
Learning to Forget: Continual Learning with Adaptive Weight Decay
Authors: Aditya A. Ramesh, Alex Lewandowski, Jürgen Schmidhuber
Paper: https://arxiv.org/abs/2604.27063v1
Code: https://github.com/Aditya-Ramesh-10/Fade
Model: N/A
TL;DR
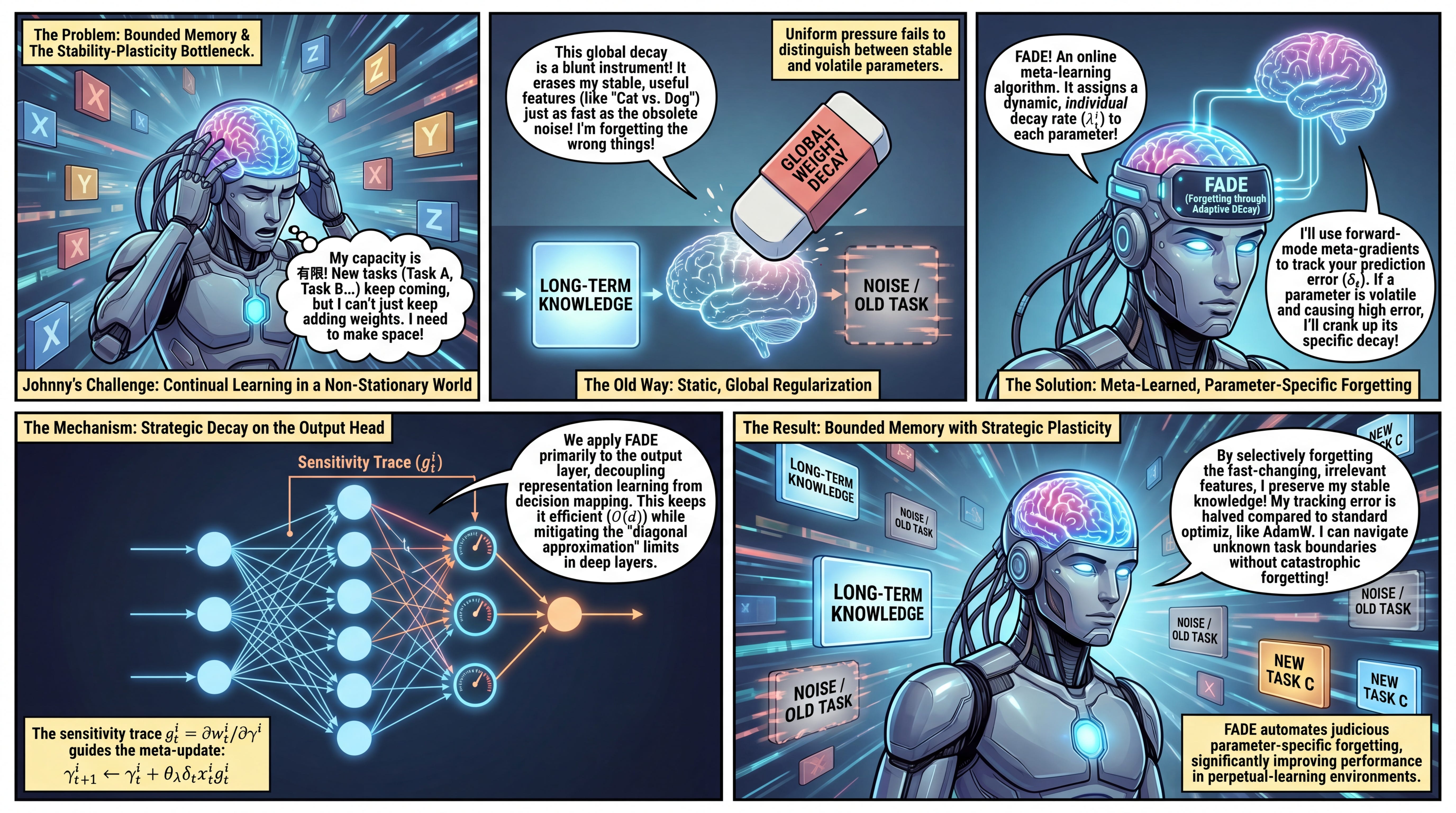
WHAT was done? The authors introduce Forgetting through Adaptive DEcay (FADE), an online, meta-learning algorithm that assigns dynamic, per-parameter weight decay rates to a network’s parameters. Using forward-mode meta-gradient descent, FADE selectively modulates how quickly individual weights forget their past states based on prediction error.
WHY it matters? In continual learning scenarios with non-stationary data streams and finite model capacity, a network must navigate the stability-plasticity trade-off. Standard scalar weight decay acts as a global regularizer, erasing both stale mapping and stable knowledge uniformly. FADE resolves this by automating judicious parameter-specific forgetting, significantly improving performance and mitigating the loss of plasticity without increasing architectural complexity.
Executive summary: For technical leaders and AI strategists, this paper provides a highly efficient, O(d) method to automate parameter-specific forgetting in neural networks. By shifting weight decay from a static regularization penalty to a dynamic mechanism, the algorithm effectively halves the tracking error compared to standard optimizers like AdamW. This capability is foundational for deploying bounded-capacity agents into perpetual-learning environments where task boundaries are unknown and data is entirely non-stationary.
Details
The Stability-Plasticity Bottleneck in Continual Learning
A fundamental constraint in online continual learning is finite capacity. When task boundaries are unknown and data arrives one sample at a time, a learning agent cannot indiscriminately accumulate information. It must overwrite outdated mappings to free up capacity for new incoming signals. Traditionally, researchers employ fixed Weight Decay as a global regularizer to slowly pull parameters toward zero, or techniques like Weight Clipping to bound parameter growth. However, applying a single, static decay scalar across an entire network presents a severe structural mismatch. Parameters encoding stable, long-term knowledge are forced to decay at the exact same rate as parameters tracking rapidly shifting environment targets. This uniform pressure either prevents the model from retaining useful historical features or slows down its ability to adapt to fast-changing distributions.
Meta-Learned Forgetting: The FADE Substrate
To address this uniform forgetting problem, the paper shifts the paradigm of weight decay from a simple regularization penalty to a localized, learned forgetting mechanism. The core theoretical substrate is to parameterize the decay rate individually for each weight and adapt it dynamically using meta-gradients. Specifically, the proposed algorithm, FADE, assumes that the ideal retention horizon for any given parameter should be inversely proportional to the volatility of the function it approximates. Rather than relying on heuristics or gradient norms, FADE treats the decay parameter itself as an optimizable variable, updated online via forward-mode differentiation to directly minimize the model’s predictive error.
The Meta-Gradient Mechanism
The execution of FADE relies on maintaining an auxiliary sensitivity trace to compute the meta-gradients online. To understand the mechanism, consider a model receiving an input feature vector xt∈Rd and a target scalar yt∗ at time step t. The model produces a prediction yt=⟨wt,xt⟩ using its weights wt∈Rd, resulting in a prediction error δt=yt∗−yt. The base objective is to minimize the loss function Jt=δt2/2.
FADE introduces a meta-parameter γti∈Rd that defines the specific decay rate for the i-th parameter as λit+1←exp(γit+1). Because the impact of the decay rate on the loss is mediated through the history of the weight updates, the system maintains a sensitivity trace git=∂wit/∂γi to track this temporal dependency.
During a single forward pass, FADE updates the meta-parameter using the gradient of the loss with respect to γi, modulated by a meta-step size θλ: γit+1←γit+θλδtxitgit
Following the γi update, the sensitivity trace gi is updated to reflect the new state. This update includes a positive-bounding operation [⋅]+ (defined as max(⋅,0)) to ensure stability, incorporating the base learning rate α: git+1←git[1−λit+1−α(xit)2]+−λit+1wit
Finally, the base weight undergoes its delta-rule update, factoring in the newly adapted decay rate: wit+1←(1−λit+1)wit+αδtxit
By decoupling the meta-gradient step from the underlying optimizer, the model effectively performs online cross-validation: the network makes an update, and its performance on the next sequential sample provides the gradient signal to adjust how much it should forget.

Execution Strategy in Deep Networks
While FADE is mathematically derived for online linear regression, the authors provide a highly effective strategy for scaling it to deep neural networks: applying adaptive decay exclusively to the final output layer (the network head). In a standard Multi-Layer Perceptron (MLP) architecture, the intermediate hidden layers construct a feature representation, while the final layer acts as a linear classifier mapping those features to the target labels. By applying FADE to the final linear layer and utilizing standard optimizers like SGD or Adam for the hidden layers, the network isolates representation learning from decision mapping. This targeted application preserves the theoretical rigor of the linear meta-gradient derivation while minimizing computational overhead to a strictly O(d) addition per step.
Analyzing the Source of Performance
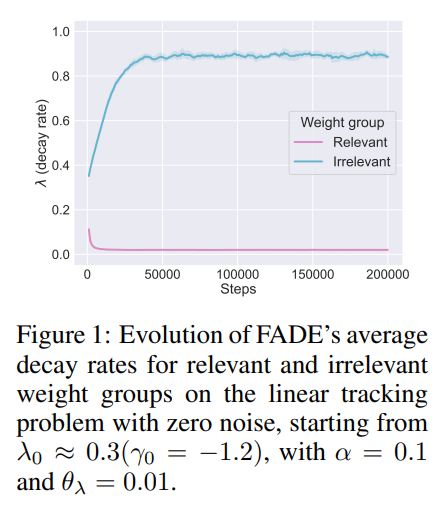
The empirical validation demonstrates that FADE successfully isolates distinct temporal scales. On a linear tracking problem where certain features are relevant and others randomly flip signs, Figure 1 confirms that FADE automatically drives the decay rate of irrelevant features to λ≈0.9 (rapid forgetting) while settling relevant features near λ≈0.02 (long-term retention).
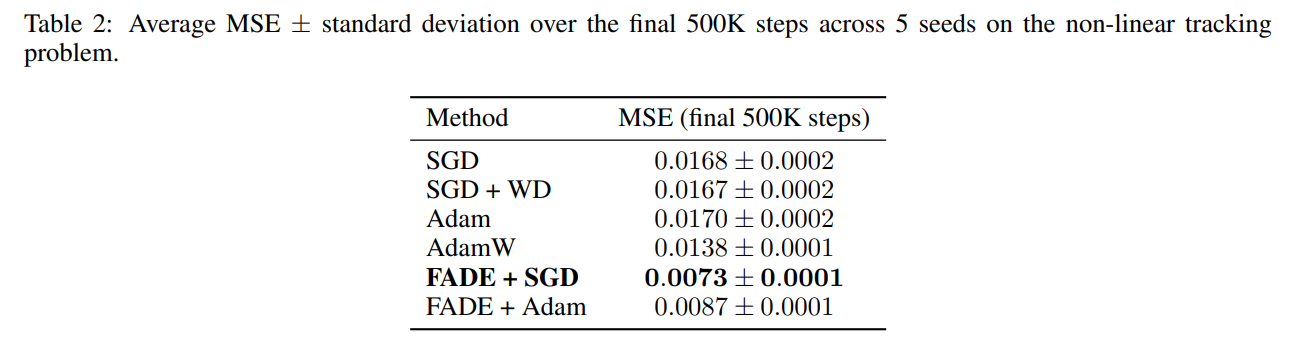
This behavioral distinction yields substantial performance gains. In a non-linear teacher-student tracking task containing stable, slow-changing, and fast-changing output units, FADE paired with SGD achieves a Mean Squared Error (MSE) of 0.0073±0.0001. As detailed in Table 2, this effectively halves the error of the highly popular AdamW optimizer, which plateaus at 0.0138±0.0001.
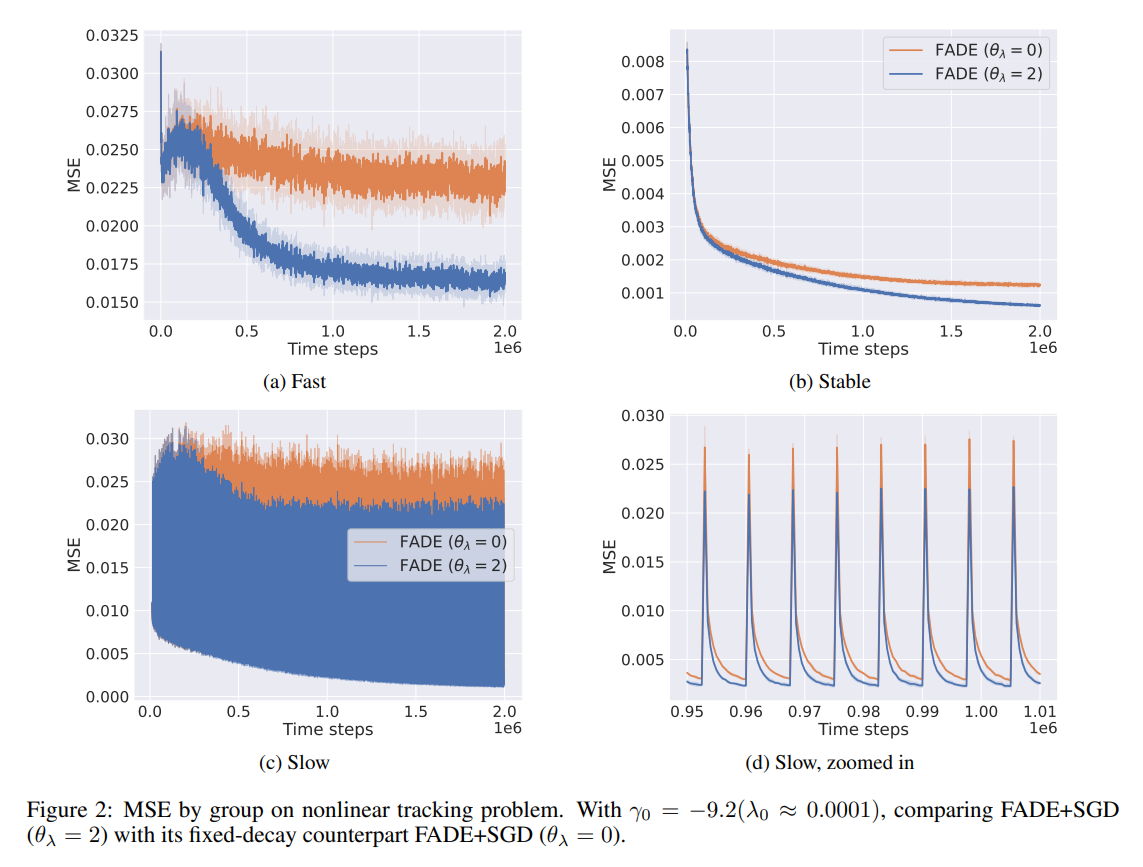
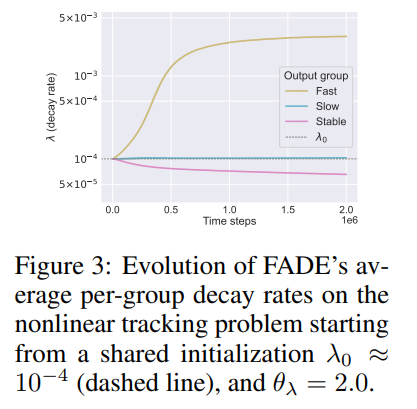
The source of this accuracy is explicitly visualized in Figure 2 and Figure 3, which plot the internal state of the system over time: FADE pushes decay rates upward precisely for the fast-changing output targets and pulls them downward for the stable outputs, thereby matching the environmental non-stationarity perfectly.
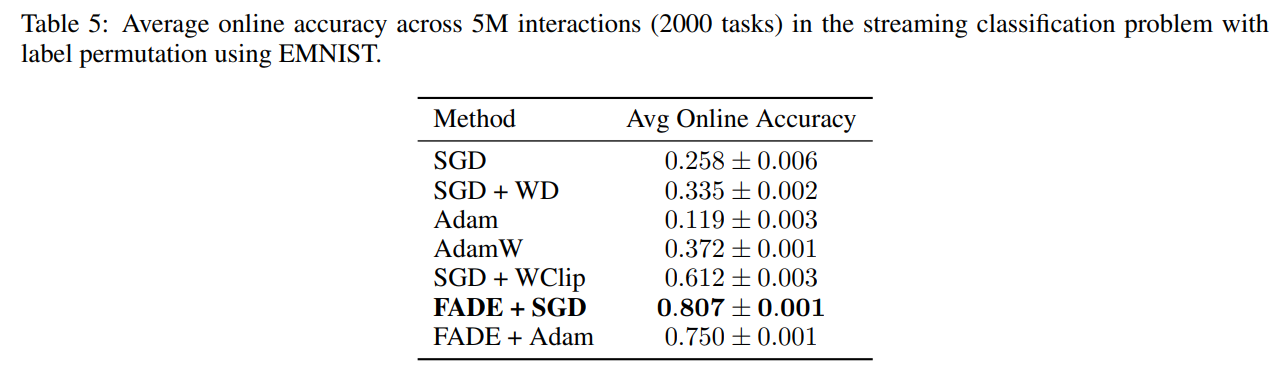
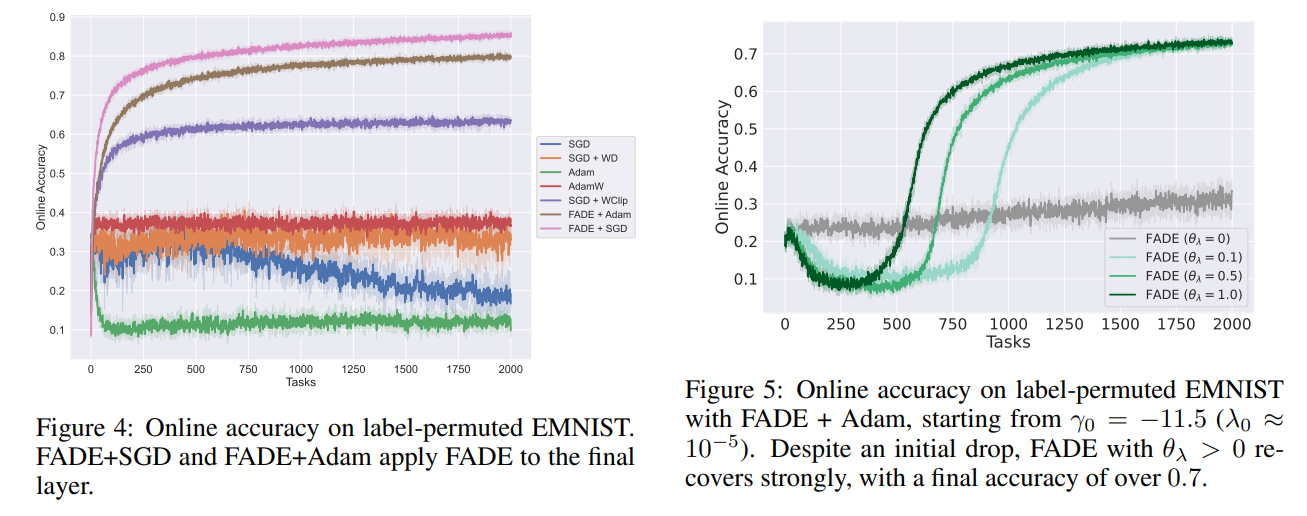
The capacity benefits hold for larger scale streaming classification as well. Evaluating on a label-permuted EMNIST task, where classes are randomly shuffled every 2,500 steps, FADE with SGD attains an average online accuracy of 0.807±0.001, decisively outperforming the previous state-of-the-art SGD + Weight Clipping (0.612±0.003), as summarized in Table 5.
Furthermore, the adaptivity ensures robustness to poor initializations; Figure 5 illustrates a scenario where the system starts with a near-zero initial decay (λ0≈10−5) and quickly recovers to over 0.7 accuracy, while a fixed-decay baseline completely stalls.
Lineage and Competing Approaches
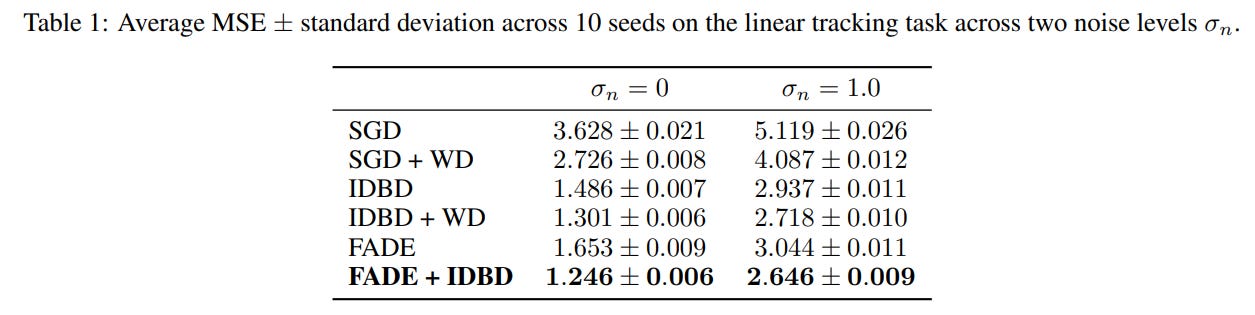
The meta-gradient derivation of FADE is closely related to the classic IDBD (Incremental Delta-Bar-Delta) algorithm, which adapts per-parameter step sizes rather than weight decay. FADE and IDBD solve orthogonal problems—how fast to learn versus how much to forget. Consequently, they are highly complementary. As shown in Table 1 on the linear tracking task, combining FADE and IDBD yields the lowest overall MSE (1.246±0.006), outperforming either method deployed independently. FADE also distances itself from approaches that dynamically scale weight decay based on gradient norms, as those heuristic methods are largely designed to aid generalization in stationary mini-batch training rather than driving localized forgetting in continuous streams.
Theoretical Bounds and Approximation Limits
The primary limitation of FADE emerges from its core architectural assumption: the “diagonal approximation”. The forward-mode differentiation assumes that changing a meta-parameter γi only influences its corresponding weight wi, with negligible cascading effects on the rest of the network. While perfectly valid for a linear output head, this assumption breaks down when extending FADE natively to deep hidden layers, where non-linear activation dependencies cause severe interference. The authors report that a naive full-network extension of FADE plateaus significantly below the head-only variant and suffers from initialization sensitivity. Furthermore, when combining FADE with momentum-based optimizers like Adam, the current sensitivity trace approximation does not capture the first moment’s historical buffer, causing a slight degradation in gradient accuracy compared to the pure SGD variant.

Strategic Implications
This work forces a reevaluation of weight decay’s role in modern architectures. By demonstrating that selective, per-parameter forgetting provides a massive advantage over global regularization, FADE highlights a critical mechanism required for bounding memory in perpetual learning systems. Furthermore, the empirical finding that a fixed decay on a network’s head provides an unusually strong baseline suggests that much of “catastrophic forgetting” can be attributed to entangled decision boundaries at the output layer rather than degraded hidden representations. FADE automates this process elegantly, providing a lightweight, robust tool for agents tasked with navigating environments of unknown and shifting task boundaries.