
Latent Thought Flow: Efficient Latent Reasoning in Large Language Models
Authors: Xiandong Zou, Jing Huang, Jianshu Li, Pan Zhou
Paper: https://arxiv.org/abs/2606.16222
Code: N/A
Model: N/A
TL;DR
WHAT was done? The paper introduces Latent Thought Flow (LTF), a reward-proportional framework that models latent reasoning in Large Language Models as variable-length continuous trajectories, optimized using a continuous Generative Flow Network (GFlowNet) objective with an entropy-weighted subtrajectory loss and a reference-prior regularizer.
WHY it matters? LTF mitigates the “linguistic space bottleneck” of explicit Chain-of-Thought (CoT) by keeping intermediate deliberation internalized within the continuous representation space of the LLM. Rather than collapsing onto a single deterministic path like traditional reinforcement learning, LTF learns a diverse distributional posterior over latent reasoning traces, enabling adaptive test-time computation and improving task accuracy while drastically reducing the sequence length overhead.

Details
The Bottleneck of Externalized Articulation
In the pursuit of complex multi-step reasoning, current paradigm-defining Large Language Models have relied heavily on explicit token generation, such as Chain-of-Thought prompting. While highly interpretable, this approach suffers from a severe linguistic space bottleneck, where the model must commit its intermediate deliberations to discrete, sequential textual tokens. This requirement incurs massive computational overhead during autoregressive decoding and forces non-linear cognitive states into a strictly serialized, verbose textual representation. While early attempts at latent reasoning have sought to bypass this text-generation bottleneck by keeping intermediate representations continuous, they typically rely on deterministic paths trained via distillation, compression, or direct reward maximization. These methods fail to provide a principled way to navigate the multi-modal manifold of possible reasoning paths, frequently falling victim to posterior collapse or generating redundant latent thoughts.
GFlowNets in Continuous Hidden Manifolds
Latent Thought Flow reformulates internal LLM deliberation from a first-principles perspective of generative flow networks over continuous spaces. Instead of mapping a question x to a single deterministic hidden trajectory, LTF models intermediate reasoning as a variable-length continuous trajectory τ=(z1:T,⊥), where each zt∈Rdz represents a continuous thought vector within the model’s latent representation space, dz denotes the latent space dimensionality, and ⊥ represents an adaptive stopping decision. The state transition is modeled stochastically using a conditional Gaussian density qφ(zt+1∣st)=N(μφ(st),diag(σφ2(st))), where st=(hx,z1:t) is the historical context state initialized from the input query embedding hx=pϕ(x). The stopping probability is governed by the language head predicting the occurrence of a specialized rationale end token, π⊥(st)=pψ(⟨eosr⟩∣st). By utilizing continuous GFlowNet theory [review], the latent sampler learns to match a target distribution p∗(τ∣x,y) proportional to a custom accuracy-efficiency terminal utility Rx,y(τ), allowing the network to distribute probability mass over diverse yet highly effective and concise reasoning pathways.
The Deliberation Pipeline: From Query to Continuous Resolution
To understand how a single input flows through the system, consider a mathematical query x entering the model, as represented in Figure 1.
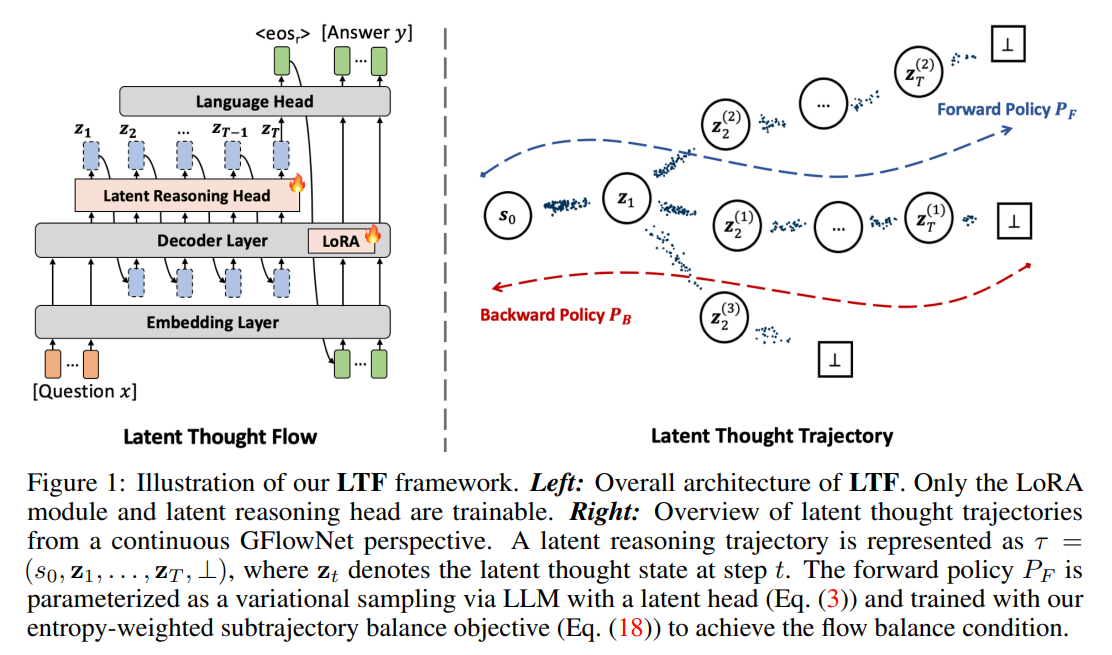
The query is processed by the embedding layer to yield the base context s0=hx. At each step t, the trainable three-layer MLP latent head generates parameters μφ(st) and σφ(st) to define the transition density. The continuous latent thought vector zt+1 is sampled utilizing the reparameterization trick zt+1=μφ(st)+σφ(st)⊙ϵ, where ϵ∼N(0,I), ensuring that gradients from the downstream loss can flow back through the stochastic latent transitions. This continuous propagation loops until the stopping probability π⊥(st) triggers the stopping decision ⊥, indicating that the model has completed its silent deliberation. The language head then decodes the final, human-readable answer y conditioned on the accumulated latent trajectory. During training, the trajectory is scored by a terminal reward Rx,y(τ)=Vx,y(τ)exp(−λcC(τ)), where the quality score is instantiated as Vx,y(τ)=Ver(y,ŷτ)+exp(1/∣y∣ logpψ(y∣x,τ)), with Ver being a task-specific verifier, ŷτ denoting the decoded response, C(τ)=T representing the step-based cost penalty, and λc controlling the weight of the penalty to favor shorter, more direct paths.
Optimization Dynamics and Prior Regularization
Training an amortized sampler over continuous high-dimensional trajectories under sparse rewards is notoriously unstable. LTF resolves this by applying a continuous Subtrajectory Balance objective, which enforces flow consistency over intermediate state prefixes. The authors formulate a joint optimization objective L=Lflow+λansLans+λpriorLprior, where λans and λprior are weighting constants. To optimize the flow, they introduce an Entropy-Weighted Subtrajectory Balance loss:
where the residual is given by:
In this equation, S represents the training rollout sample size, and ωi:j(s) is an entropy-aware weight designed to focus updates on high-entropy trajectories. For the s-th sampled trajectory, the prefix state at step i is denoted by si(s). The answer loss
handles cross-entropy objective modeling. To prevent the continuous vectors from drifting into semantically meaningless regions, the reference-prior regularization loss
anchors early exploration to teacher-generated rationales r using a piecewise-linear annealing schedule.
Training was executed on RTX PRO 6000 GPUs with an AdamW optimizer at a learning rate of 1×10−4 and LoRA adaptation of the backbone.
Quantitative Validation of the Latent Frontier
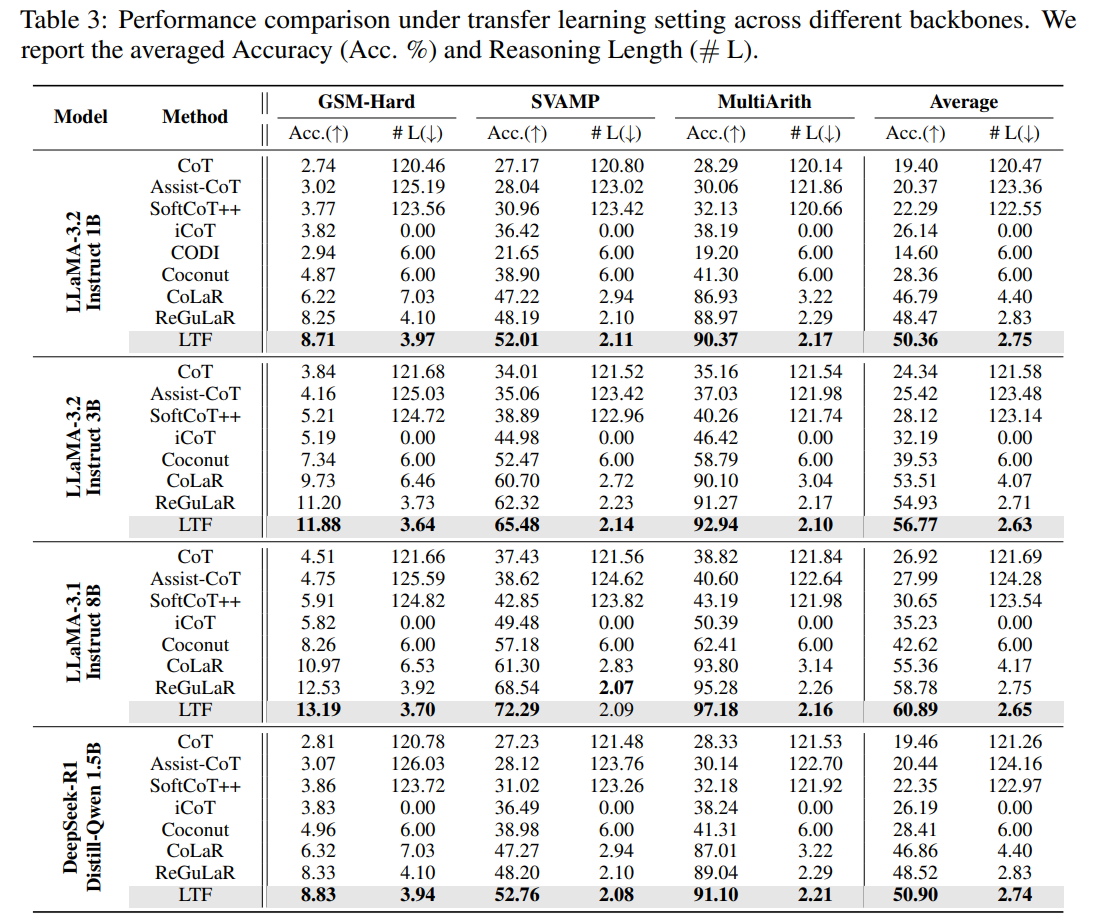
The performance of LTF was benchmarked across multiple popular open-weight backbones, including LLaMA-3.2 (1B and 3B), LLaMA-3.1 (8B), and DeepSeek-R1-Distill-Qwen-1.5B. As detailed in Table 1, LTF consistently establishes a new accuracy-efficiency frontier under fine-tuning settings. On the challenging GSM8K-Aug dataset using a LLaMA-3.2-1B backbone, LTF achieves a peak accuracy of 37.09% with a compact average reasoning length of 3.34 steps, outperforming the strong latent baseline ReGuLaR which scores 34.58% with 3.69 steps.
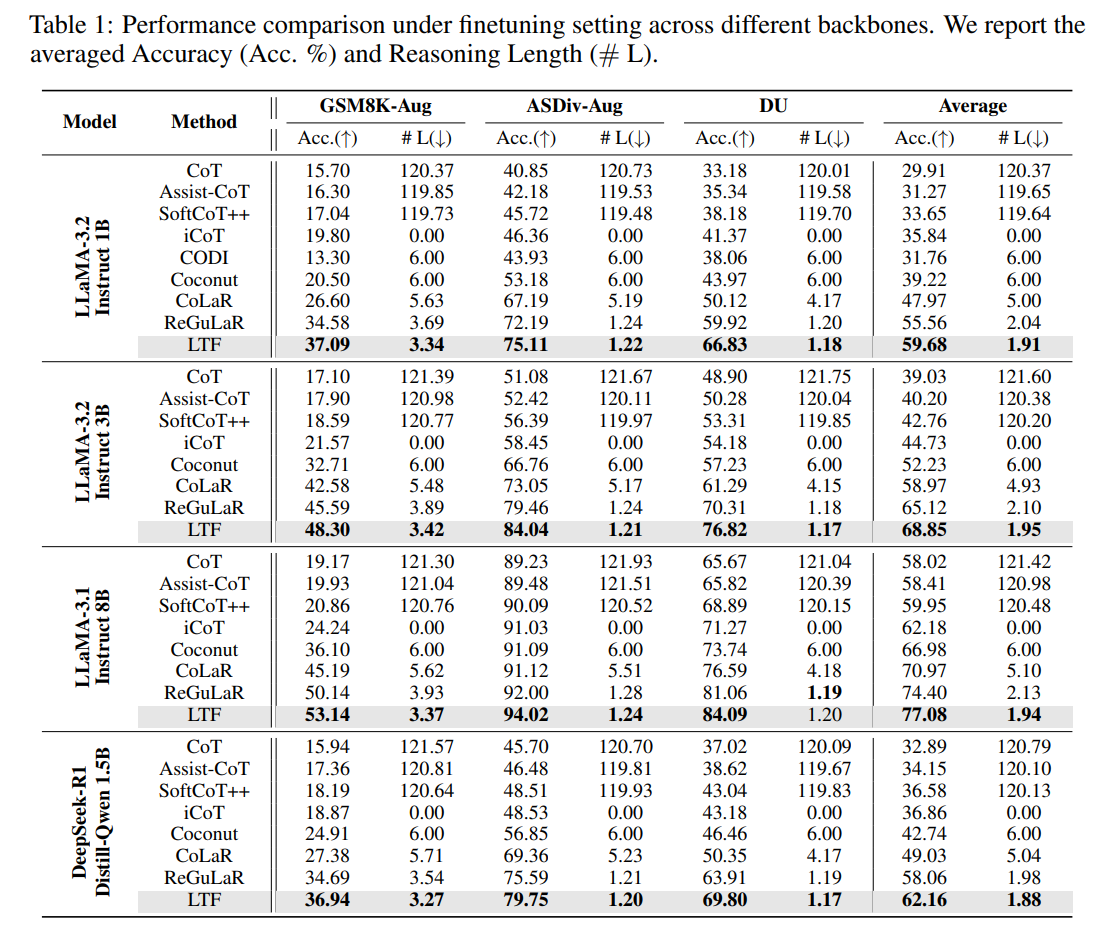
In extreme compression evaluations highlighted in Table 2, where models are forced to reason in very short sequences on MATH and AQUA-RAT, LTF maintains robust semantic integrity, outperforming baselines by substantial margins.
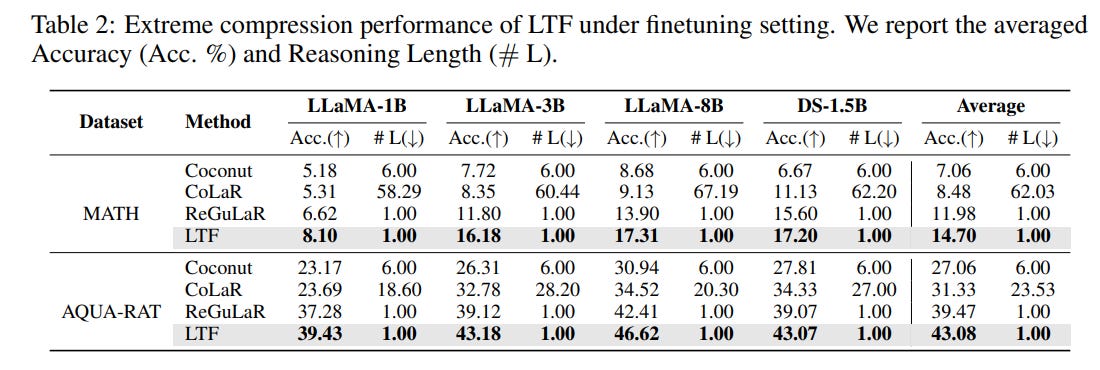
Under out-of-domain transfer learning settings on GSM-Hard, SVAMP, and MultiArith shown in Table 3, LTF showcases excellent generalization, yielding an average accuracy improvement of 6.0% and a 19.9% reduction in latent reasoning length.
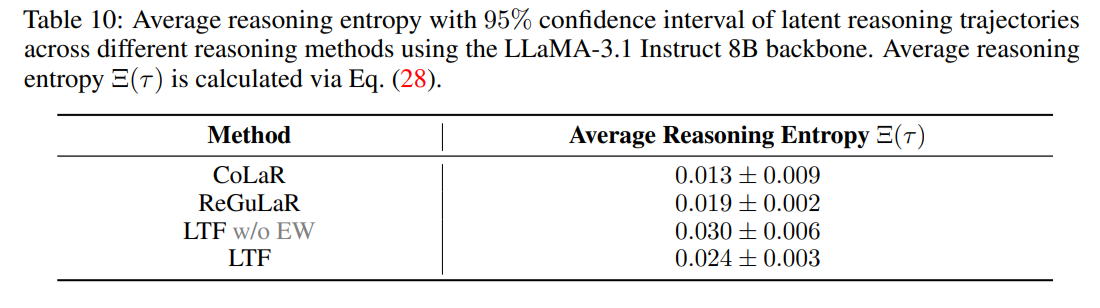
Probing the reasoning entropy of latent trajectories in Table 10 reveals that LTF maintains an optimal entropy of 0.024±0.003, striking a balance between the deterministic collapse of CoLaR and the hyper-stochastic, unstructured exploration of standard unweighted formulations.
Contextualizing Latent Thought Architectures
This work directly builds upon the evolving trajectory of internalized reasoning. Earlier approaches like iCoT attempt to gradually transition explicit tokens into hidden states, while Coconut [review] directly utilizes continuous thought representations by feeding the model’s final hidden states back into the input sequence. More advanced frameworks, such as CoLaR and ReGuLaR, seek to compress textual rationales into dynamic latent variables but remain anchored to single-path policy optimization.
LTF differentiates itself from these predecessors by establishing a distributional perspective. Rather than relying on reinforcement learning schemes like GRPO which frequently trigger mode collapse, LTF’s use of continuous GFlowNets [review] ensures a mathematically grounded, diverse exploration of the latent manifold. This probabilistic, continuous trajectory-based approach shares a deep conceptual affinity with Generative Recursive Reasoning (GRAM) [review], which also employs stochastic Gaussian latent updates and parallel test-time path sampling with adaptive halting. However, while GRAM is formulated as an amortized variational inference framework over looped Transformers designed to escape deterministic local minima in structured constraint-satisfaction tasks, LTF utilizes continuous GFlowNets to train pre-trained autoregressive LLMs, specifically targeting the linguistic bottleneck of natural language reasoning.
Current Constraints and Future Frontiers
Despite its strong empirical performance, the current iteration of Latent Thought Flow possesses distinct limitations. The experimental evaluation is strictly confined to textual tasks involving symbolic logic and mathematics, leaving its capability in multi-modal environments untested. Furthermore, modeling continuous latent thoughts as simple diagonal Gaussian distributions represents a simplified assumption that may not fully capture the complex, non-Gaussian topological manifold of actual LLM hidden states. Additionally, moving the entire deliberation process into continuous latent states inherently sacrifices the natural language interpretability of traditional Chain-of-Thought reasoning, making the detection and diagnosis of reasoning errors considerably more challenging.

Strategic Recommendations and Conclusion
Latent Thought Flow represents a significant step forward in the design of efficient, internalized reasoning architectures for LLMs. By combining continuous GFlowNets with entropy-weighted subtrajectory balance, the authors demonstrate that multi-step deliberation can be effectively learned directly within continuous latent spaces. This represents a highly viable path toward scaling test-time compute internally without the massive inference latency of verbose, token-by-token explicit decoders. For research labs focused on edge deployment and resource-constrained test-time scaling, adopting continuous trajectory flow methods over standard sequence-level reinforcement learning is highly recommended. Future research should prioritize extending this continuous flow framework to multimodal tokens and investigating more sophisticated non-Gaussian transition posteriors.