
LLMs Improving LLMs: Agentic Discovery for Test-Time Scaling
Authors: Tong Zheng, Haolin Liu, Chengsong Huang, Huiwen Bao, Sheng Zhang, Rui Liu, Runpeng Dai, Ruibo Chen, Chenxi Liu, Tianyi Xiong, Xidong Wu, Hongming Zhang, Heng Huang
Paper: https://arxiv.org/abs/2605.08083
Code: https://github.com/zhengkid/AutoTTS
Model: N/A
TL;DR
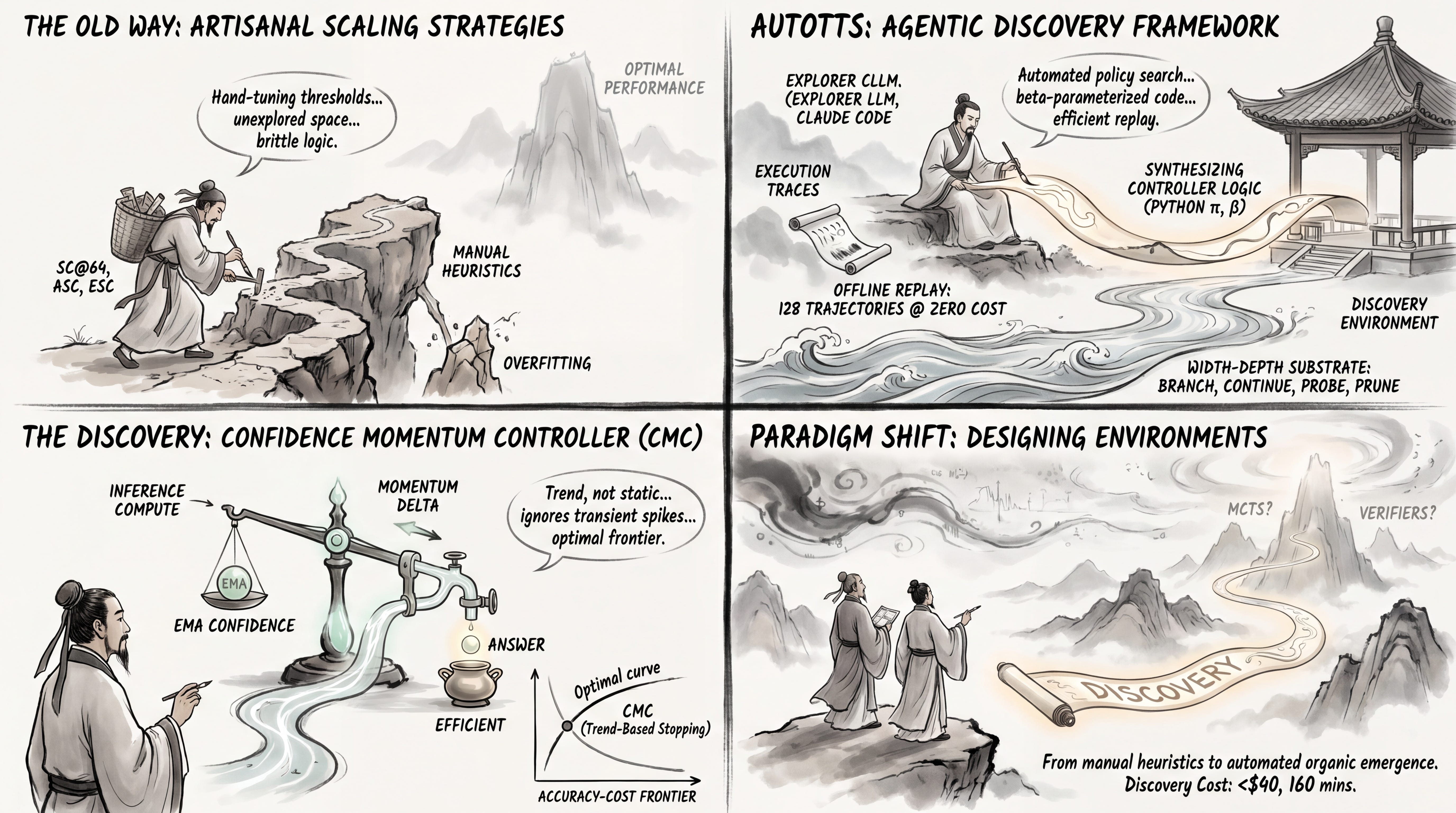
WHAT was done? A consortium of researchers (spanning UMD, UVA, Google, Meta, and others) introduced AutoTTS, an environment-driven framework that uses an explorer LLM to automatically synthesize and discover test-time scaling (TTS) algorithms. By formulating inference compute allocation as a policy search within an offline replay environment, the system autonomously designs reasoning controllers that dictate when a language model should branch, probe, prune, or terminate.
WHY it matters? Test-time scaling is currently dominated by manually engineered heuristics (e.g., self-consistency, early stopping). AutoTTS demonstrates a paradigm shift where researchers construct discovery environments rather than hand-crafting algorithms. The resulting AI-discovered strategy, the Confidence Momentum Controller, achieves superior accuracy-cost Pareto frontiers, reducing inference token usage by nearly 70% compared to standard self-consistency, all for a total discovery compute cost of just under $40.
Details
The Hand-Crafted Heuristics Bottleneck
Test-time scaling (TTS) has proven to be an indispensable lever for extracting latent reasoning capabilities from language models. However, the prevailing methodology for designing these inference allocation strategies is largely artisanal. Researchers rely on intuition to define when an LLM should explore multiple reasoning paths and when it should stop. Strategies like Self-Consistency (SC@64) uniformly expand the search width, while adaptive methods such as ASC, ESC, and Parallel-Probe introduce manually tuned stopping and pruning thresholds. The central bottleneck in the field is that this manual approach leaves the vast majority of the computation-allocation space unexplored, often resulting in brittle heuristics that overfit to specific reasoning benchmarks.
AutoTTS reframes this problem by shifting the human burden from strategy design to environment design. Instead of engineering individual branching logic, the authors define a rigid control space where an automated agent can search for the optimal policy. The core premise is that if we provide a capable LLM with a programmatic interface to manage reasoning branches, it can synthesize controller logic that coordinates width and depth more effectively than human intuition.
