KernelEvolve: Scaling Agentic Kernel Coding for Heterogeneous AI Accelerators at Meta
Authors: Gang Liao, Hongsen Qin, Ying Wang, Alicia Golden, Michael Kuchnik, Yavuz Yetim, Jia Jiunn Ang, Chunli Fu, Yihan He, Samuel Hsia, Zewei Jiang, Dianshi Li, Uladzimir Pashkevich, Varna Puvvada, Feng Shi, Matt Steiner, Ruichao Xiao, Nathan Yan, Xiayu Yu, Zhou Fang, Abdul Zainul-Abedin, Ketan Singh, Hongtao Yu, Wenyuan Chi, Barney Huang, Sean Zhang, Noah Weller, Zach Marine, Wyatt Cook, Carole-Jean Wu, Gaoxiang Liu
Paper: https://arxiv.org/abs/2512.23236
TL;DR
WHAT was done? The authors developed KernelEvolve, an automated framework utilizing Large Language Models (LLMs) and graph-based search to generate high-performance Triton kernels. The system integrates a retrieval-augmented generation (RAG) pipeline to inject hardware-specific knowledge (for NVIDIA, AMD, and Meta’s custom MTIA silicon) into generic coding agents, automating the optimization of both compute-intensive and data-preprocessing operators.
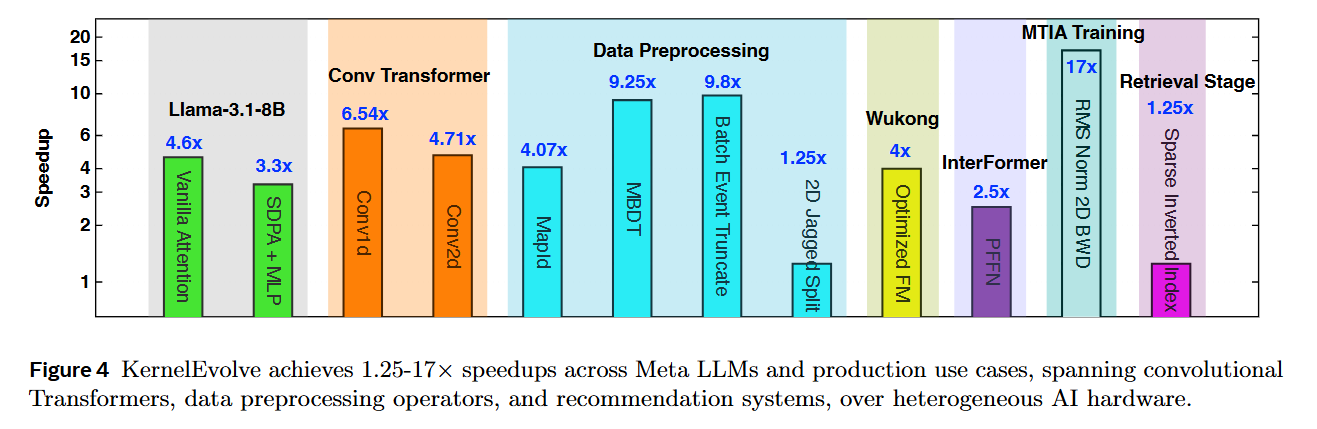
WHY it matters? This represents a strategic shift in AI infrastructure: decoupling model architecture from hardware constraints. By achieving 100% correctness on KernelBench and demonstrating up to 17× speedups over PyTorch baselines in production, KernelEvolve proves that agents can manage the combinatorial explosion of operators and hardware targets—crucially enabling the adoption of proprietary silicon (MTIA) where public training data for LLMs is non-existent.
Details
The Heterogeneity Bottleneck
The central conflict in modern AI infrastructure is the “curse of dimensionality” facing kernel development. In production environments like Meta’s ads ranking system, the workload is not limited to standard matrix multiplications (GEMMs). It involves a long tail of over 200 distinct operators, ranging from heavy Transformer blocks to irregular data preprocessing tasks like jagged tensor operations and feature hashing. This complexity is compounded by hardware heterogeneity; a single model might need to run on NVIDIA H100s, AMD MI300s, and Meta’s custom MTIA accelerators.

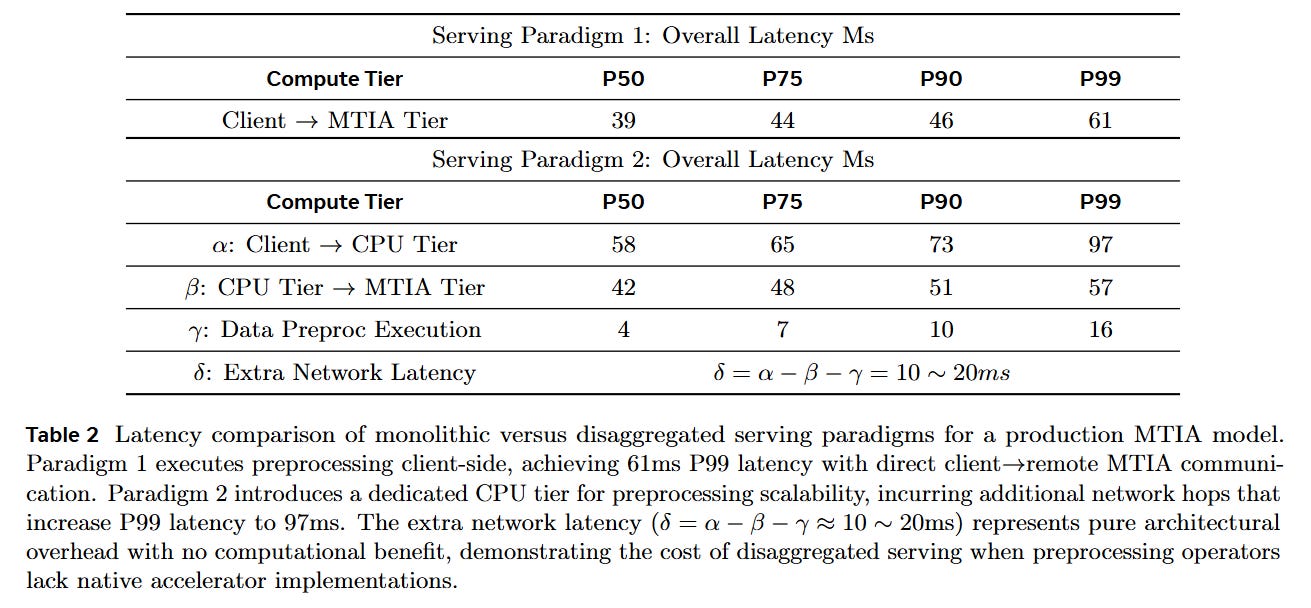
Traditionally, supporting a new hardware backend requires months of manual effort to port and tune these thousands of operator variants. This manual approach creates a deployment barrier: if a specific preprocessing kernel is missing for a new accelerator, the entire model cannot be deployed, or it must be split across CPUs and accelerators, incurring massive network latency penalties.
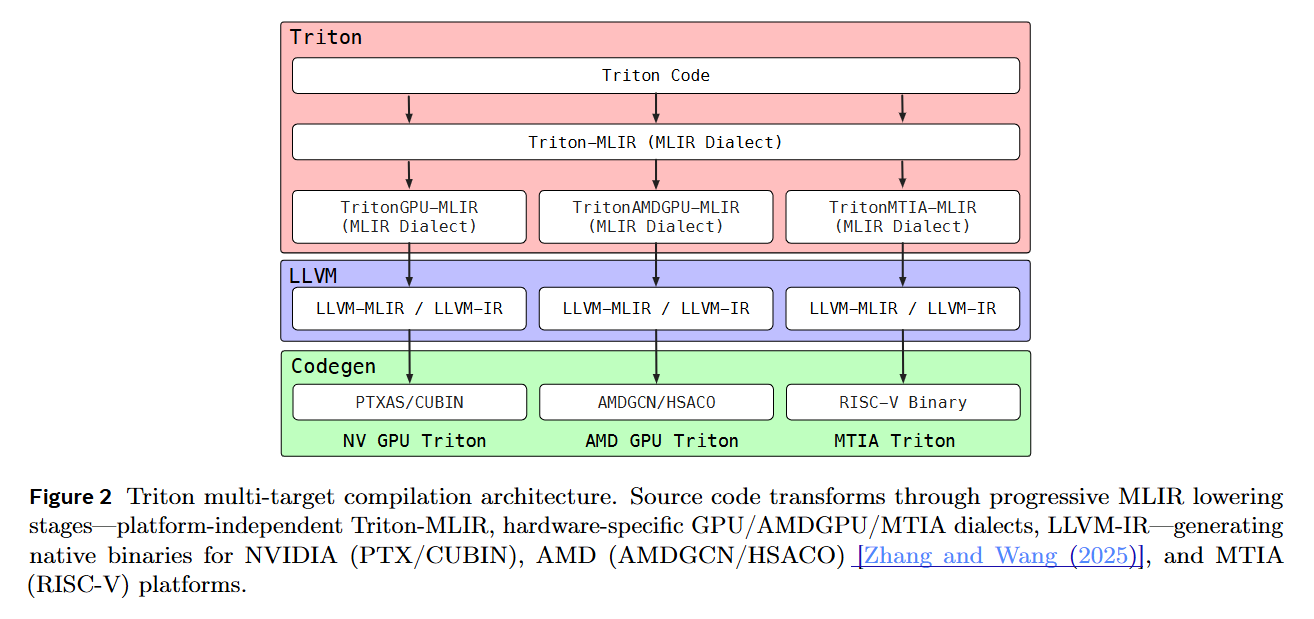
KernelEvolve addresses this by treating kernel generation not as a coding task, but as a search problem, utilizing the Triton DSL to abstract away the lowest-level assembly while retaining control over memory hierarchy.