
Learning to Rewrite Tool Descriptions for Reliable LLM-Agent Tool Use
Authors: Ruocheng Guo, Kaiwen Dong, Xiang Gao, Kamalika Das
Paper: https://arxiv.org/abs/2602.20426
Affiliation: Intuit AI Research.
TL;DR
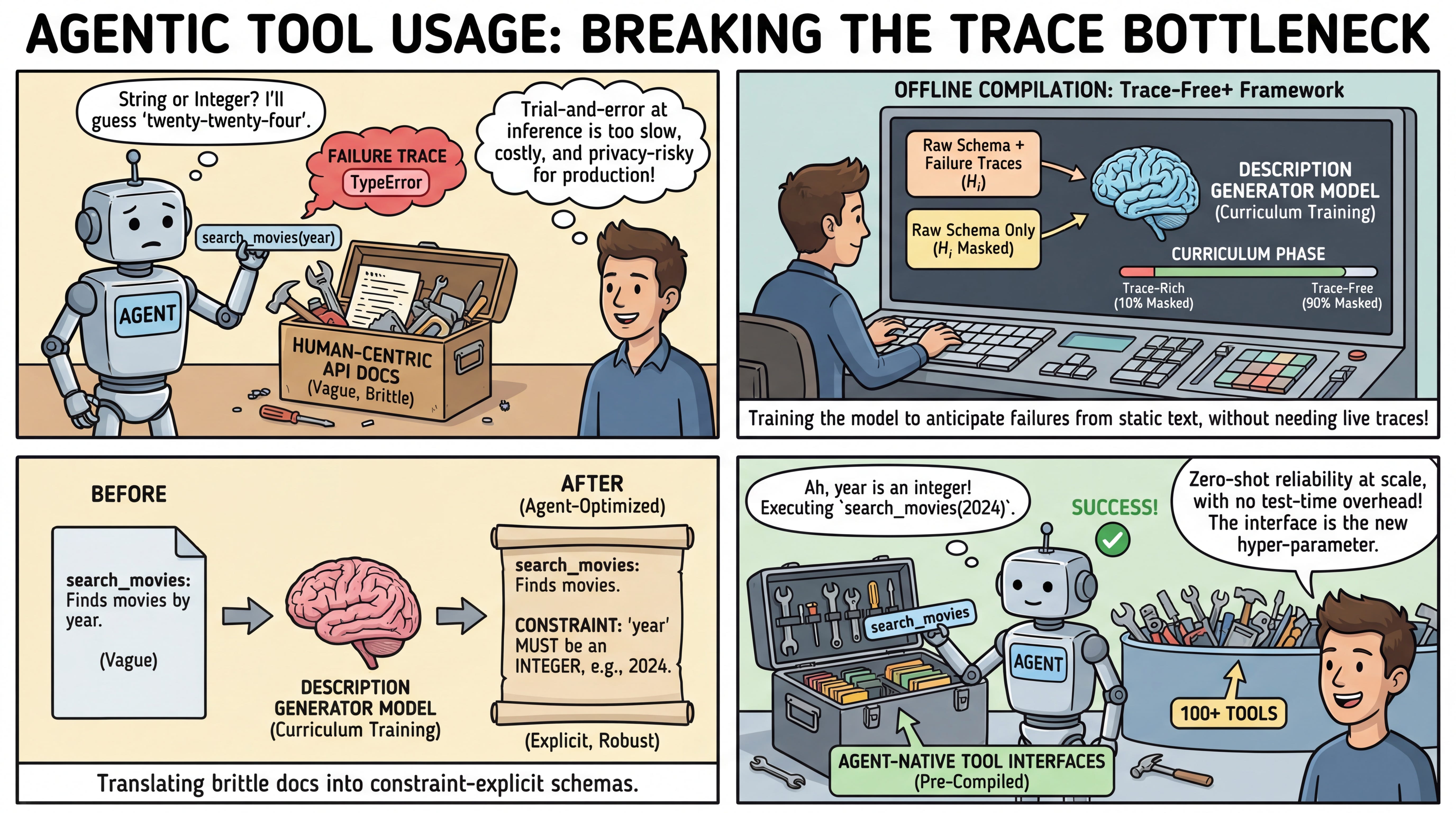
WHAT was done? The authors introduced Trace-Free+, a learning-based framework that rewrites human-centric API documentation into agent-optimized tool descriptions. By employing a curriculum learning strategy, the system fine-tunes a language model to transition from trace-rich training scenarios to trace-free inference, allowing it to generate high-quality descriptions for completely unseen tools without requiring live execution traces at test time.
WHY it matters? Relying on trial-and-error execution traces during inference is often infeasible in cold-start deployments or privacy-constrained environments. By shifting the optimization burden entirely to an offline compilation step, this method drastically reduces inference costs, preserves data privacy, and scales robustly even when an agent must select from candidate pools exceeding 100 tools.
Executive summary: For practitioners building compound AI systems and tool-using agents, the quality of the environment—specifically the tool interfaces—is just as critical as the reasoning capabilities of the agent itself. This paper demonstrates that we can systematically translate brittle, human-written API documentation into robust, constraint-explicit schemas without incurring the overhead of test-time exploration. This points to a highly deployable paradigm where API ecosystems can be pre-compiled into agent-native formats.
Details
The Trace Dependency Bottleneck
As the context windows of large language models expand, agents are increasingly exposed to massive toolsets. However, the interfaces bridging agents and external tools remain largely human-oriented. Vague descriptions and incomplete parameter schemas frequently lead to hallucinated arguments and systemic execution failures. Previous attempts to optimize these interfaces rely heavily on collecting runtime execution traces. While observing an agent fail provides excellent feedback for refining tool instructions, deploying trace-dependent mechanisms at inference time introduces a severe bottleneck. Live trial-and-error interactions are costly, slow, and structurally impossible in strict zero-shot, privacy-critical, or cold-start scenarios where new APIs are introduced without historical usage data. The core delta of the proposed framework is the elimination of this test-time dependency, leveraging offline simulated traces strictly as a supervisory signal to train a robust description generator.
