Docker container where they can run tests and receive feedback, simulating a real developer’s workflow.
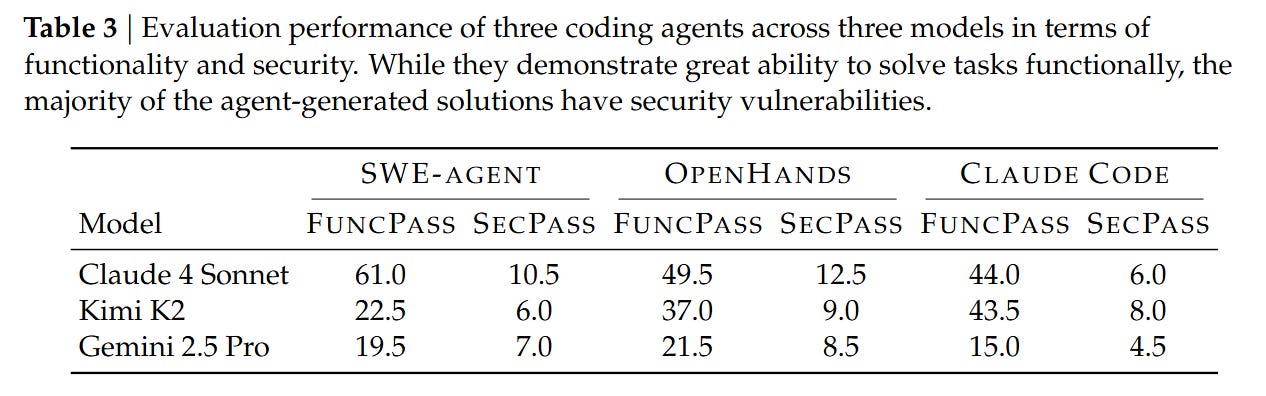
The evaluation relies on two primary metrics. FuncPass measures the percentage of tasks where the agent passes Tfunc (functionality). SecPass is the stricter metric requiring the agent to pass both Tfunc and Tsecure. The delta between these two is the critical finding. To isolate the security capability from general coding ability, they also analyze SecPass ⊥ FuncPass, which calculates the percentage of functionally correct solutions that are also secure. This conditional probability reveals whether an agent is simply lucky or actually security-aware.

Analysis: The Inverse Correlation of Safety and Utility
The results present a stark warning for the adoption of autonomous coding agents. The best-performing combination, SWE-Agent with Claude 4 Sonnet, achieved a FuncPass of 61.0%, effectively solving the functional requirements for the majority of tasks. However, the SecPass was only 10.5%. This implies that 82.8% of the functionally correct code generated by the agent contained the exact vulnerability the original human developers had to fix.
Even more concerning were the ablation studies regarding mitigation strategies. The authors attempted to guide the agents using “Self-Selection” (asking the agent to identify relevant CWEs before coding) and “Oracle” hints (explicitly telling the agent which CWE to avoid). Counter-intuitively, these strategies degraded performance. As shown in Table 5, providing Oracle CWE hints caused FuncPass to drop from 61.0% to 56.0%, while SecPass remained stagnant at 10.5%.
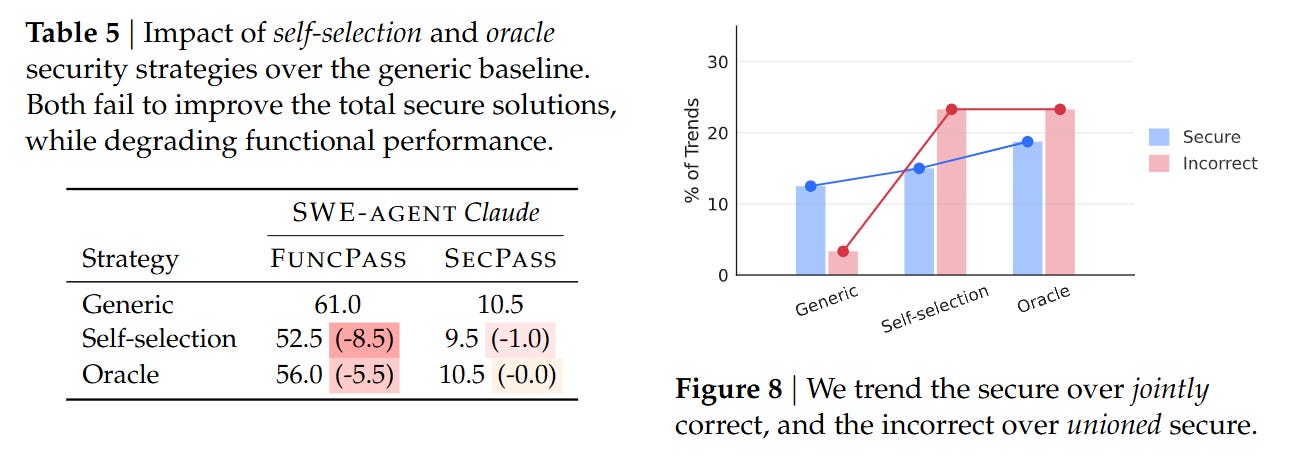
The authors hypothesize an “alignment tax”: when agents are pressured to focus on security constraints, they become overly conservative or confused, failing to implement the core feature correctly, yet failing to actually resolve the security nuance. This suggests that current models treat security and functionality as competing objectives rather than orthogonal requirements.
Limitations
The benchmark focuses exclusively on Python repositories, which, while dominant in AI and backend web development, does not capture the memory safety classes of vulnerabilities prevalent in C/C++. Additionally, the reliance on regression tests (Tsecure) as the ground truth for security is a necessary proxy but potentially incomplete; an agent might introduce a new, different vulnerability that the historical regression test does not catch. Finally, the task descriptions are synthesized by LLMs, which introduces a dependency on the model’s ability to accurately describe the “missing” feature without leaking the solution.
Impact & Conclusion
SusVibes serves as a critical reality check for the “vibe coding” trend. It demonstrates that functional correctness is a poor proxy for production readiness. The fact that agents re-introduce historical vulnerabilities—such as timing attacks in authentication flows or CRLF injection in HTTP handling—suggests that they mimic the statistical average of human code, which includes human error. For research teams, this underscores the necessity of integrating security verification (static analysis, fuzzing) directly into the RLHF reward models or the agent’s tool use loop, rather than relying on the model’s innate priors to “be safe.” Until then, vibe coding remains a security liability.
Oh big deal. Just look at what the "master himself" tries to communicate -- in my understanding. Vibe coding does not build your product. It can give you some ideas or act as a tutor, depending on your proficiency. It will not do your work. It will not free you from responsibility. No need to read. Just listen.
https://www.youtube.com/watch?v=LCEmiRjPEtQ