Memory in the Age of AI Agents
Authors: Yuyang Hu, Shichun Liu, Yanwei Yue, Guibin Zhang, Boyang Liu, Fangyi Zhu, Jiahang Lin, Honglin Guo, Shihan Dou, Zhiheng Xi, Senjie Jin, Jiejun Tan, Yanbin Yin, Jiongnan Liu, Zeyu Zhang, Zhongxiang Sun, Yutao Zhu, Hao Sun, Boci Peng, Zhenrong Cheng, Xuanbo Fan, Jiaxin Guo, Xinlei Yu, Zhenhong Zhou, Zewen Hu, Jiahao Huo, Junhao Wang, Yuwei Niu, Yu Wang, Zhenfei Yin, Xiaobin Hu, Yue Liao, Qiankun Li, Kun Wang, Wangchunshu Zhou, Yixin Liu, Dawei Cheng, Qi Zhang, Tao Gui, Shirui Pan, Yan Zhang, Philip Torr, Zhicheng Dou, Ji-Rong Wen, Xuanjing Huang, Yu-Gang Jiang, Shuicheng Yan
Paper: https://arxiv.org/abs/2512.13564
Code: https://github.com/Shichun-Liu/Agent-Memory-Paper-List
TL;DR
WHAT was done? The authors present a comprehensive taxonomy for Agent Memory, moving beyond traditional “short-term/long-term” dichotomies to a structured framework defined by Forms (Token-level, Parametric, Latent), Functions (Factual, Experiential, Working), and Dynamics (Formation, Evolution, Retrieval). The paper systematically distinguishes agent memory from related concepts like RAG and Context Engineering, offering a blueprint for self-evolving systems.
WHY it matters? As LLM agents transition from static question-answering to long-horizon autonomous tasks, the stateless nature of the underlying models becomes a critical bottleneck. This work is significant because it formalizes memory not just as a storage buffer, but as an active, self-optimizing cognitive substrate necessary for continual learning and self-evolution without the prohibitive cost of constant retraining.

Details
The Cognitive Substrate Bottleneck
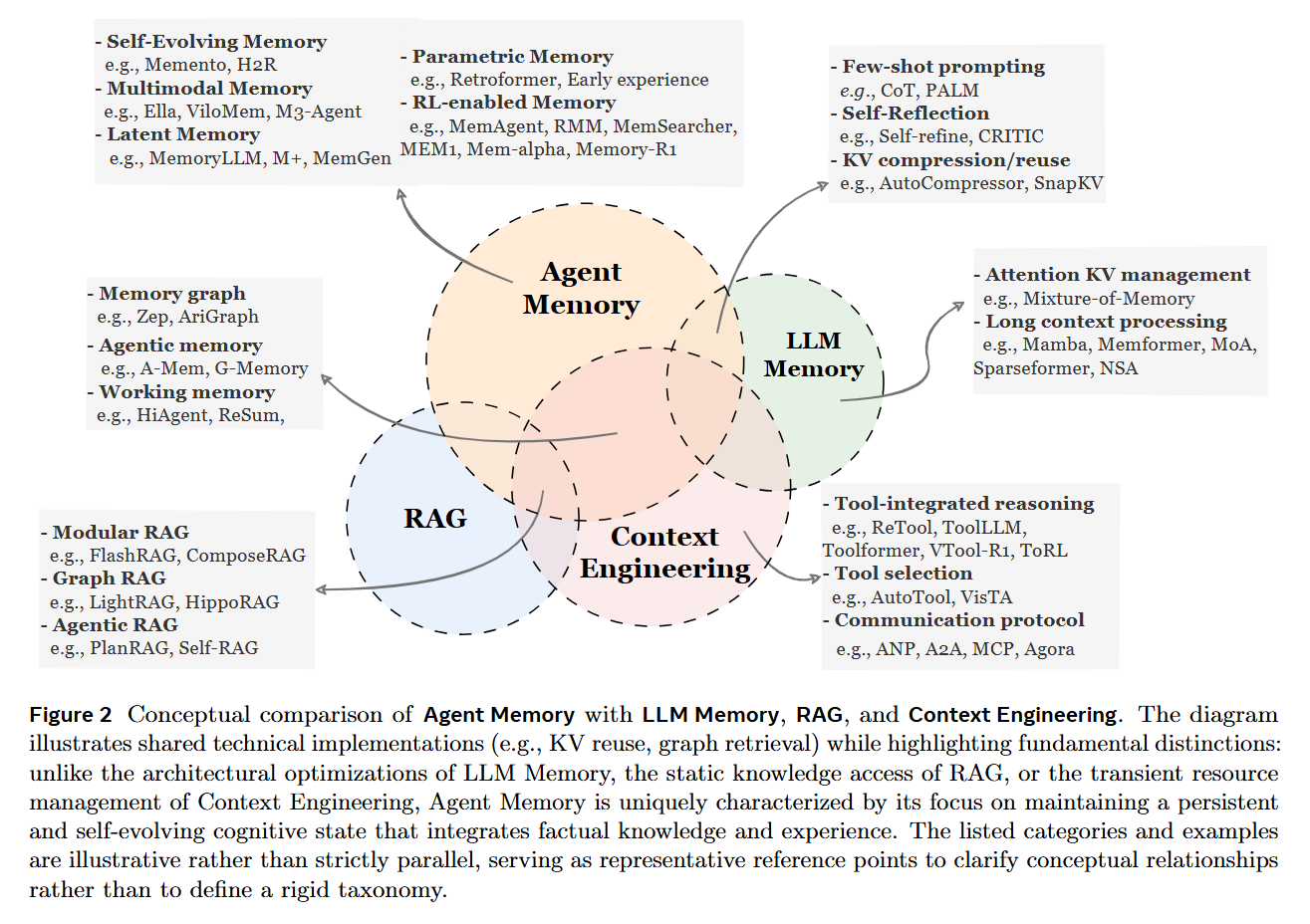
The transition from Large Language Models (LLMs) to autonomous agents has exposed a fundamental friction: the model is static, but the environment is dynamic. While techniques like Retrieval-Augmented Generation (RAG) provide access to external knowledge, and Context Engineering optimizes the immediate input window, neither fully addresses the requirement for a persistent, evolving identity that learns from interaction. The authors argue that current taxonomies are fragmented, conflating architectural optimizations (like KV-cache management) with cognitive functions. This survey clarifies the landscape by defining Agent Memory as a persistent, self-evolving system that enables an agent to maintain consistency, coherence, and adaptability over time (t→∞), distinguishing it from the transient resource management of Context Engineering or the static retrieval of traditional RAG.
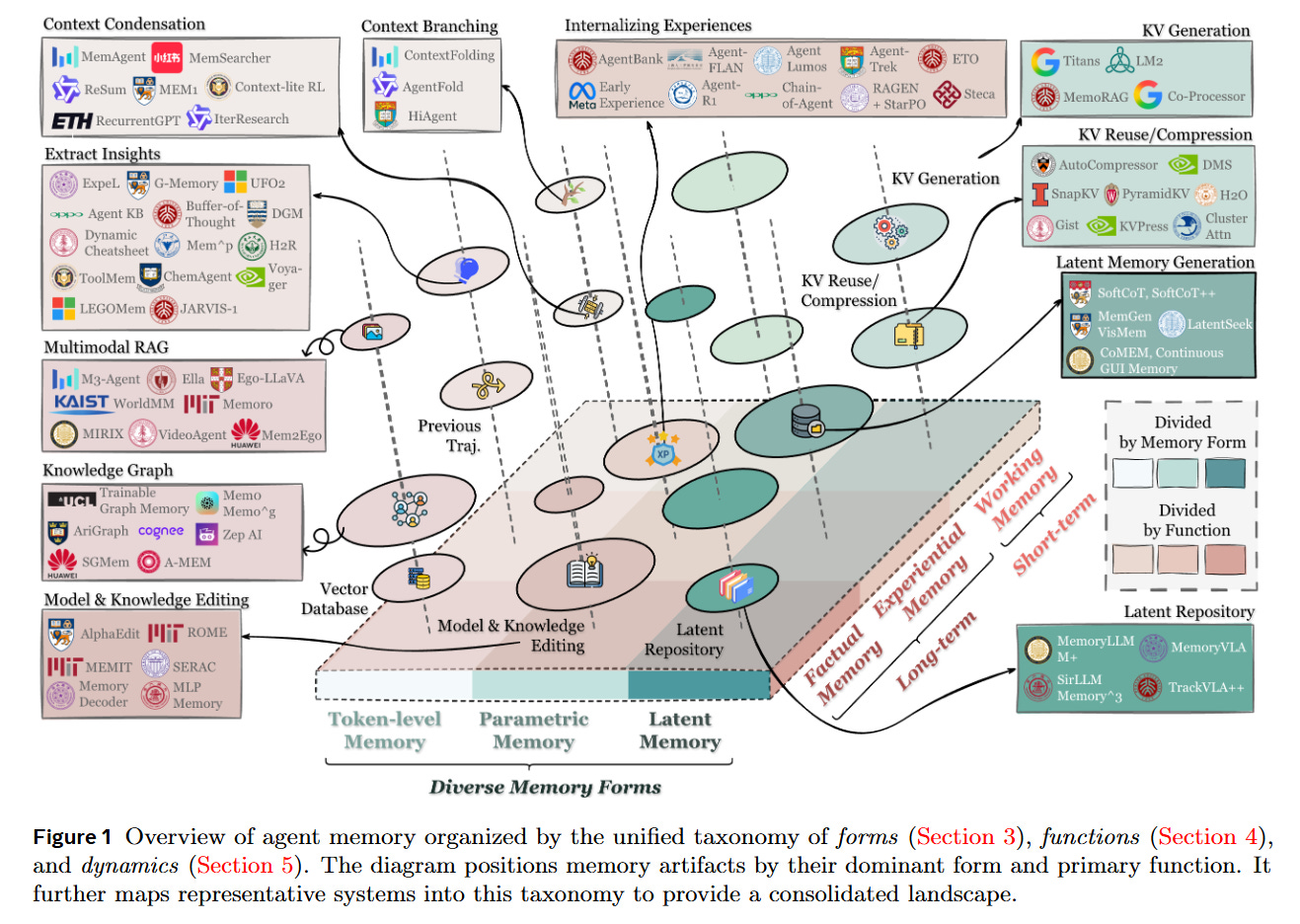
Forms of Retention: From Tokens to Parameters
To structure the landscape, the authors first categorize memory by its architectural Form, answering the question of where and how information is physically represented.
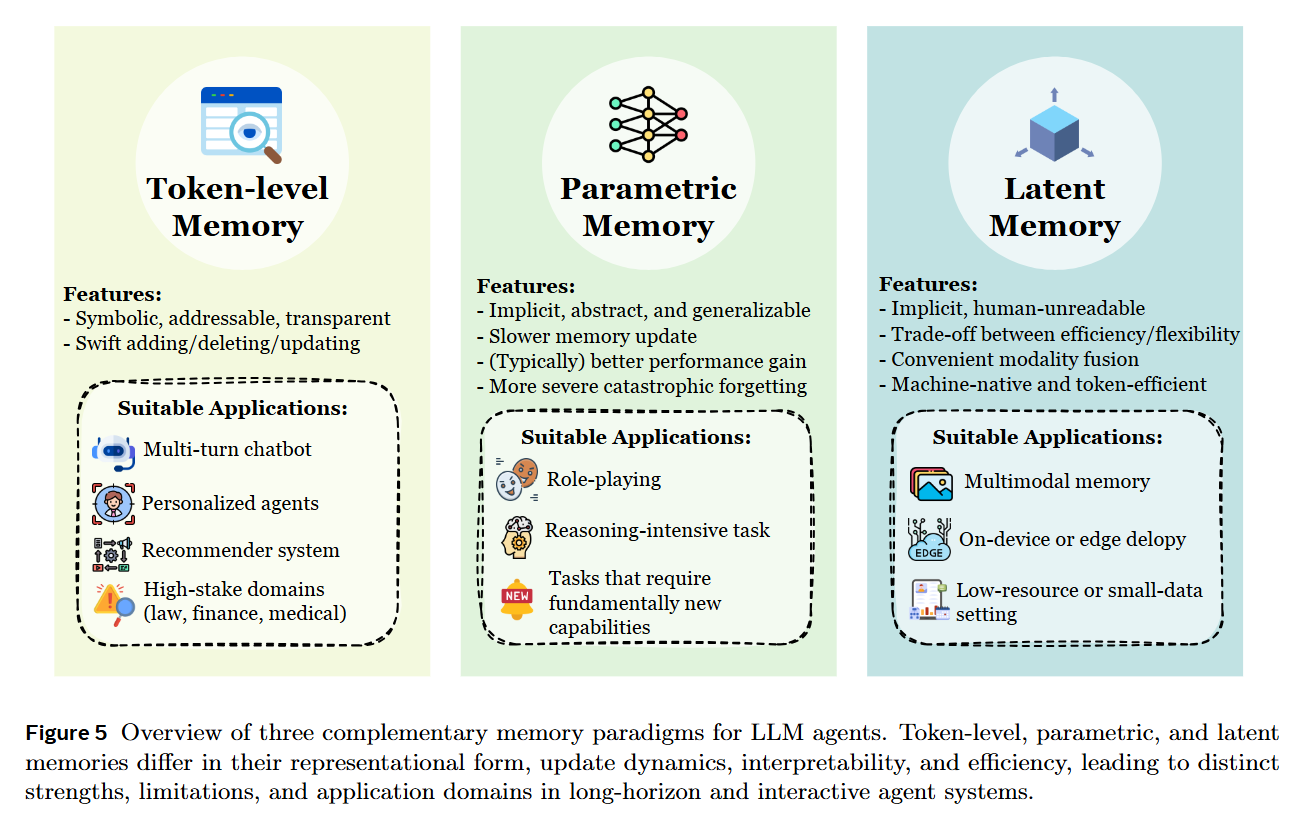
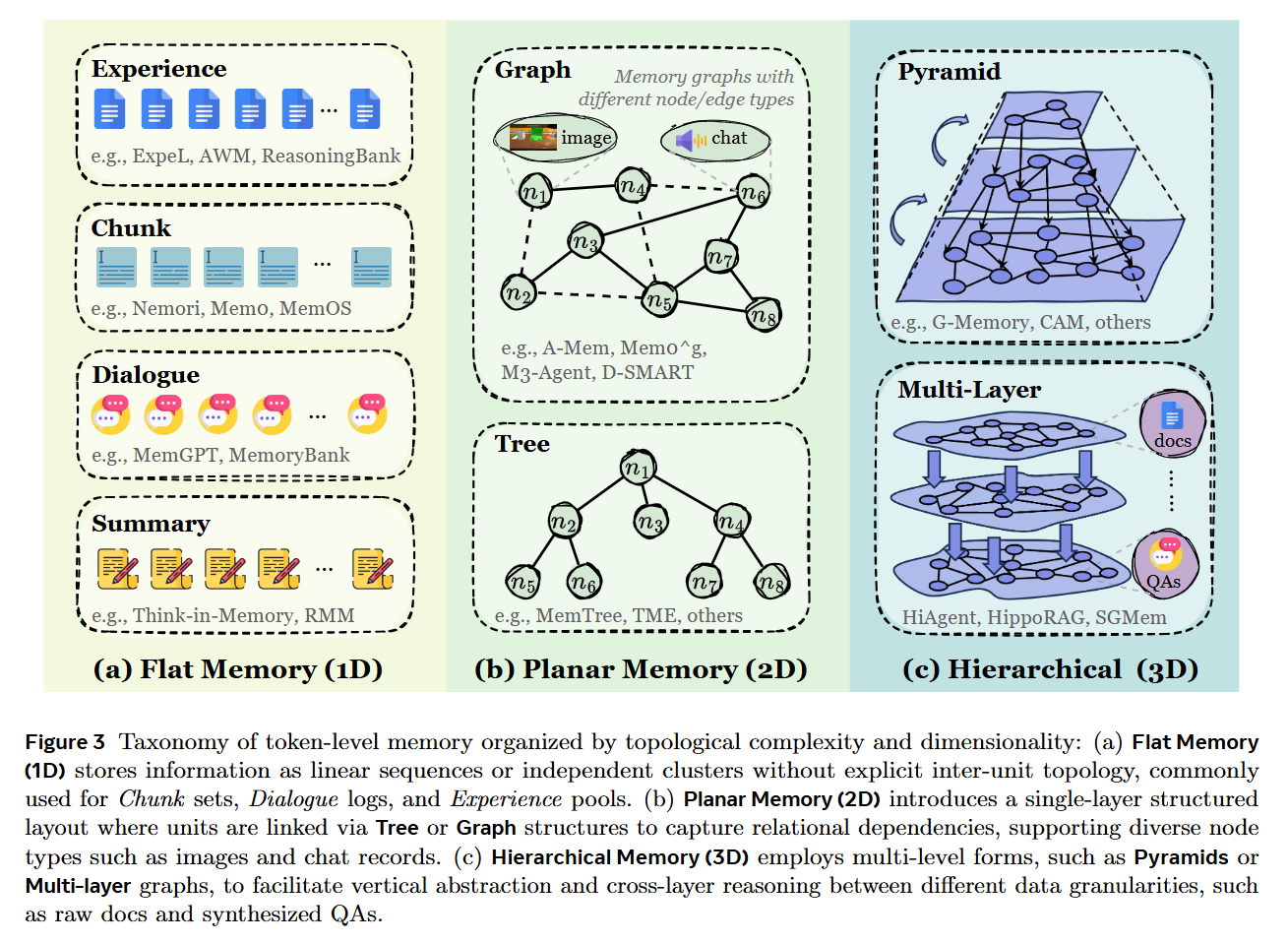
The most prevalent form is Token-level Memory, where information is stored as discrete, human-readable units (text chunks, JSON objects) in external databases. This offers high interpretability and editability but suffers from retrieval latency. The survey distinguishes between Flat (linear logs), Planar (graphs/trees within a single layer), and Hierarchical (multi-layer pyramids) organizations, as illustrated in Figure 3.
In contrast, Parametric Memory embeds information directly into the model’s weights. This can be Internal (via model editing techniques like ROME or MEMIT) or External (via adapters like LoRA). This form mimics biological “instinct”—it requires no retrieval step but suffers from catastrophic forgetting and high update costs.
Finally, the authors identify Latent Memory, where information is stored as continuous vector representations or KV-cache states. This offers a middle ground of high information density and machine-native compatibility, though at the cost of human interpretability.
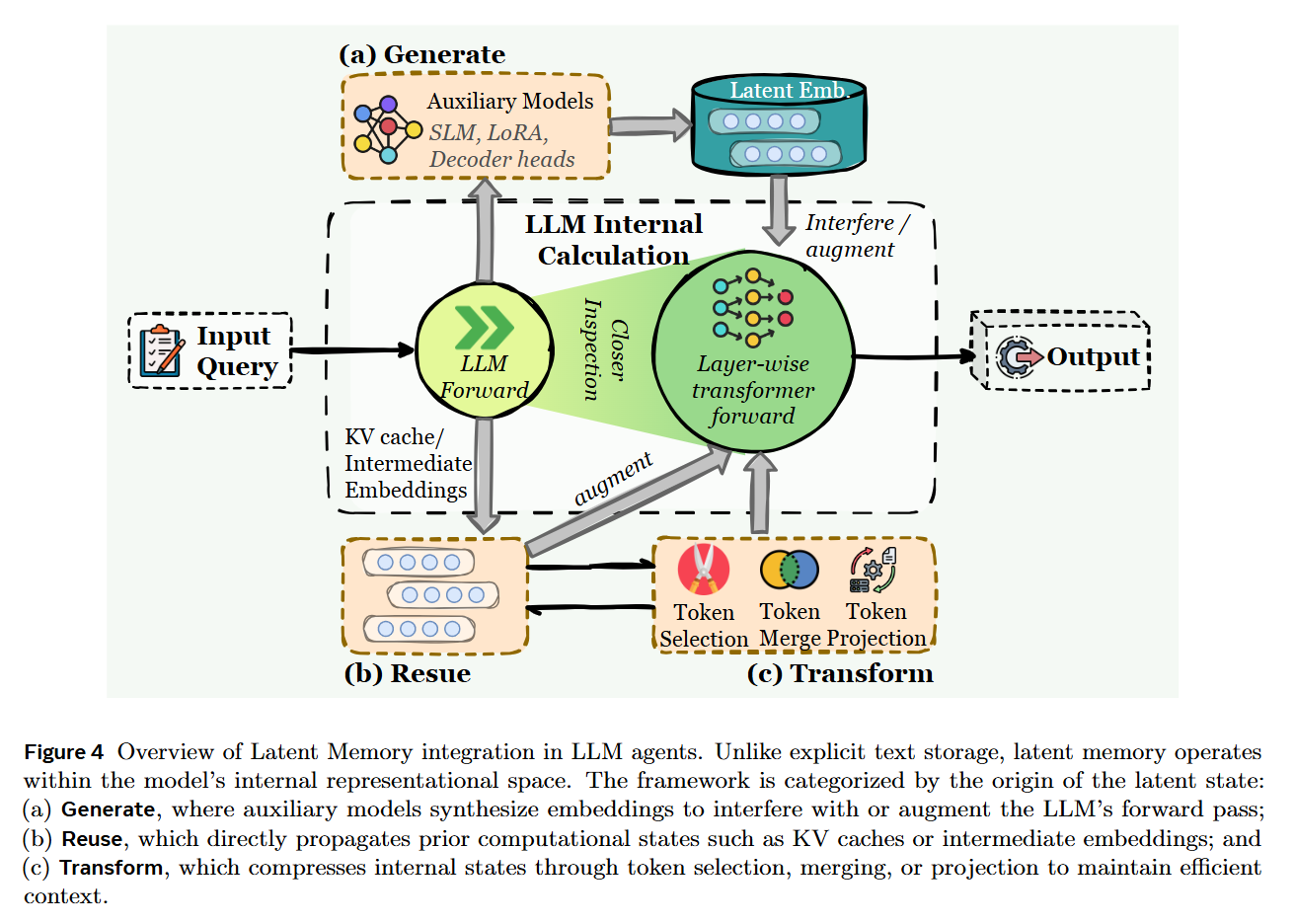
Functional Teleology: Factual vs. Experiential
Moving beyond the “long-term vs. short-term” temporal classification, the paper proposes a functional taxonomy based on the purpose of the memory. Factual Memory serves as the agent’s declarative knowledge base, ensuring consistency in user profiles and environmental states (e.g., “The user prefers Python,” or “The file is located at /tmp”). This underpins the agent’s persona and goal coherence.
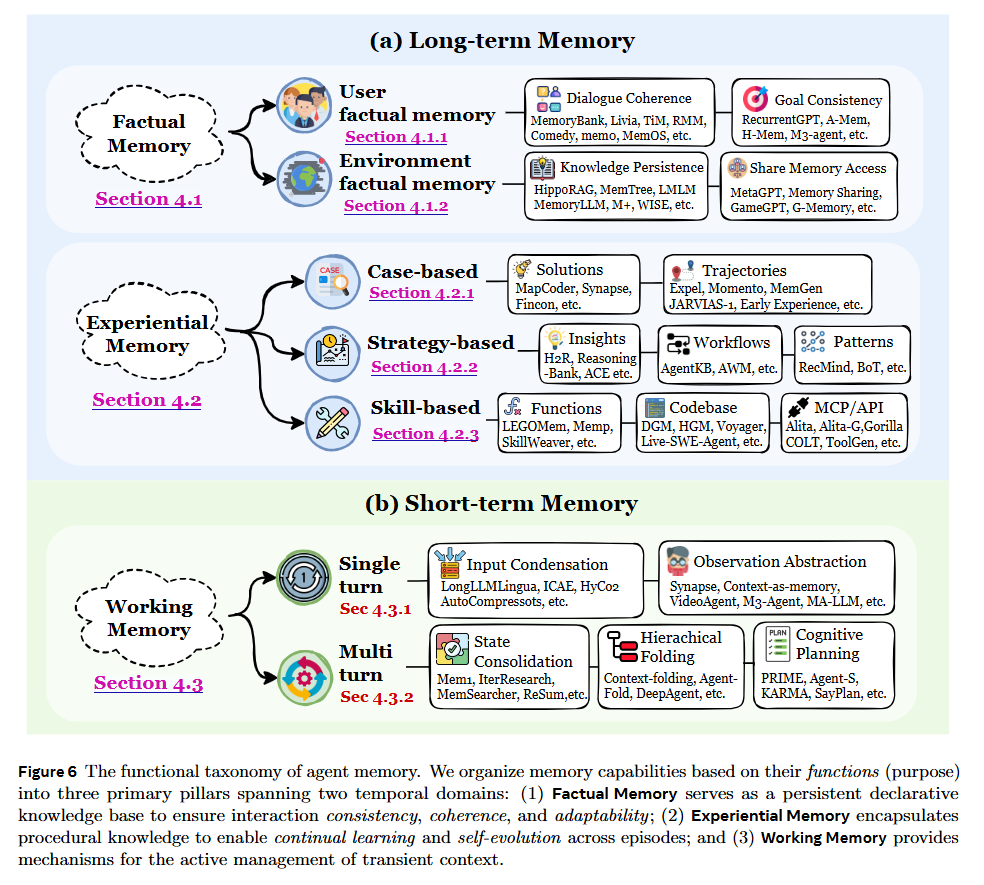
Crucially, the authors introduce Experiential Memory, which captures procedural knowledge—how to solve a problem rather than just what happened. This is divided into Case-based (raw trajectories for replay), Strategy-based (abstracted workflows and insights), and Skill-based (executable code or tool APIs). For example, rather than simply logging a conversation, an agent might distill a successful debugging session into a reusable “workflow” or “code snippet,” effectively transforming past experience into a retrievable skill. This distinction is vital for enabling agents to improve their performance on novel tasks without parameter updates.
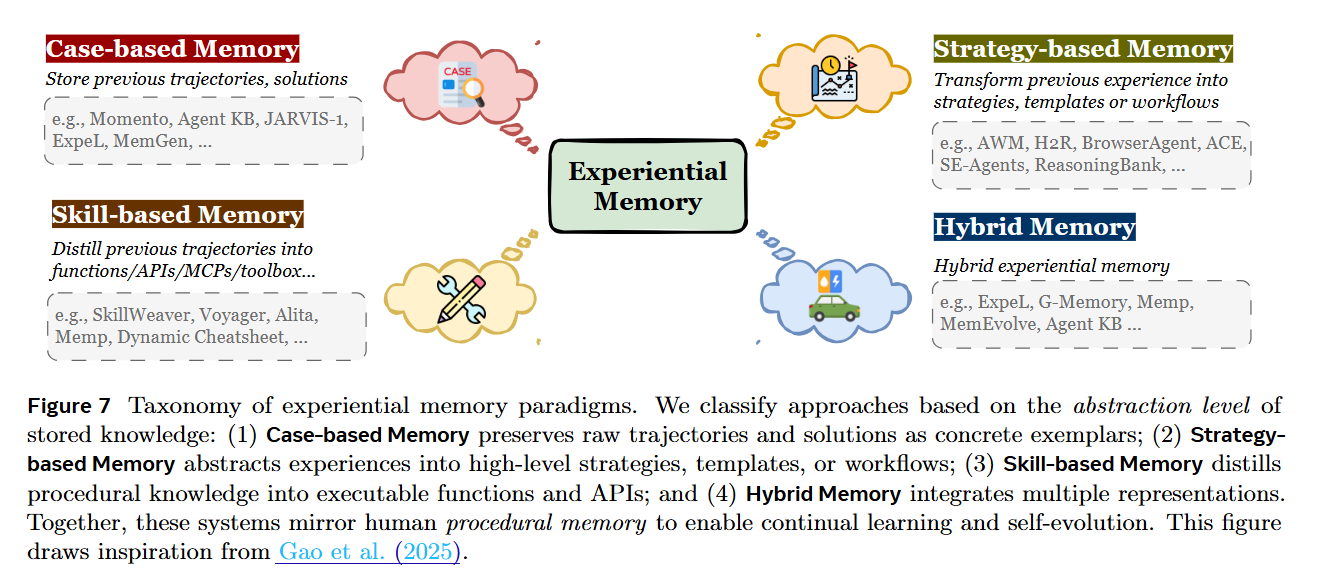
The Dynamics of Memory Evolution
The survey formalizes the lifecycle of memory through three operators: Formation, Evolution, and Retrieval.
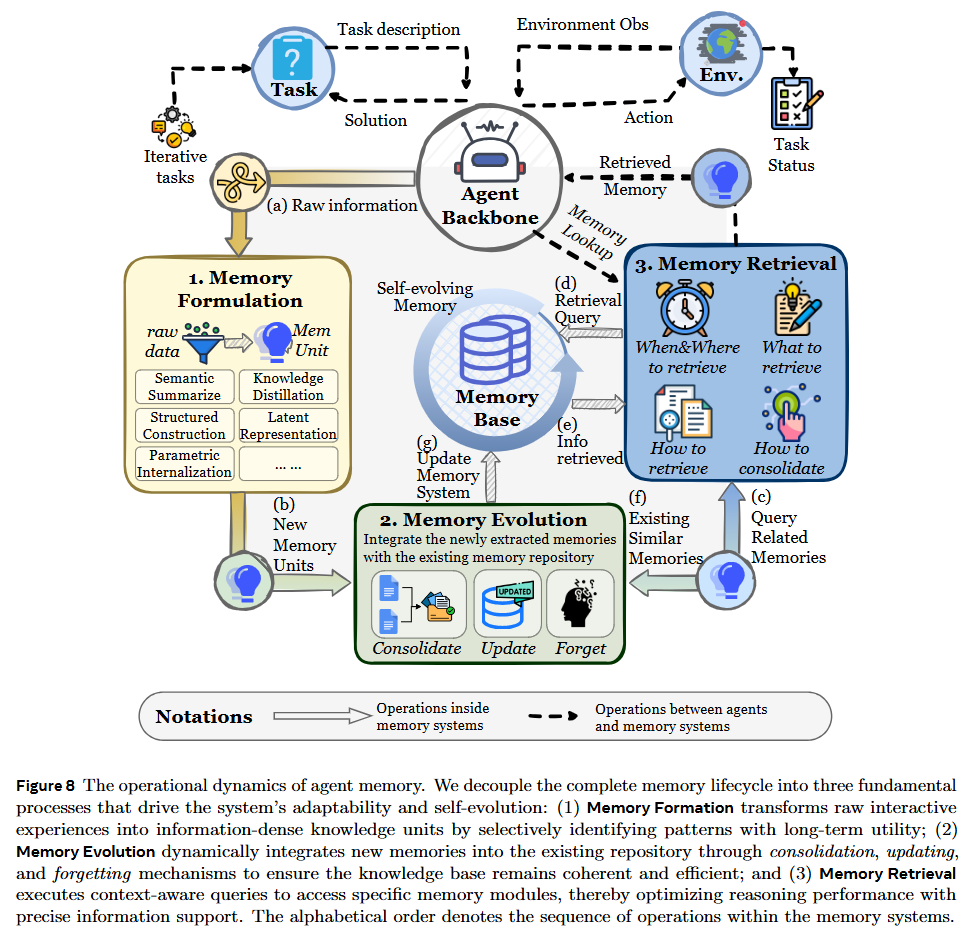
Memory Formation is described not as passive logging, but as an active transformation Mform=F(Mt,ϕt), where raw interaction traces ϕt are compressed, summarized, or distilled into useful artifacts. For instance, Semantic Summarization transforms linear streams into narrative blocks, while Structured Construction parses interactions into Knowledge Graphs.
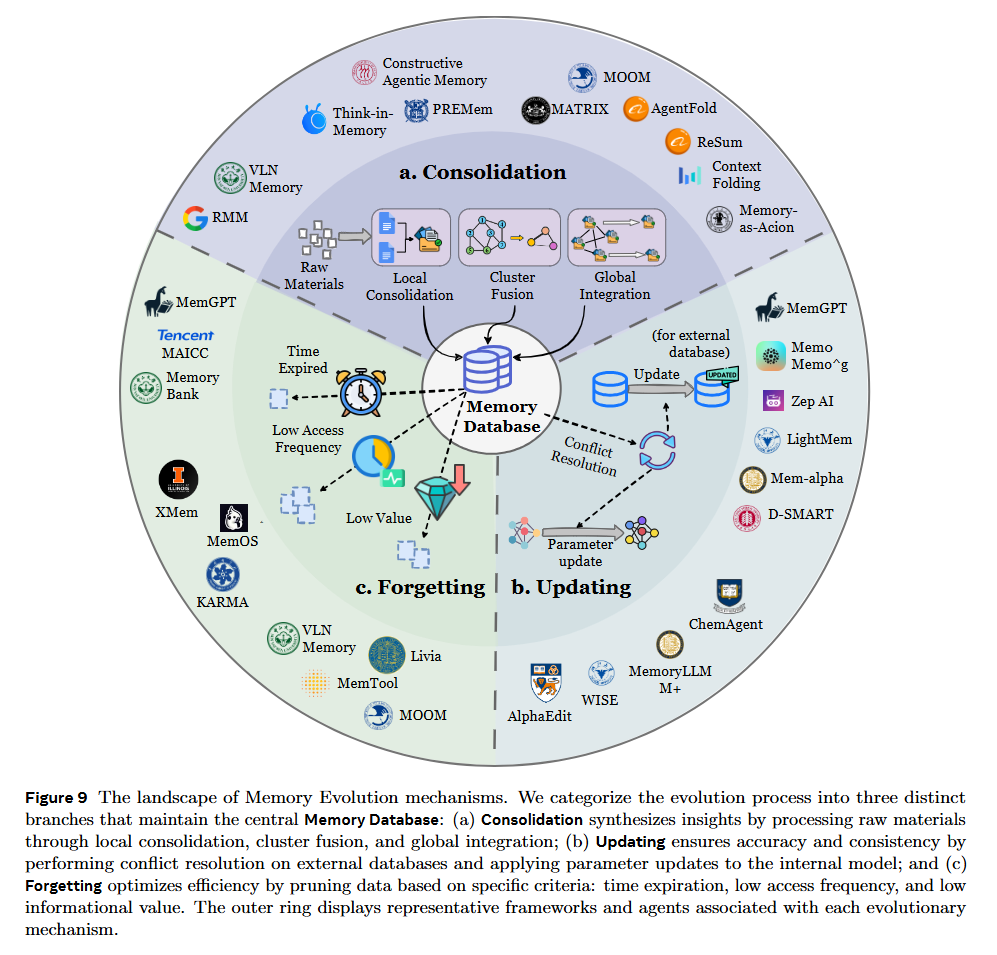
Memory Evolution addresses the “Stability-Plasticity” dilemma in agentic systems. It involves Consolidation (merging fragmented traces into schemas), Updating (resolving conflicts when new facts contradict old ones), and Forgetting (pruning low-utility information). The authors highlight a shift from heuristic-based evolution (e.g., LRU caches) to learning-based approaches, where the agent itself predicts the long-term utility of a memory trace.
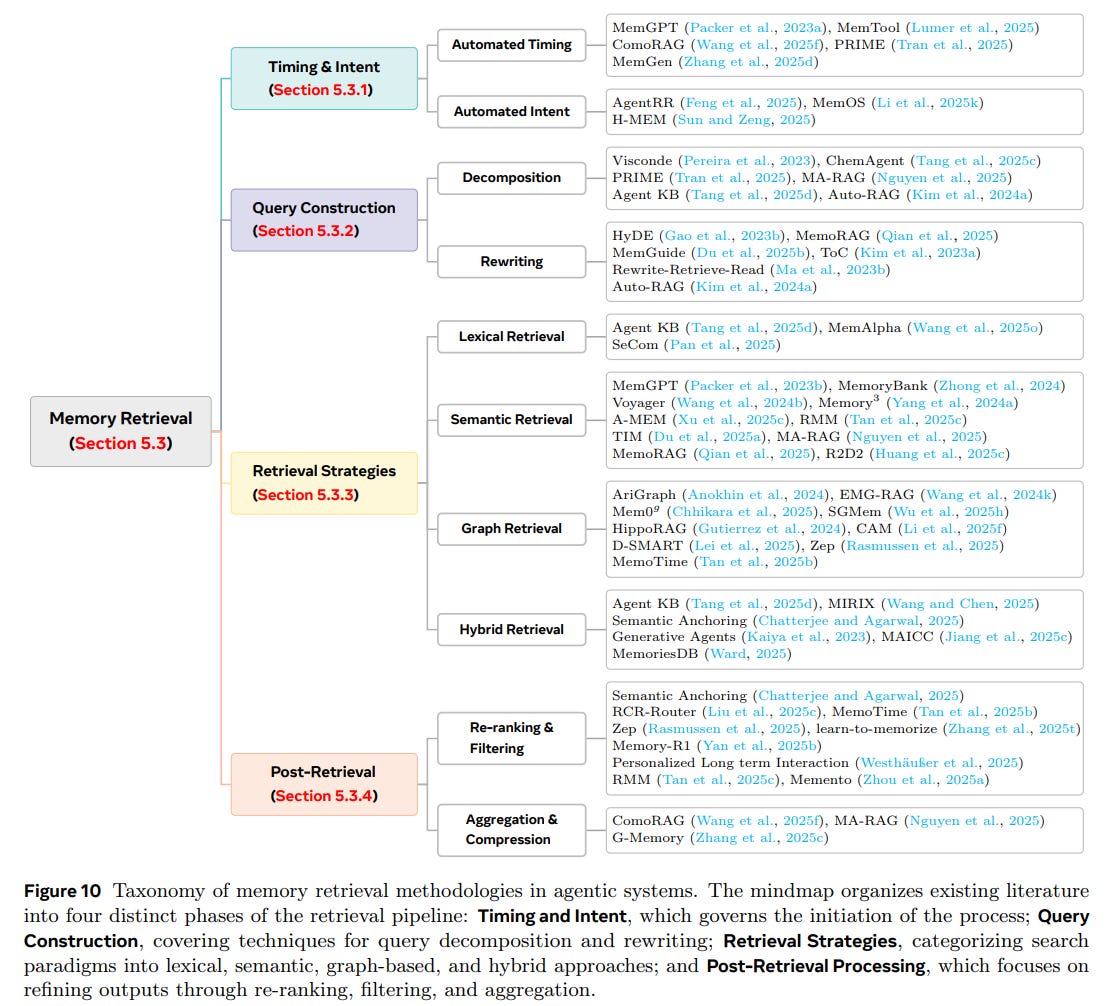
Finally, Retrieval is framed as a dynamic decision process involving timing (when to retrieve) and intent (what to look for), shifting from simple similarity search to Generative Retrieval, where the agent actively synthesizes a memory representation tailored to the current reasoning context.
Engineering the Cognitive Loop
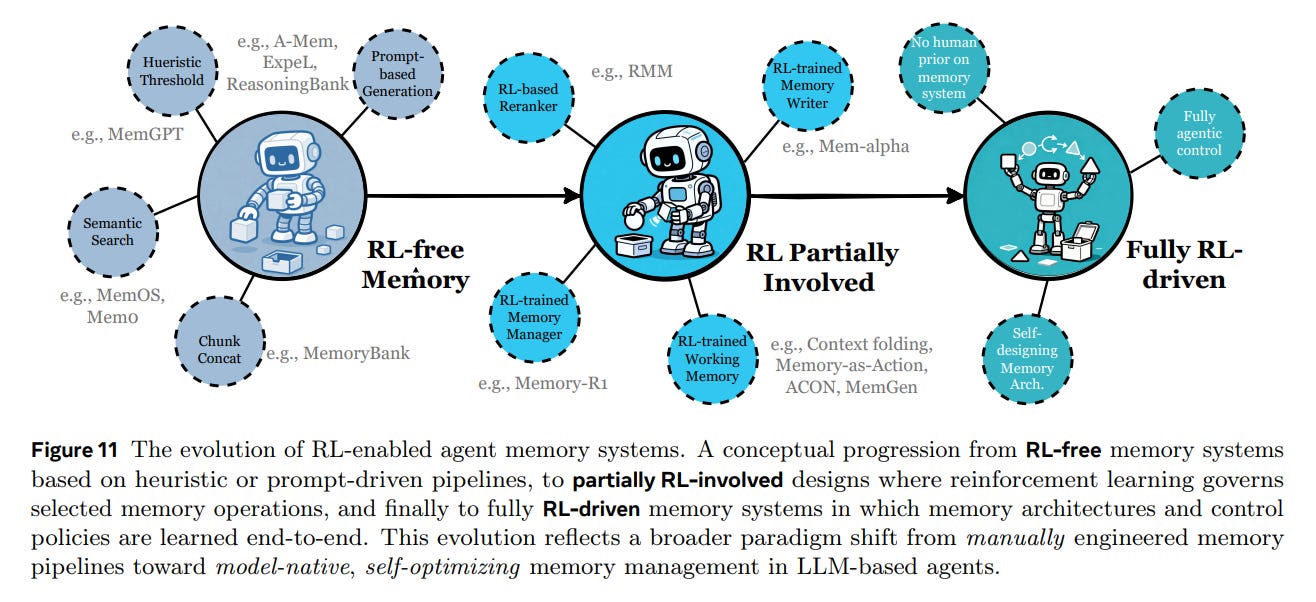
From an implementation standpoint, the paper reviews the transition from manually engineered pipelines to RL-driven Memory Management. Early systems like MemGPT relied on OS-like heuristics to manage context paging. The frontier, however, lies in treating memory operations (read/write/forget) as actions within a Reinforcement Learning policy. For example, systems like Mem-α or Memory-R1 treat the memory write operation as a learnable policy, optimized end-to-end for task success.
The authors also discuss the rise of Multimodal Memory, noting that current systems are moving from text-only logs to storing cross-modal embeddings (e.g., visual tokens in MemoryVLA) to support embodied agents that must maintain spatial and object permanence.
Limitations and Trustworthiness
The authors critically examine the risks associated with persistent memory. Trustworthiness is a primary concern; unlike a stateless model, a memory-augmented agent creates vectors for privacy leakage and prompt injection attacks that persist across sessions. There is a tension between personalization (remembering user details) and privacy (the right to be forgotten). Furthermore, the reliance on the LLM to manage its own memory introduces a circular dependency: if the model hallucinates during the Memory Formation or Consolidation phase, it corrupts its own long-term knowledge base, leading to compounding errors.
Impact and Conclusion
This survey provides a necessary rigorous framework for a field that has grown rapidly but chaotically. By delineating Experiential Memory and RL-driven Dynamics, the authors point toward the next major leap in AI: agents that do not just retrieve static knowledge, but actively cultivate a “mind” of experiences, skills, and instincts. The move from Retrieval-centric to Generative memory paradigms suggests that future agents will likely synthesize latent memory tokens on demand, mirroring the reconstructive nature of biological memory, rather than simply querying a database of immutable text logs.