
K2-Think: A Parameter-Efficient Reasoning System
Authors: Zhoujun Cheng, Richard Fan, Shibo Hao, Taylor W. Killian, Haonan Li, Suqi Sun, Hector Ren, Alexander Moreno, Daqian Zhang, Tianjun Zhong, Yuxin Xiong, Yuanzhe Hu, Yutao Xie, Xudong Han, Yuqi Wang, Varad Pimpalkhute, Yonghao Zhuang, Aaryamonvikram Singh, Xuezhi Liang, Anze Xie, Jianshu She, Desai Fan, Chengqian Gao, Liqun Ma, Mikhail Yurochkin, John Maggs, Xuezhe Ma, Guowei He, Zhiting Hu, Zhengzhong Liu, Eric P. Xing
Paper: https://arxiv.org/abs/2509.07604
Code:
* https://github.com/MBZUAI-IFM/K2-Think-SFT
* https://github.com/MBZUAI-IFM/K2-Think-Inference
Model: https://huggingface.co/LLM360/K2-Think
Web: https://www.k2think.ai
UPDATE: an independent team debunked K2-Think performance, found many problems in evaluation including dataset contamination, unfair comparisons, misinterpreting other models results and giving more weight to high-scoring math benchmarks. They reevaluated K2-Think performance on MathArena benchmark and found K2-Think’s math capabilities are not even on par with the smaller GPT-OSS 20B model.
TL;DR
WHAT was done? The paper introduces K2-Think, a 32-billion parameter reasoning system built on the Qwen2.5 base model. It achieves frontier performance, matching or surpassing models orders of magnitude larger (like GPT-OSS 120B and DeepSeek v3.1) on complex reasoning tasks, especially in mathematics. This is accomplished not through scale, but via a synergistic, six-pillar recipe combining post-training (Long Chain-of-thought Supervised Finetuning and Reinforcement Learning with Verifiable Rewards) with advanced test-time computation (agentic "Plan-Before-You-Think", Best-of-3 sampling) and hardware optimization (speculative decoding on Cerebras Wafer-Scale Engines).
WHY it matters? K2-Think provides compelling evidence that the path to advanced AI reasoning is not solely paved with ever-larger parameter counts. It demonstrates a paradigm shift towards parameter efficiency, where a holistic, full-stack approach—from data curation and multi-stage training to intelligent inference-time computation and hardware co-design—can unlock state-of-the-art capabilities. By open-sourcing the entire system, this work democratizes access to frontier-level reasoning and offers a more sustainable and economically viable blueprint that addresses the growing challenge of inference cost, proving that smaller models can effectively "punch above their weight."

Details
Challenging the "Bigger is Better" Paradigm
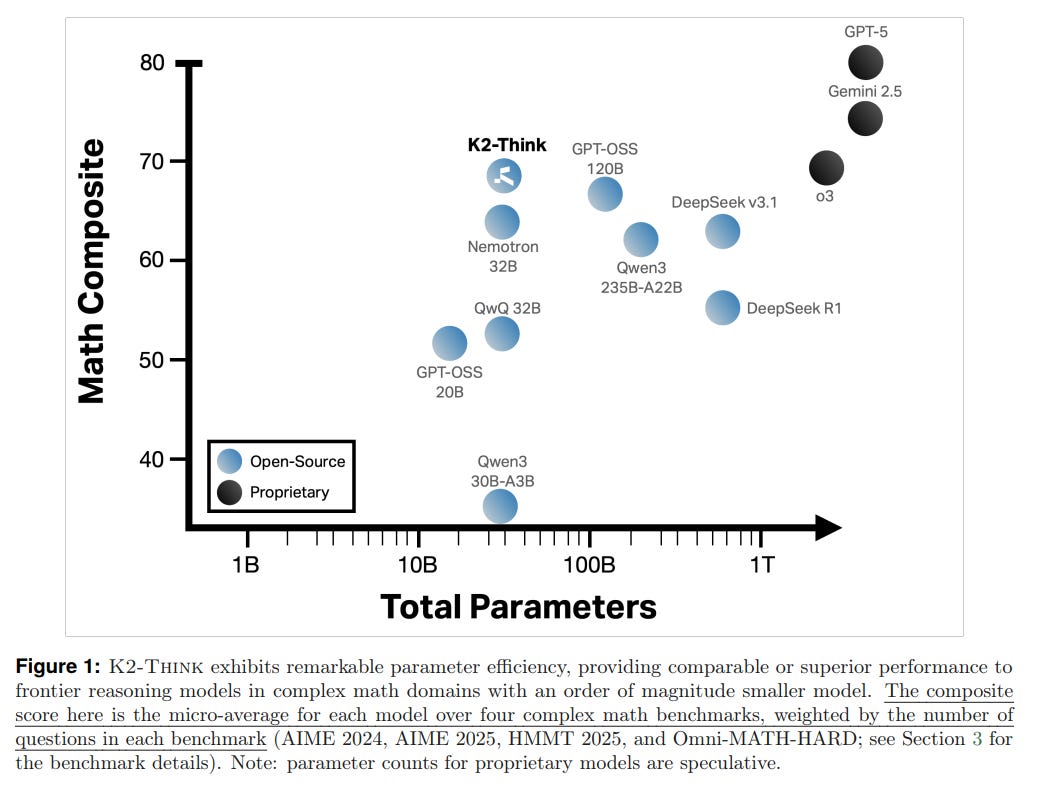
In the pursuit of advanced AI reasoning, the prevailing narrative has long been one of scale: larger models with more parameters yield better performance. This paper introduces K2-Think, a system that fundamentally challenges this assumption. By developing a comprehensive post-training and inference-time framework, the authors demonstrate that a relatively modest 32-billion parameter model can achieve performance on par with, and in some cases exceeding, models that are orders of magnitude larger. This work presents a compelling case for a new paradigm focused on parameter efficiency and holistic system design.
The Six Pillars of K2-Think's Methodology
The success of K2-Think is not attributed to a single breakthrough but to the synergistic integration of six key technical pillars, applied to a Qwen2.5-32B base model.
1. Post-Training Enhancement:
Long Chain-of-Thought Supervised Finetuning (SFT): The process begins by fine-tuning the base model on the
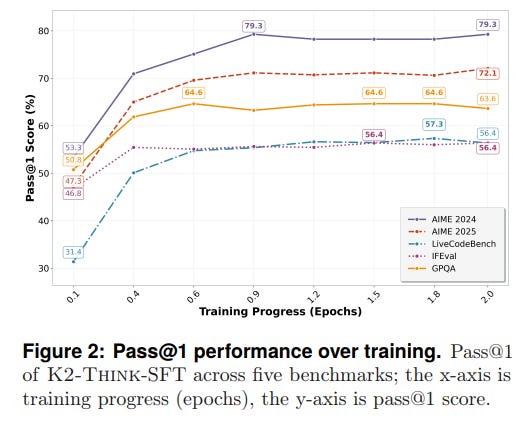
AM-Thinking-v1-Distilleddataset, which is rich in long chain-of-thought (CoT) reasoning traces. This phase instills the model with the ability to generate structured, step-by-step responses, a crucial foundation for complex problem-solving. Performance evaluations show a rapid and significant improvement over the base model during this stage (Figure 2).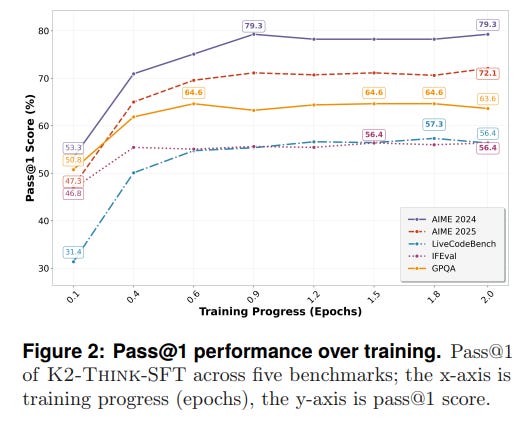
Reinforcement Learning with Verifiable Rewards (RLVR): Following SFT, the model is further trained using the GRPO algorithm on the multi-domain
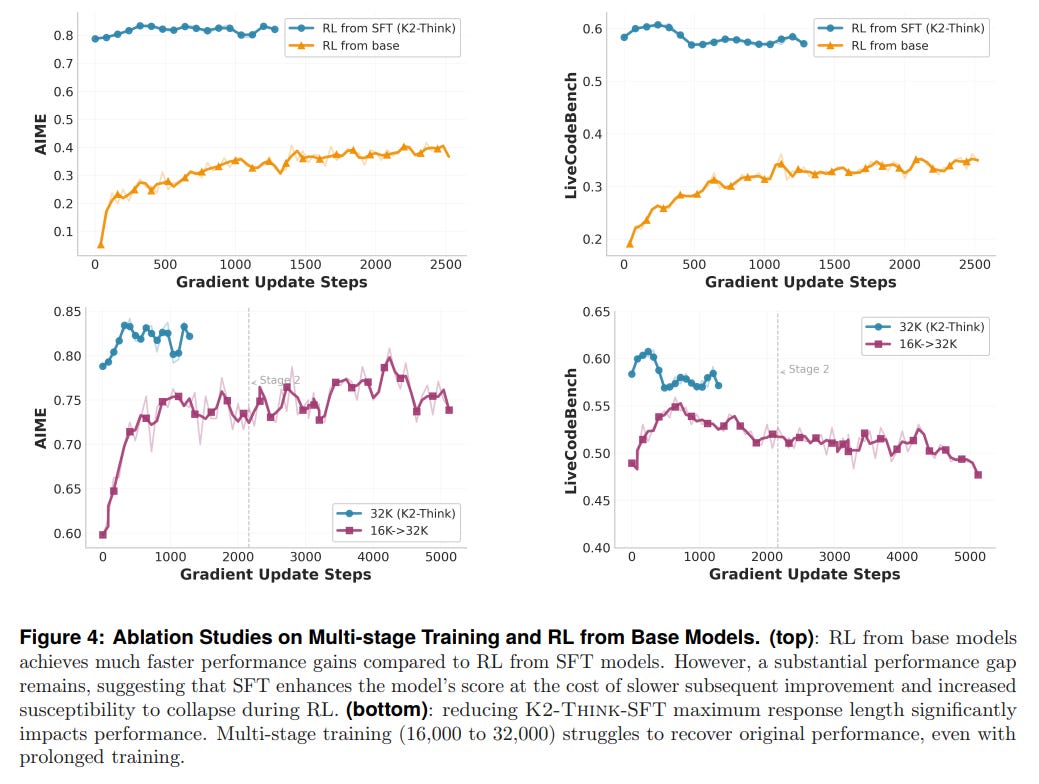
Gurudataset. Instead of relying on subjective human feedback, RLVR optimizes directly for correctness on verifiable tasks (e.g., math problems with a single correct answer). This approach reduces the complexity and high cost associated with collecting human preference data for RLHF, allowing the model to align more efficiently with objective correctness. An interesting finding from this stage is that while RLVR improves performance, starting from a heavily "SFTed" checkpoint limits the potential gains from RL, suggesting that strong SFT may constrain the model's ability to explore new reasoning strategies (Figure 4).
2. Advanced Test-Time Computation:
At inference, K2-Think employs a sophisticated scaffold to enhance its reasoning on the fly (Figure 5).

Agentic Planning ("Plan-Before-You-Think"): Before generating a solution, an external instruction-tuned model acts as a planning agent. It analyzes the user's query, extracts key concepts, and formulates a high-level plan. This plan is then prepended to the original prompt, providing a structured guide for the K2-THINK model.
Best-of-N (BoN) Sampling: The system generates three independent responses (N=3) to the augmented prompt. An independent LLM then acts as a verifier, comparing the candidates pairwise to select the most promising solution. This technique was chosen as a cost-effective balance, providing significant gains over a single generation.
3. Inference and Hardware Optimization:
Speculative Decoding & Cerebras Wafer-Scale Engine (WSE): To make the computationally intensive test-time methods practical, K2-Think is deployed on specialized hardware. Leveraging the Cerebras WSE and speculative decoding, the system achieves inference speeds upwards of 2,000 tokens per second. This remarkable performance is due to the WSE's unique architecture, which keeps all model weights in massive on-chip memory, leveraging 25 Petabytes per second of on-chip memory bandwidth, which is over 3,000 times more than the 0.008 PB/s provided by the latest NVIDIA B200 GPU. This eliminates the "memory shuttle" bottleneck faced by GPUs, which must continuously move weights between memory and compute cores, fundamentally transforming the usability of long-chain-of-thought reasoning from a minutes-long batch process into a near-instantaneous, interactive experience.
Experimental Validation: Performance and Efficiency
K2-Think's performance was rigorously evaluated across a suite of challenging benchmarks in Math, Code, and Science.
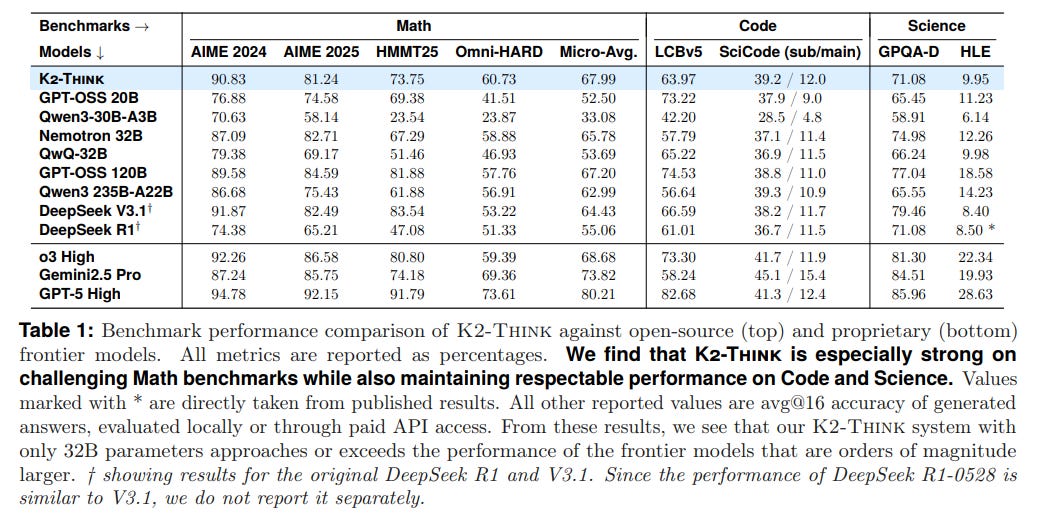
Dominance in Mathematical Reasoning: The system's primary strength lies in mathematics. It achieves a micro-average score of 67.99% across four difficult math benchmarks, outperforming top open-source models including the much larger DeepSeek V3.1 671B (64.43%) and GPT-OSS 120B (67.20%). This positions K2-Think at the frontier of open-source mathematical reasoning (Table 1).
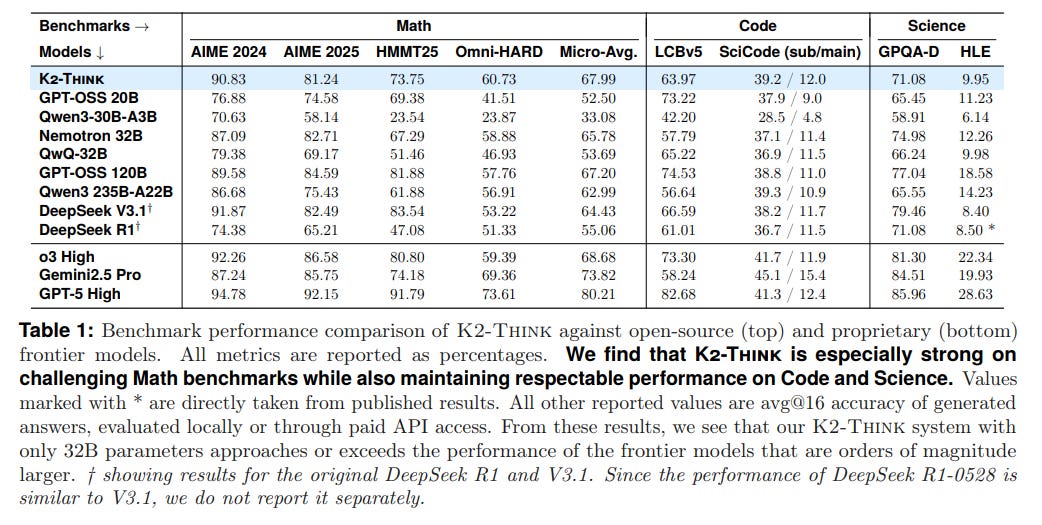
Versatile Performance: Beyond math, K2-Think demonstrates strong, competitive performance in coding (63.97% on LiveCodeBench) and science (71.08% on GPQA-Diamond), proving its versatility.
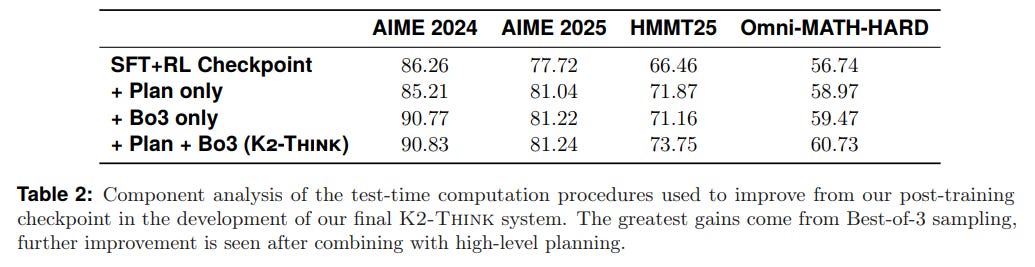
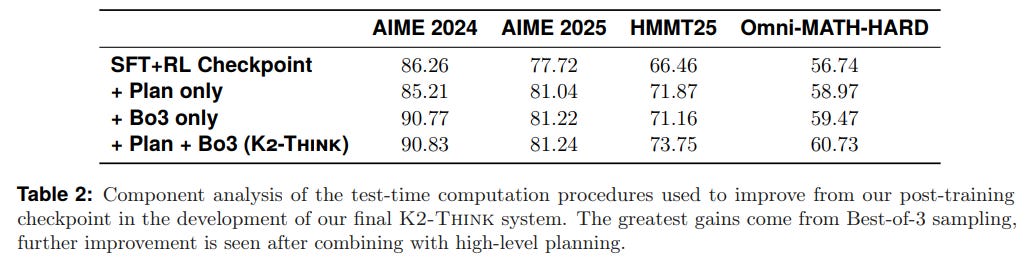
Quantifiable Efficiency Gains: The component analysis (Table 2) reveals that the test-time methods provide additive benefits. While Best-of-3 sampling offers the largest single boost, the gains from the "Plan-Before-You-Think" step are synergistic, combining to lift final performance by 4-6 percentage points.
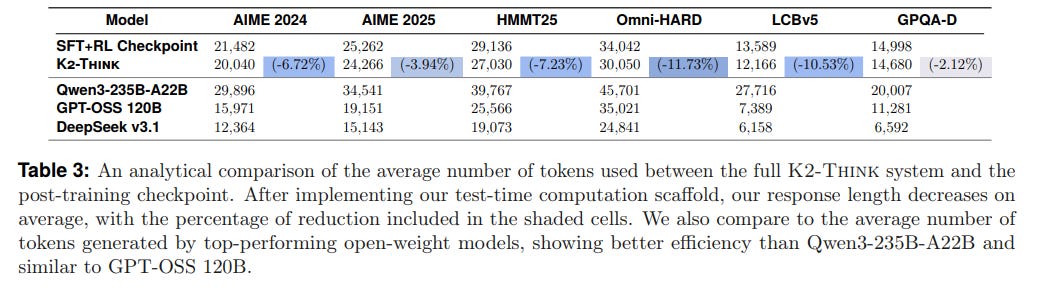
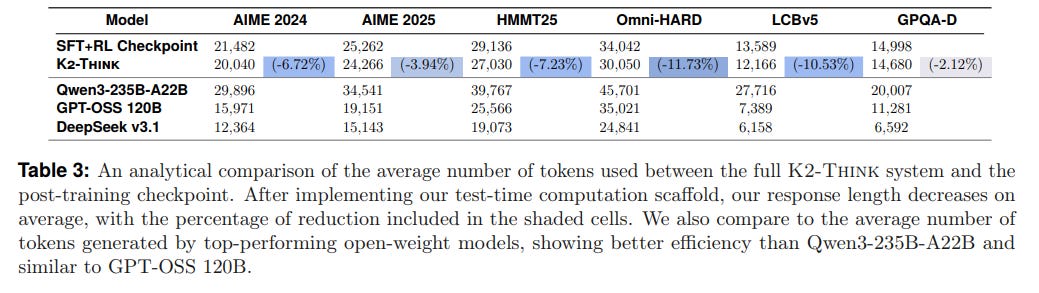
Crucially, the planning strategy also yields a surprising efficiency gain: it improves response quality while reducing the average number of tokens generated by nearly 12% (Table 3).
A Commitment to Responsible AI
The paper includes a thorough red-teaming analysis to assess K2-Think's safety profile across four dimensions: high-risk content refusal, conversational robustness, cybersecurity, and jailbreak resistance. The system achieves a solid overall safety score of 0.750 (Table 8).
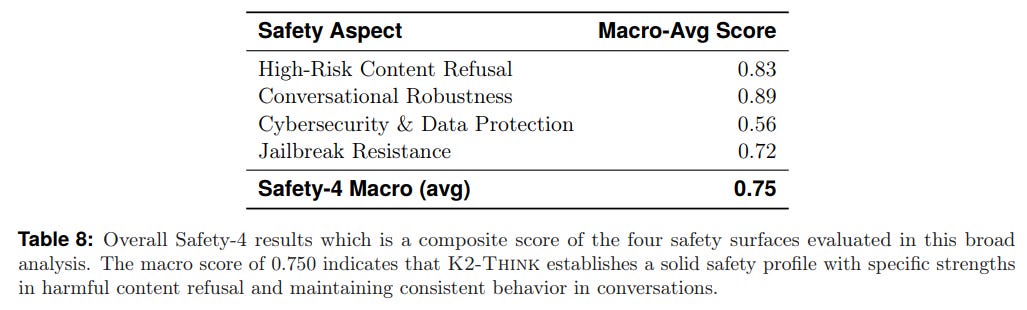
While it demonstrates strong capabilities in refusing harmful content and maintaining robustness in conversation (Tables 4, 5), the authors transparently report weaknesses. The model shows some vulnerability to indirect jailbreaking methods and in preventing cyberattack assistance or prompt extraction (Tables 6, 7), highlighting these as clear areas for future improvement.
Limitations and Future Outlook
The authors are candid about the system's limitations. The tension between SFT and RL—where a strong SFT checkpoint can limit subsequent RL gains—is a key finding that warrants further research into optimal multi-stage training strategies. Furthermore, the identified safety vulnerabilities underscore the ongoing challenge of building robustly aligned AI systems.
Conclusion
K2-Think is a significant contribution to the field of artificial intelligence. It provides a powerful demonstration that strategic, full-stack engineering—from post-training recipes to innovative test-time computation and hardware optimization—can be a more efficient path to frontier reasoning than sheer model scale. By open-sourcing their entire system, the authors have not only delivered a state-of-the-art reasoning model but also provided the community with a valuable and accessible blueprint for building the next generation of powerful and efficient AI. This work convincingly argues that the future of AI reasoning may lie not just in building bigger models, but in building smarter systems.