
Lattice Deduction Transformers
Authors: Liam Davis, Leopold Haller, Alberto Alfarano, Mark Santolucito
Paper: https://arxiv.org/abs/2605.08605
Code: N/A
Model: N/A
TL;DR
WHAT was done? The authors introduced the Lattice Deduction Transformer, a recurrent neural network that solves complex logical puzzles by projecting its internal states onto a mathematically rigorous coordinate system called a lattice, combining deep learning with classical computer science search techniques.
WHY it matters? This approach demonstrates that specialized, 800,000-parameter networks can solve highly complex logical reasoning problems with empirical soundness, outperforming frontier large language models (such as Claude 4.6 and GPT-5.4, which score 0%) at a fraction of the training cost.

Details
The Fragility of Scale in Pure Deduction
In the current landscape of artificial intelligence, reasoning is often treated as a byproduct of scale. Large language models are prompted to generate sequential chains of thought, working under the assumption that if a model is large enough and has read enough text, it can write its way through any logical obstacle. Yet, when confronted with dense, highly structured constraint satisfaction problems—like extreme Sudoku or complex mazes—this narrative begins to fray. A single incorrect token early in a text chain can cascade into a hallucinated, self-contradictory mess. Standard autoregressive models—which predict each subsequent word or token based solely on the sequence that came before—lack the architectural capacity to systematically backtrack and explore alternative paths.
The computational limitation of this design is striking. When evaluated on highly difficult reasoning benchmarks, giant frontier models like Claude 4.6, DeepSeek V4-Pro, and GPT-5.4 fail completely, scoring exactly zero percent. To solve these problems efficiently, a system must do more than predict the most plausible next word; it must perform sound deduction, systematically pruning what is mathematically impossible. While researchers have attempted to build smaller, recurrent neural network reasoners, such as the Tiny Recursive Model [review] and the Hierarchical Reasoning Model [review], these systems typically pass opaque, continuous latent states—the internal mathematical representations of the network’s knowledge—from one step to the next. This lack of structural transparency makes it incredibly difficult to integrate systematic, symbolic search procedures like backtracking directly into the machine learning loop.
Mapping Ignorance and Certainty on a Lattice
The core innovation of the Lattice Deduction Transformer lies in its integration of a classical computer science framework known as abstract interpretation. To understand this, imagine trying to solve a Sudoku puzzle. Before you write down any numbers, every cell on the grid could theoretically hold any digit from one to nine. In the language of lattice theory, this state of complete uncertainty represents the “top” of our lattice—a state of maximum ignorance. As you apply the rules of the game, you eliminate possibilities. If you deduce that a specific cell can only contain a three, a five, or a nine, you have descended to a lower, more precise point in the lattice. If every cell is narrowed down to a single, correct digit, you have reached a concrete solution. If, however, your deductions lead to a contradiction where a cell has zero remaining possibilities, you have hit “bottom,” signifying an impossible, inconsistent state.
This hierarchy of partial information is a bounded mathematical lattice. The authors’ crucial realization was that a transformer’s latent state could be projected directly onto this lattice structure between its execution passes. This mathematical bridge, formally known as a Galois connection, guarantees soundness. A deduction step performed by the network might be incomplete—meaning it fails to find the final answer immediately—but it is guaranteed to be sound, meaning it will never eliminate a valid candidate or assert a falsehood. By mapping the continuous activations of a neural network to this discrete coordinate system of possibilities, the model’s internal reasoning becomes both interpretable and easily steerable by symbolic search algorithms.
A Walk through the Lattice Solve Loop
To understand how this operates in practice, consider a single complex puzzle passing through the system, as illustrated by the structural schematic in Figure 1 and the tensor encoding in Figure 2.
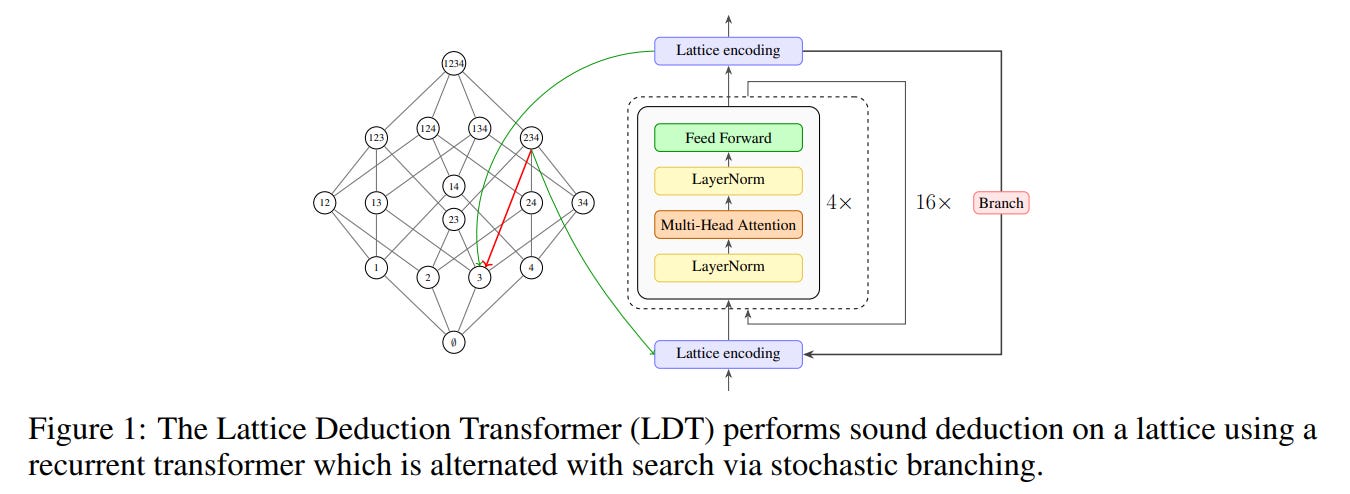
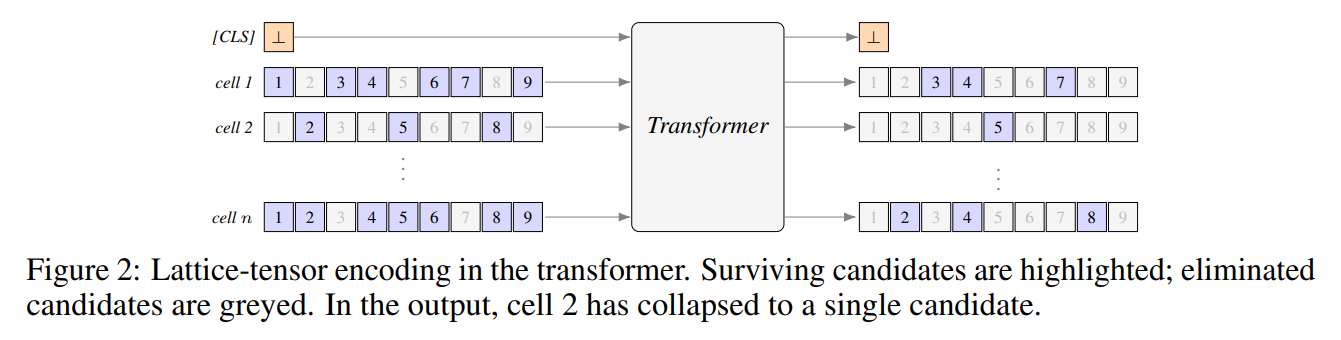
The puzzle’s current state is represented as a grid of probabilities, where each cell has a set of active binary signals indicating which digits are still considered viable. This multi-hot tensor—which we can think of as a grid of digital flags indicating active candidates—is injected into a recurrent transformer consisting of a stack of four attention layers. The network unrolls this representation internally for sixteen iterations, re-injecting the initial grid state at each step to maintain a strong residual signal.
Upon completing these internal loops, the model outputs updated confidences for each candidate value along with a conflict signal generated by a specialized classification token. The system then applies a deterministic pruning step, completely eliminating any candidates whose confidence falls below a set threshold. If the board is solved, the process terminates. If a conflict is flagged or a cell collapses to zero candidates, the solver backtracks. If the board is still unfinished but consistent, the system executes a branching step: it randomly selects a cell with multiple active candidates, samples a single digit based on the model’s confidence, pins that digit as a certainty, and feeds the updated state back into the transformer.


To train this system without suffering from distribution shift—the phenomenon where a model encounters scenarios during testing that differ from its training data—the authors utilize an on-policy solve loop during training. The model learns from the actual, partially solved states it encounters during its own search trials. Crucially, the training target is computed using a state-dependent algorithm called the alpha operator. Rather than penalizing the network for making choices that differ from a single pre-selected ground truth, the alpha operator determines every mathematically valid solution that can still be reached from the model’s current state. This relationship is governed by the core target update rule:
ŷ=x⊓α(Yconsistent)
In this formulation, the target state represented by the symbol on the left is computed by taking the current state (the first variable on the right) and using a mathematical intersection operator (the inverted-U symbol) to combine it with the abstracted representation of all remaining consistent, valid solutions. This target provides a strong, step-by-step training signal that naturally handles puzzles with multiple valid paths, such as complex mazes.
David Defeats Goliath on the Extreme Grid
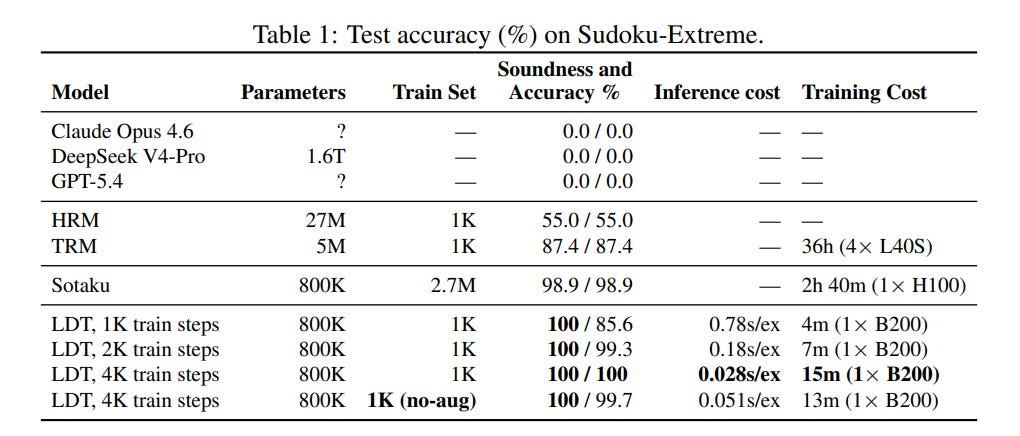
The experimental results validate this structured approach. On the Sudoku-Extreme benchmark—a collection of puzzles carefully filtered using the Tdoku solver to ensure they cannot be solved by simple heuristics and require deep backtracking—the Lattice Deduction Transformer achieved a perfect 100% accuracy and 100% empirical soundness, as detailed in Table 1. An 800,000-parameter variant of the model reached this level after just 4,000 training steps, requiring only 15 minutes of compute on a single B200 GPU. In comparison, the Tiny Recursive Model achieved 87.4% accuracy after 36 hours of training across four GPUs, and the giant frontier models failed to solve a single instance.
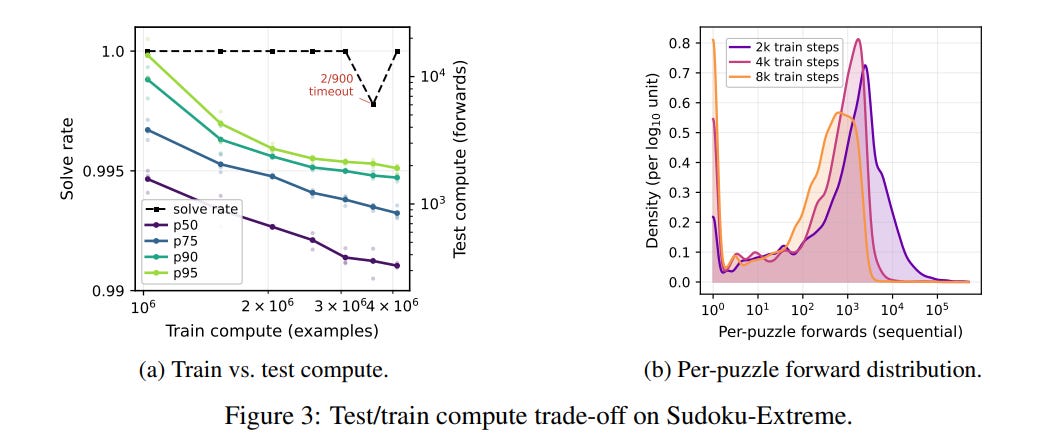
This high sample efficiency is closely linked to a fascinating train-to-test compute trade-off shown in Figure 3a. As the model receives more training steps, the average number of forward passes required to solve a puzzle during inference drops by an order of magnitude. The underlying distribution of solve times, plotted in Figure 3b, reveals a bimodal shift. With minimal training, the model must frequently guess and backtrack (the search mode). With extended training, the model shifts toward direct, deterministic logical deduction, completing the puzzles in a single sequence of steps without ever needing to branch.
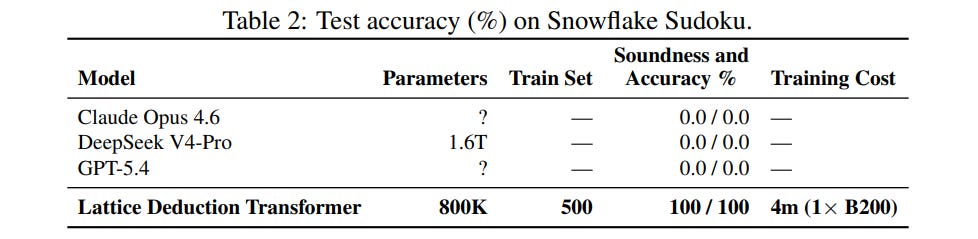
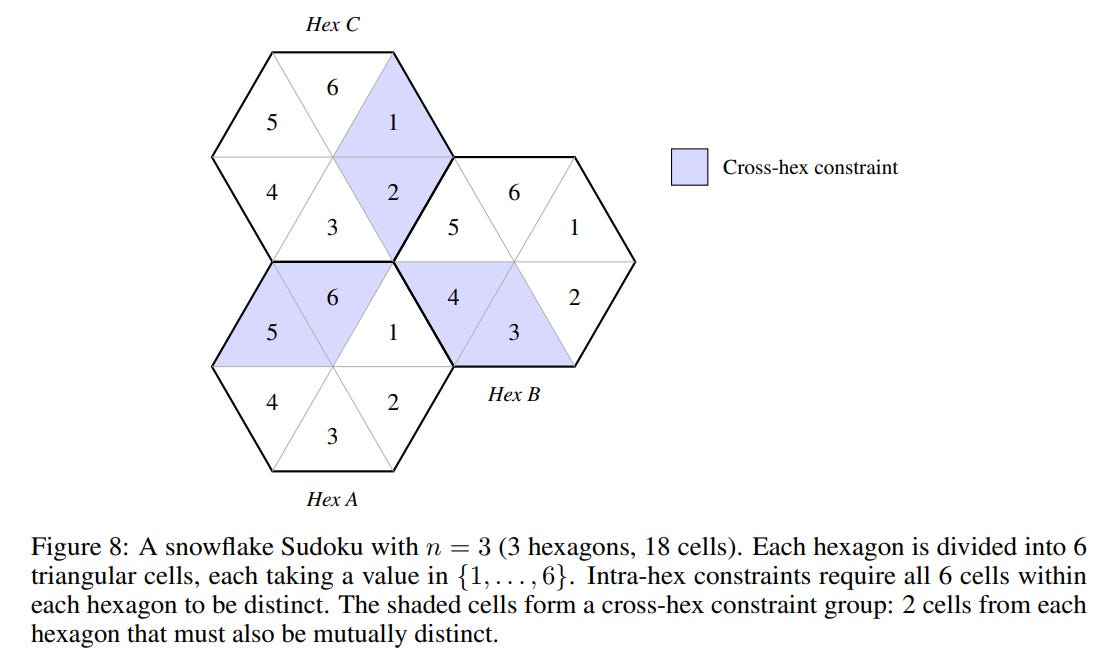
This capability extends beyond standard grids. On Snowflake Sudoku, a hexagonal variant with variable sizes and complex constraints shown in Figure 8, the model achieved 100% accuracy after only four minutes of training (Table 2).
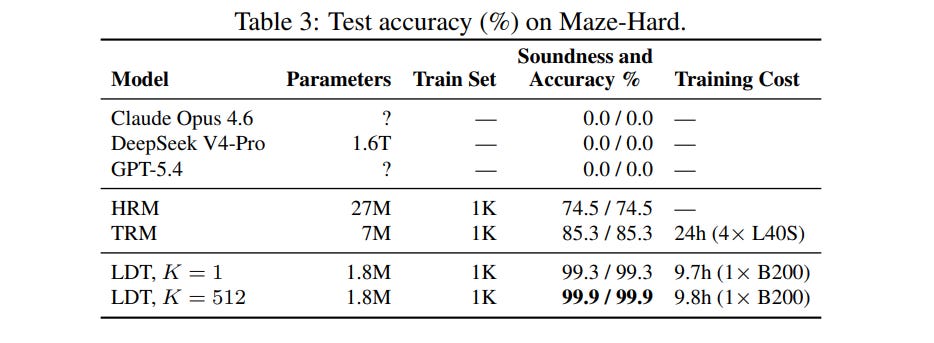
On Maze-Hard—a benchmark consisting of thirty-by-thirty mazes where a single instance can have millions of viable paths—a 1.8-million-parameter version utilizing the multi-solution target reached 99.9% accuracy, as shown in Table 3.
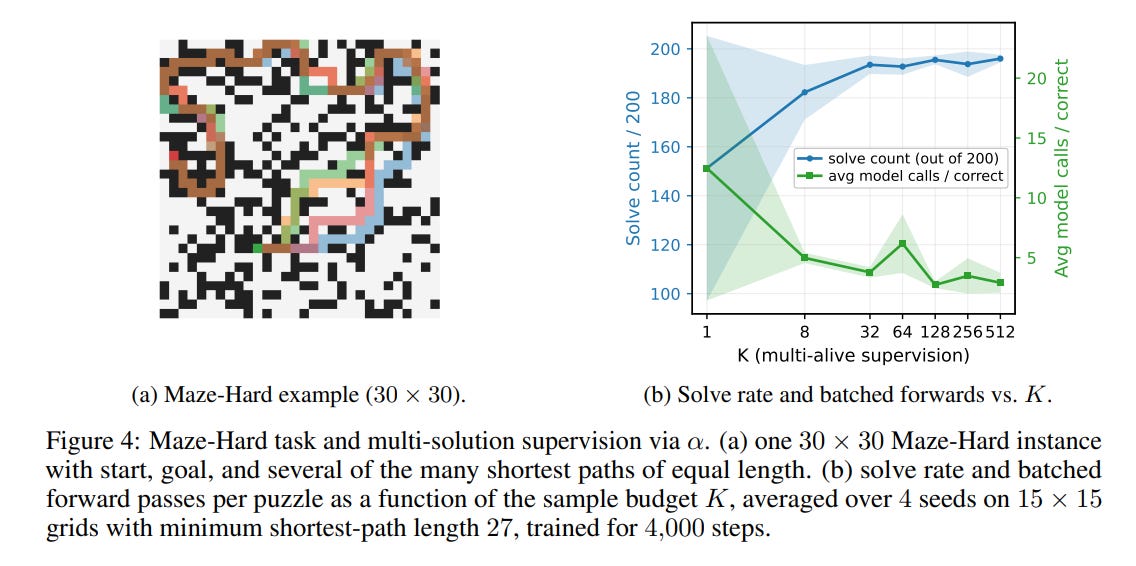
When the multi-solution target was restricted to a single path, performance dropped significantly (Figure 4b), proving the value of the alpha operator’s flexible supervision.
Bridging Neuro-Symbolic Gaps and Discrete Diffusion
From a broader perspective, this work redefines the boundary between neural networks and symbolic constraint solvers. Traditional neuro-symbolic methods, such as SATNet or Learning Modulo Theories, typically isolate the deep learning component from the solver, treating the logical solver as a distinct, differentiable layer. The Lattice Deduction Transformer breaks down this barrier by embedding the symbolic lattice state directly within the recurrent loop of the transformer itself.
This formulation also shares a deep mathematical connection with discrete diffusion models like D3PM. In discrete diffusion, a network gradually unmasks a sequence of tokens to generate text or images. The authors recast this process as a fixed-point calculation descending a partial-information lattice. This insight provides a unifying bridge, showing how generative, diffusion-style models can be formalized and paired with exact, backtrackable symbolic search mechanics without losing their neural representation.
Where the Rules Fade, the Method Falters
Despite its strengths, the system’s reliance on structured mathematics reveals its primary limitation. The Lattice Deduction Transformer requires a pre-defined abstract lattice and a known, sound deduction operator. In other words, you must understand and mathematically define the rules of the environment beforehand to construct the coordinate system.
On benchmarks like the Abstraction and Reasoning Corpus (On the Measure of Intelligence), where the rules are not known in advance and must be inferred from a small handful of visual examples, a direct implementation of this method plateaus at a modest 36% pass rate. In this unstructured regime, the conflict-detection head becomes unreliable, causing the search loop to make incorrect branching decisions. Furthermore, on the Maze-Hard task, the model is not entirely sound; unsolved instances occasionally output slightly suboptimal paths rather than gracefully abstaining, indicating that the system’s absolute soundness guarantees are highly dependent on the strictness of the underlying logical rules.
A Blueprint for Rigorous Neural Reasoners
The success of the Lattice Deduction Transformer challenges the dominant paradigm that logical reasoning is merely an emergent property of massive scale. By demonstrating that a highly specialized, sub-million parameter network can outperform trillion-parameter giants on difficult reasoning tasks, this work provides a compelling case for neuro-symbolic architectures.
Structuring the latent space of deep neural networks using classical mathematical concepts like lattices and Galois connections offers a viable alternative to the unconstrained generation of text chains. This methodology provides a practical blueprint for building highly efficient, verifiable, and hallucination-free models. Such systems are highly desirable in critical, rule-bound domains where errors are unacceptable, including automated software verification, silicon chip design, and scientific theorem proving.
