
MatFormer: One Transformer to Flexibly Serve All Deployment Needs
MatFormer: Nested Transformer for Elastic Inference
Authors: Devvrit, Sneha Kudugunta, Aditya Kusupati, Tim Dettmers, Kaifeng Chen, Inderjit Dhillon, Yulia Tsvetkov, Hannaneh Hajishirzi, Sham Kakade, Ali Farhadi, Prateek Jain
Paper: https://arxiv.org/abs/2310.07707
Code: https://github.com/devvrit/matformer
It’s not always the new papers that matter — there are many interesting older papers you may have missed in the past. We will occasionally post such older paper reviews here, likely once a week. Today’s topic is MatFormer, or 🪆 Matryoshka Transformer, the model behind the recently announced Gemma 3n full release.
TL;DR
WHAT was done? The authors introduce MatFormer, a novel Transformer architecture designed for "elastic inference." By incorporating a nested, "matryoshka doll-style" structure within the Feed-Forward Network (FFN) blocks, MatFormer enables the training of a single, universal model. From this one model, hundreds of smaller, accurate submodels can be extracted at inference time without any additional training or fine-tuning. A simple and efficient heuristic, "Mix'n'Match," is also proposed to select the best submodel for a given compute budget by combining different layer sizes.
WHY it matters? This work tackles a major bottleneck in deploying large foundation models: the high cost and rigidity of being limited to a few fixed model sizes. MatFormer offers a paradigm shift from training many models to training just one, drastically reducing the amortized training cost and providing unprecedented flexibility. This allows practitioners to deploy an optimally-sized model for any latency or cost constraint, from cloud servers to edge devices. The extracted submodels not only match but often outperform their independently trained counterparts and significantly accelerate inference through techniques like speculative decoding, making powerful AI more efficient, accessible, and adaptable to real-world needs.

Details
The Problem: The High Cost of Inflexibility in Foundation Models
Foundation models have become the backbone of modern AI, but their power comes at a cost. Training these massive models is computationally expensive, which means providers typically offer only a handful of discrete sizes (e.g., Llama 2's 7B, 13B, and 70B variants (https://arxiv.org/abs/2307.09288)). This forces practitioners into a difficult compromise: either select a smaller, less accurate model to meet latency budgets or a larger, more expensive one that might be underutilized. While techniques like pruning (https://arxiv.org/abs/2109.04838) or distillation (https://arxiv.org/abs/1910.01108) exist, they often require costly, post-hoc retraining to tailor a model to a specific need. This fundamental inflexibility creates a significant barrier to deploying the right model for the right job efficiently.
MatFormer: A Natively Elastic Architecture
The paper "MatFormer: Nested Transformer for Elastic Inference" presents an elegant and powerful solution to this problem. Instead of retrofitting models for efficiency, the authors re-architect the Transformer itself to be natively elastic.

MatFormer follows the principle of matryoshka representation learning by the same subgroup of authors.

The core innovation is a nested, or "matryoshka-like," structure primarily within the Transformer’s Feed-Forward Network (FFN) block (Figure 1). This choice is strategic, as the FFN accounts for over 60% of the computation in most language and vision Transformers. In MatFormer, smaller FFN blocks are contained within larger ones. This is elegantly achieved by training the full-sized weight matrices of the FFN and then creating smaller sub-networks simply by taking a slice of those matrices (e.g., using only the first m neurons). During a single training run, the model is optimized by randomly sampling and training across these different nested sizes, or "granularities." This joint optimization allows one universal model to learn to perform well across a spectrum of capacities.

At inference time, this design unlocks remarkable flexibility. Not only can a user select one of the explicitly trained granularities, but a simple and computationally free heuristic called "Mix'n'Match" allows for combining different FFN sizes across the model's layers. This approach can generate hundreds of unique, accurate submodels, each tailored for a specific point on the accuracy-vs-compute curve, all without the overhead associated with complex methods like Neural Architecture Search (NAS) (https://arxiv.org/abs/1611.01578) (Figure 6).

Experimental Validation: Performance, Consistency, and Real-World Impact
The authors provide comprehensive empirical evidence to back their claims, demonstrating MatFormer's effectiveness across both language (MatLM) and vision (MatViT) domains.
For Language Models (MatLM):
Superior Performance: MatLM submodels consistently outperform their independently trained baseline counterparts in both validation loss and downstream task performance (Figure 2). The smaller submodels, which benefit most from the shared training of the universal model, show particularly strong gains.

Enhanced Consistency and Faster Inference: A key finding is that MatFormer's submodels are significantly more consistent in their predictions with the largest "universal" model (Figure 2c). This property is a game-changer for inference optimization techniques like speculative decoding (https://arxiv.org/abs/2211.17192), as high consistency minimizes prediction mismatches between the small "draft" model and the large "verifier" model, leading to fewer rollbacks and thus significant speed-ups. The paper shows that using a smaller, highly consistent MatLM as a draft model results in up to a 6% greater speed-up compared to using a baseline draft model (Table 2).

Reliable Scaling: The research also demonstrates that MatFormer models adhere to the same scaling laws as traditional Transformers (https://arxiv.org/abs/2001.08361), ensuring that their benefits are maintained as models continue to grow (Figure 3).




For Vision Transformers (MatViT):
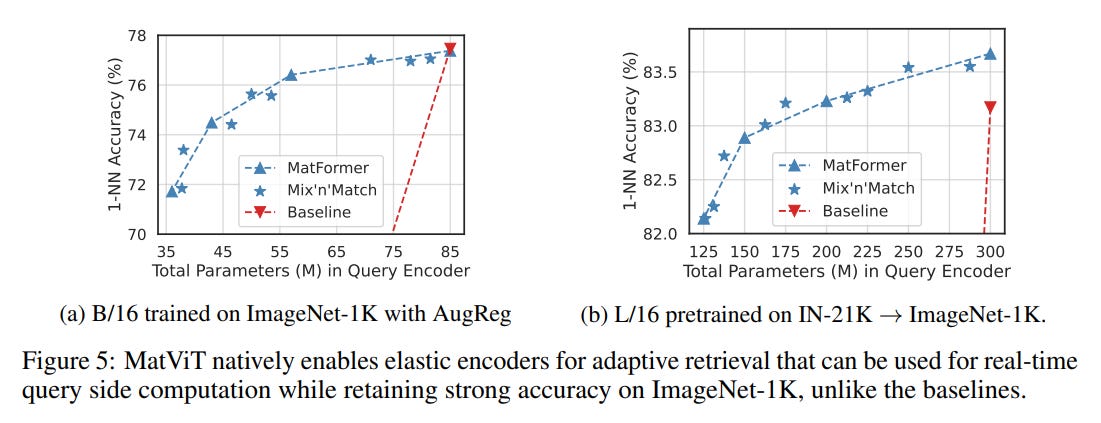
Elastic Encoders for Adaptive Retrieval: The results in computer vision are just as compelling. MatViT models match or exceed the classification accuracy of standard ViTs (Figure 4).

More impressively, they enable "elastic encoders" for adaptive image retrieval. Because the submodels preserve the metric-space structure of the universal model, a system can dynamically use a smaller, faster query encoder for simpler tasks and a larger one for complex queries, all while searching against a database embedded with the largest model. This can reduce query-side compute by 40% with a negligible (<0.5%) drop in accuracy—a feat not possible with standard baselines (Figure 5).


Limitations and Future Outlook
The authors are transparent about the work's limitations. The evaluation, while extensive, lacks statistical error bars due to the high cost of training. Additionally, the language models were trained on proprietary data, which limits direct reproducibility of those specific experiments, though the vision experiments used public datasets.
However, the path forward is clear and exciting. MatFormer lays the groundwork for truly adaptive AI systems. Future work could focus on developing the dynamic routing and hardware optimizations necessary to switch between submodels in real-time based on system load or input difficulty.
Conclusion
"MatFormer" is a significant contribution that rethinks model efficiency at an architectural level. By creating a single, universal model that can be flexibly deployed across a wide spectrum of computational budgets, it offers a practical and powerful solution to one of the key challenges facing the adoption of large-scale AI. The ability to extract hundreds of high-performing submodels "for free" not only democratizes access to tailored foundation models but also paves the way for more dynamic, resource-aware, and ultimately more intelligent AI systems. By drastically reducing amortized training and deployment costs, MatFormer offers a compelling path forward for a more sustainable and accessible AI ecosystem. This work is a valuable step towards a future where AI is not only powerful but also pragmatically and efficiently deployed everywhere.