
Large Language Models Do Not Always Need Readable Language
Authors: Jiayi Zhu, Haoxuan Peng, Junxi Wang, Liang Ke, Chen Zhang, Linfeng Zhang
Paper: https://arxiv.org/abs/2606.19857
Code: N/A
Model: N/A
TL;DR
WHAT was done? The authors introduce BabelTele, a framework for eliciting high-density, model-centric, and non-human-readable textual representations that optimize context-compression for LLM-to-LLM communication without requiring fine-tuning or specialized architectural changes.
WHY it matters? It demonstrates that human readability and model decodability can be decoupled, showing that LLMs can process highly compressed symbolic and cross-lingual strings (reducing context footprint by up to 72.1% while preserving 99.5% semantic fidelity) across heterogeneous architectures in a zero-shot manner. This shifts the paradigm of LLM interfaces from human-centric natural language to machine-native communication.

Details
Linguistic Redundancy and the Context Bottleneck in LLM Pipelines
Traditional language model alignments force LLMs to process and output text formatted for human consumption. While natural language conventions like strict grammatical rules, syntactic markers, and narrative structures are critical for human readers, they introduce substantial information redundancy. In large-scale agentic systems, document QA pipelines, and long-horizon multi-agent interactions, this redundancy rapidly exhausts valuable context windows and drives up computational costs. While existing prompt compression techniques like LLMLingua-2 and Selective Context attempt to alleviate this constraint, they remain bound to the distribution of human-readable text. Conversely, learned embedding approaches like Gist Tokens require access to intermediate activations or specialized weight fine-tuning. The paper addresses this gap by introducing BabelTele, which departs from conventional natural language structures entirely, exploring whether discrete, non-standard, and highly compact textual representations can serve as an efficient, zero-shot medium for machine-only communication.
Readability-Relaxed Semantic Projection: The Mathematical Substrate of Symbolic Collapse
The core methodology of BabelTele is formulated as a readability-relaxed semantic projection. Let x∈X represent a verbose, human-readable source document. A compressor language model, denoted as C, maps the input document to a compressed textual representation z∈Z, which is a sequence of discrete tokens optimized for information density. This compressed representation is then directly consumed by a reader model R to generate the final downstream task output y∈Y. Drawing from classical information theory, this process is formalized as a constrained Rate-Distortion optimization problem:
minz∣z∣ subject to D(R(z),R(x))≤ϵ
where ∣z∣ measures the rate (length of the compressed sequence in tokens), D represents a semantic distortion metric evaluating the divergence in downstream task utility (such as the difference in downstream QA log-likelihoods or exact match accuracy between the compressed and uncompressed states), and ϵ is a small, task-specific tolerance threshold. The objective is to minimize the token footprint while keeping semantic loss negligible.
This projection is realized by stripping away the human-readability prior through black-box instruction tuning. The resulting “Symbolic Collapse” is governed by three fundamental principles. First, Omnilingual Lexical Selection instructs the model to move freely across all known human languages and scripts to select high-density lexical units. Second, Symbolic Collapse explicitly mandates replacing verbose syntax and grammatical markers with emojis, mathematical operators, and punctuation. Finally, Recoverable Semantic Density ensures that logical structures, quantitative metrics, and conditional dependencies are folded without loss, allowing heterogeneous reader models to decode the message without a shared external codebook.
From Verbose Prose to Compressed Graphs: A Structural Walkthrough
To understand how a single input flows through the system, consider a scientific explanation of photosynthesis consisting of 45 tokens. When passed through the compressor C using the default compression prompt, the original text—which explains how plants take in carbon dioxide and water to gain electrons and produce glucose—undergoes symbolic collapse.
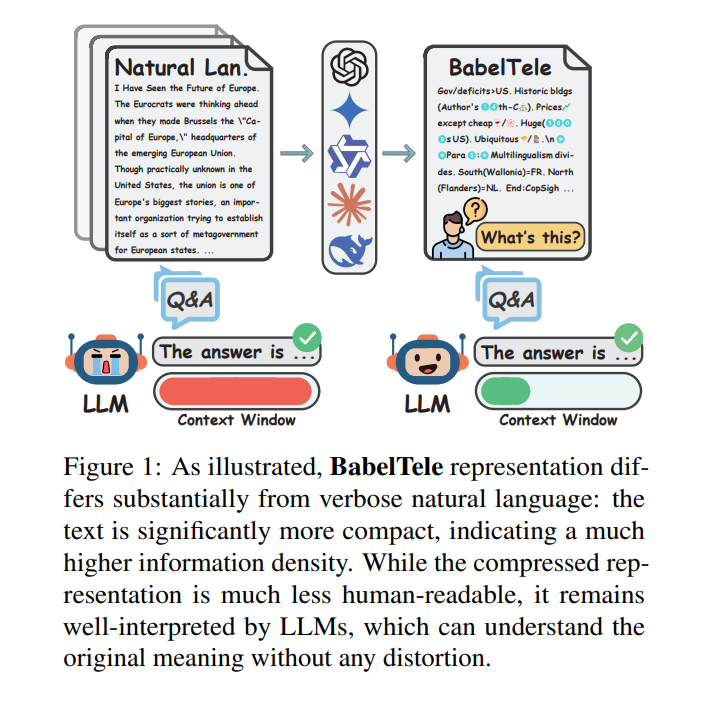
As illustrated in Figure 1, the compressor maps this verbose description into an eleven-token BabelTele string: 光合: CO2+H2O::(ox/red)<>O2!+Glucose.💧-e-,CO2+e-. In this compact state, the model leverages Chinese characters to compactly represent complex biological processes (”光合”), utilizes standard chemical notation, and employs punctuation and emojis to denote states, such as the water droplet emoji 💧 representing moisture and electron transfer.
When this output is fed directly into the reader model R as shown in the system overview, the model interprets the relational symbols and scientific constants without requiring a pre-defined schema. On a larger scale, as demonstrated in the document-level legal judgment example in Figure 10, entire paragraphs of a judicial ruling are mapped into highly condensed key-value matrices and logical flowcharts. This structure maps plaintiffs and defendants to mathematical variables like Greek letters π and Δ, structures chronological events using chronological symbols, and records verdicts using logical indicators such as green checkmarks and red crossmarks. The reader model successfully processes this dense stream to perform downstream QA or retrieve specific details with minimal semantic distortion.

Instructional Probing and Black-Box Deployments
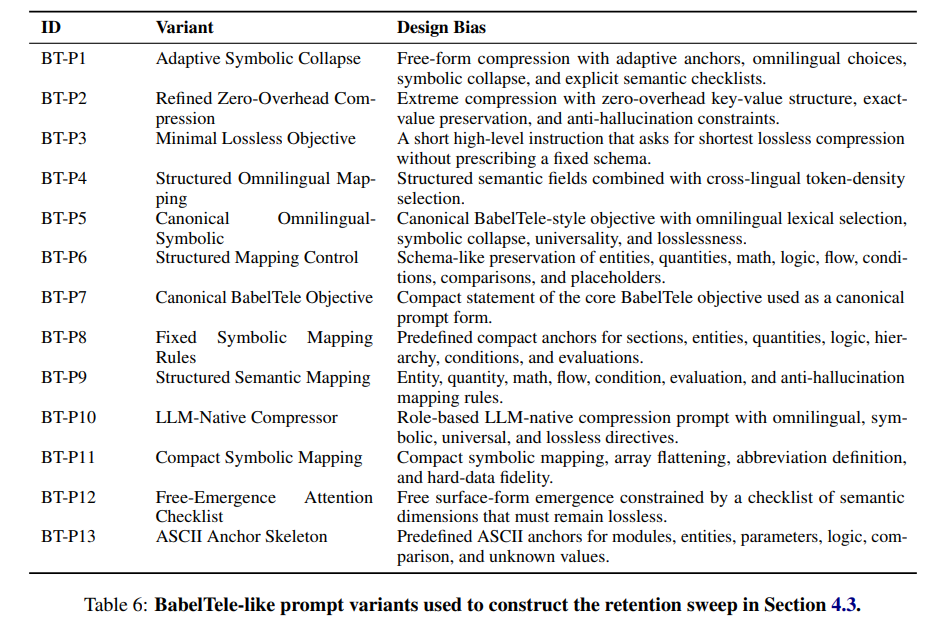
A defining feature of this methodology is its ease of implementation, requiring no gradient updates, parameter fine-tuning, or tokenizer adjustments. The experiments utilize standard, off-the-shelf instruction-tuned models including Gemini 3.1 Pro, GPT-5.4, Claude Sonnet 4.6, and various members of the Qwen and Llama families under black-box API conditions. The compression behavior is elicited entirely through thirteen carefully engineered prompt variants, labeled BT-P1 through BT-P13, which are detailed in Table 6. These variants introduce different architectural biases, ranging from free-form “syntactic anarchy” to structured mapping schemas that constrain output logic using strict rules like if[Cond]->[Act] and *(entity):K=V. The validation of this framework spans multiple benchmarks, including QuALITY for long-document question answering, MeetingBank for conversational analysis, and the Code Repo QA Long subset of LongBench v2 to test extreme context windows of up to 1.65 million tokens. To ensure reproducibility across these stochastic evaluations, tests are run multiple times and the average performance is reported.
Decoupling Readability from Decodability: Empirical Performance and the Space-Time Trade-off
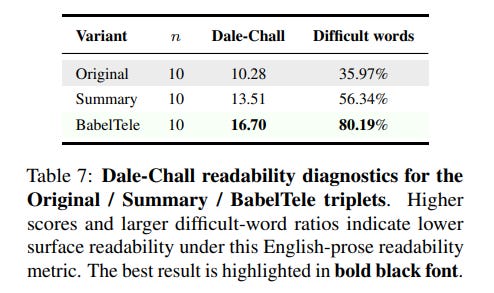
The empirical evaluations validate that human readability and model comprehension can indeed be decoupled. Readability diagnostics reported in Table 7 show that BabelTele representations exhibit a dramatic drop in human readability, yielding a high Dale-Chall score of 16.70 and a difficult-word ratio of 80.19%.
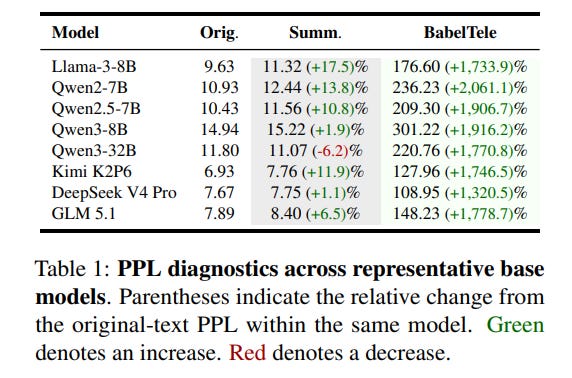
Perplexity (PPL) diagnostics across base models, summarized in Table 1, demonstrate that BabelTele is highly atypical under standard natural-language distributions, showing order-of-magnitude increases in perplexity such as a surge from 9.63 to 176.60 in Llama-3-8B.
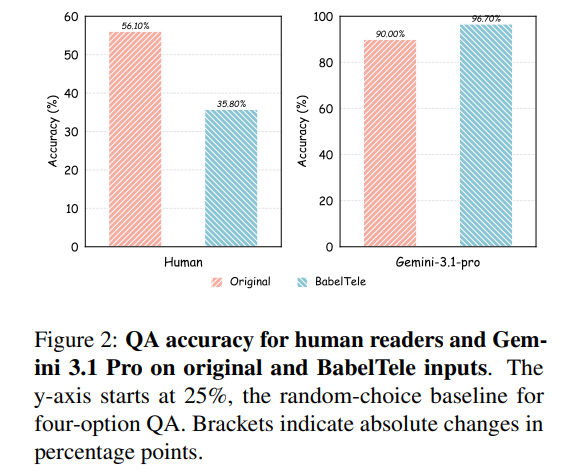
As a consequence, human reader QA accuracy collapses from 56.10% to 35.80% on these inputs, as highlighted in Figure 2. In contrast, Gemini 3.1 Pro maintains its accuracy, moving from 90.00% to 98.70%, proving that what appears as meaningless gibberish to humans is highly informative to instruction-tuned models.
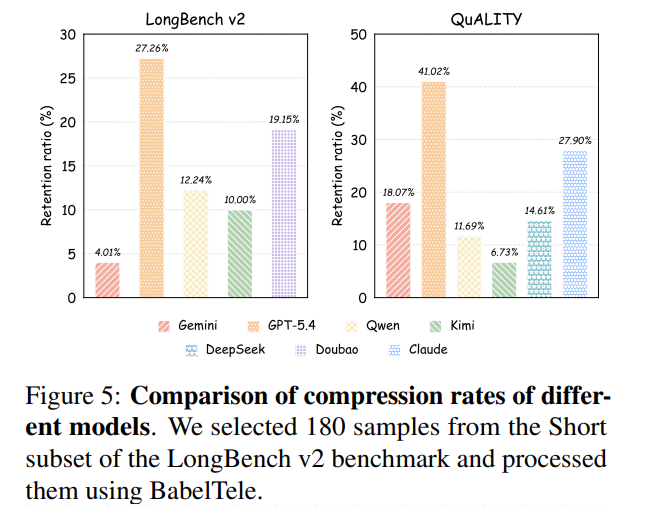
Beyond single-model environments, the cross-model transferability of BabelTele is validated through exhaustive testing. As shown in Figure 5, different compressors exhibit varying compression strengths, with Gemini 3.1 Pro being the most aggressive (exceeding 95% compression) and GPT-5.4 being more conservative (retaining roughly 75% of the context).
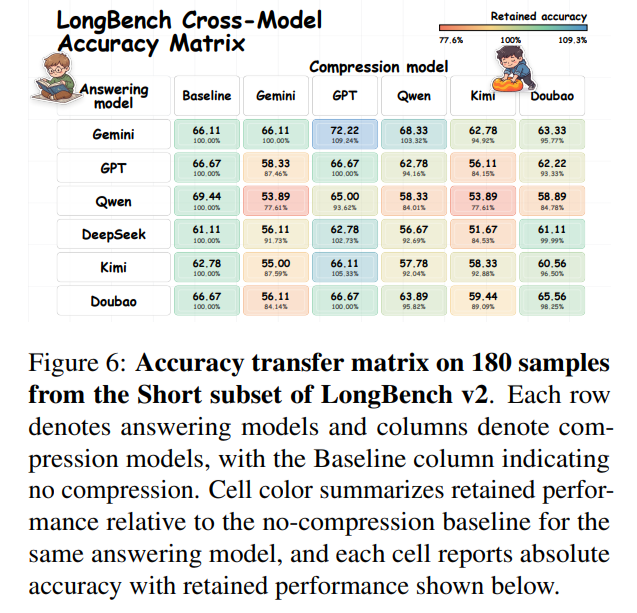
Crucially, despite these variations, the compressed text transfer matrices in Figure 6 (for LongBench v2) and Figure 7 (for QuALITY) reveal that strong compressors generate highly portable symbolic representations. Although BabelTele is not a fully universal cipher, it exhibits systematic portability: robust models consistently decode representations generated by other models without fine-tuning.
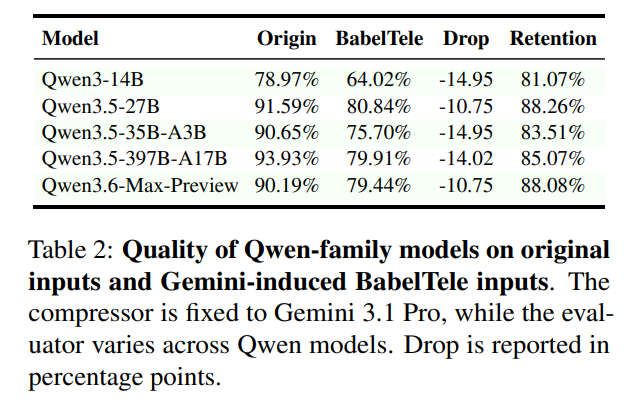
However, this transferability does not scale monotonically with reader model size. As evaluated on Qwen-family models of varying sizes in Table 2, downstream accuracy retention remains within a narrow band (10.75 to 14.95 percentage points drop), indicating that cross-model comprehension depends heavily on model-specific robustness to the compressor’s symbolic style rather than raw parameter scale.
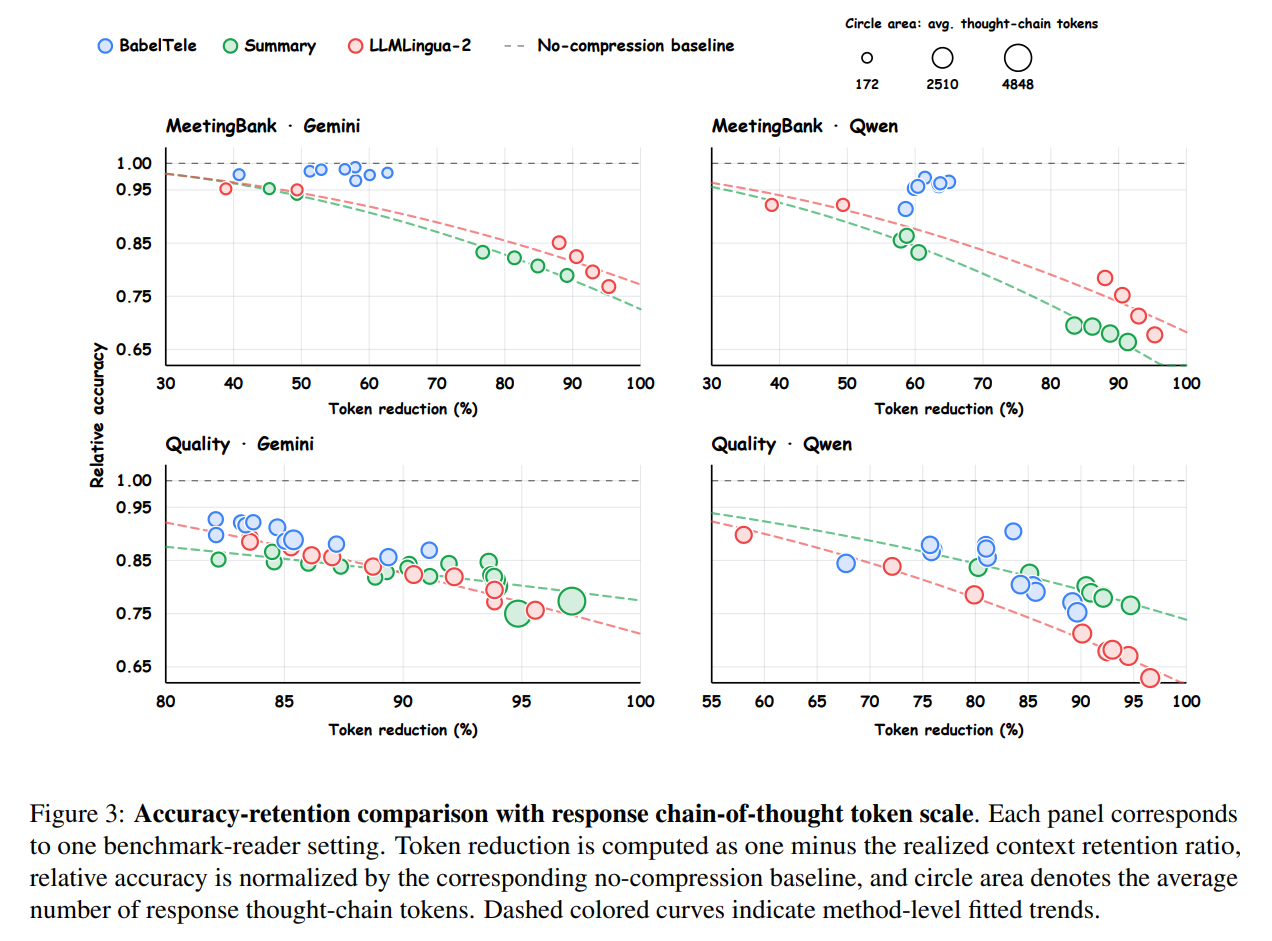
Furthermore, the accuracy-retention curves in Figure 3 show that BabelTele consistently outperforms abstractive summaries and extractive baselines like LLMLingua-2. While other methods experience sharp accuracy drops under high compression, BabelTele maintains its semantic fidelity even at extreme context reductions.
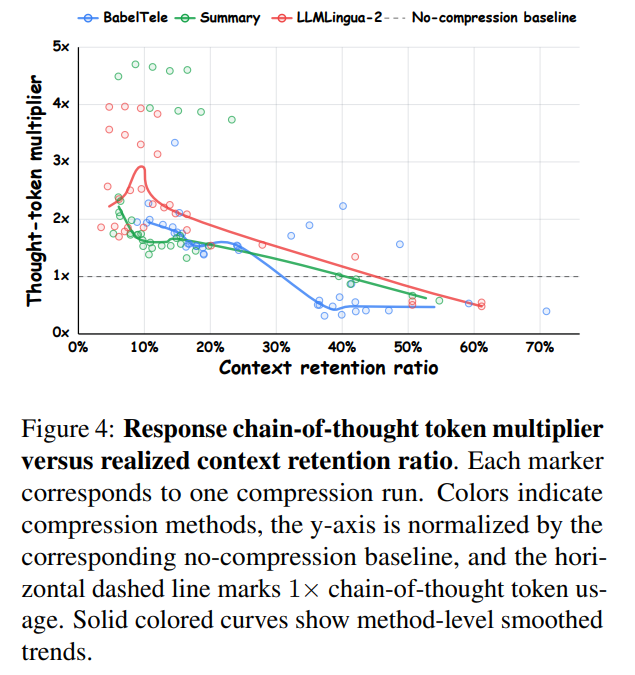
However, this high compression ratio triggers an important space-time trade-off. As analyzed in Figure 4, stronger input-side context compression leads to a rise in the reader model’s response chain-of-thought (CoT) tokens. When the input sequence is highly dense and stripped of redundant syntax, the reader model must allocate more computational steps and reasoning tokens to reconstruct the underlying evidence. This finding suggests that optimal deployment of model-native communication requires balancing input-side token savings against output-side reasoning overhead.
Tracing the Evolution of Non-Human Communication Protocols
This work builds upon a rich lineage of prompt and context compression, bridging the gap between discrete text-level compression and machine-to-machine emergent communication. Standard approaches such as LLMLingua, LLMLingua-2, and RECOMP primarily operate by filtering, summarizing, or selecting span boundaries while adhering to human linguistic conventions. On the other hand, learned compression methods like Gist Tokens and AutoCompressors map prompts into soft embeddings or internal activation spaces. While effective, these embedding-based methods require access to model weights and are restricted to homogeneous architecture pipelines. BabelTele distinguishes itself by utilizing discrete textual forms, enabling zero-shot communication across heterogeneous systems without requiring weight optimization. This relates closely to emergent communication in multi-agent reinforcement learning, but utilizes the latent linguistic and symbolic capabilities already present within pre-trained instruction-tuned LLMs.
The Dark Side of Symbolic Collapse: Security, Auditing, and Alignment Risks
Despite its impressive efficiency gains, BabelTele introduces significant challenges in model safety, alignment, and interpretability. Because these intermediate representations are entirely unreadable to human operators, they bypass traditional content moderation, safety filtering, and alignment audits. In multi-agent systems communicating via BabelTele, toxic, biased, or malicious behaviors could propagate through the network undetected, posing severe risks if applied to safety-critical domains. Additionally, the empirical evaluations are restricted to a selected suite of benchmarks and highly capable, instruction-tuned frontier models. The capability to successfully encode and decode these complex symbolic structures appears to be an emergent property of scale, meaning smaller or weaker models may experience catastrophic performance degradation. Finally, because this study is primarily empirical, the exact mechanistic process of how different transformer architectures align on these symbolic states remains unexplained.
The Shift Toward Model-Native Communication Systems
The strategic implications of this research are profound. By showing that LLMs can spontaneously communicate through highly dense, symbolic, and cross-lingual mediums, this work challenges the assumption that AI-to-AI interaction must mimic human dialogue. In practical terms, implementing BabelTele-like protocols within multi-agent networks, long-context memory layers like MemGPT, and distributed workflows can dramatically lower context processing latency and operational costs. While further work is required to establish robust auditing frameworks and standardize symbolic vocabularies, this paper marks an important milestone. It successfully establishes a foundation for developing model-native communication protocols, offering a highly practical, zero-shot approach to improving efficiency across the LLM ecosystem.
