
MesaNet
Shifting the Paradigm from Fixed Recurrence to In-Network Optimization
MesaNet: Sequence Modeling by Locally Optimal Test-Time Training
Authors: Johannes von Oswald, Nino Scherrer, Seijin Kobayashi, Luca Versari, Songlin Yang, Maximilian Schlegel, Kaitlin Maile, Yanick Schimpf, Oliver Sieberling, Alexander Meulemans, Rif A. Saurous, Guillaume Lajoie, Charlotte Frenkel, Razvan Pascanu, Blaise Agüera y Arcas, and João Sacramento
Paper: https://arxiv.org/abs/2506.05233
Code: https://github.com/fla-org/flash-linear-attention
TL;DR
WHAT was done? The paper introduces MesaNet, a recurrent neural network (RNN) architecture featuring a novel "Mesa layer." This layer operationalizes the concept of "optimal test-time training." Instead of relying on a fixed, learned update rule like other modern RNNs (Mamba, xLSTM), the Mesa layer, at every time step, explicitly solves an in-context regression objective to optimality. This is achieved using a fast conjugate gradient (CG) solver. The design is numerically stable and chunkwise parallelizable, enabling efficient training on modern hardware.
WHY it matters? This work challenges the traditional trade-off where RNNs achieve fixed, low-cost inference at the expense of performance. By embedding an explicit optimization solver into the forward pass, MesaNet achieves state-of-the-art results among RNNs and proves competitive with Transformers, especially on synthetic in-context learning tasks. Its most significant innovation is the ability to dynamically allocate compute at inference time—by varying the number of CG solver steps—based on input complexity. This introduces a principled method for trading performance for computational cost and reframes recurrence not merely as a state-passing mechanism, but as an active, in-network problem-solving process.
Prequel to the work can be found here:


Details
The quest for sequence models that are both powerful and efficient is a central theme in modern AI research. While Transformers dominate due to their performance, their inference costs scale linearly with sequence length, posing a challenge for very long contexts. Recurrent Neural Networks (RNNs) offer an elegant alternative with constant memory and compute, but have historically struggled to match Transformer performance. A recent paper introduces MesaNet, a novel architecture that doesn't just incrementally improve upon existing RNNs but fundamentally rethinks their computational role.
A New Philosophy: Optimal Test-Time Training
At the heart of MesaNet is a design philosophy the authors call "optimal test-time training." Many recent RNNs, like Mamba or DeltaNet, can be viewed as taking a single online learning step on a regression loss, using only the most recent token to update their internal state. MesaNet takes this concept to its logical conclusion: instead of a single, approximate step, it solves the cumulative regression loss over all previously seen tokens to optimality. It's the difference between taking one small step downhill and finding the absolute bottom of the valley at every moment in time.

The core of the architecture is the Mesa layer (proposed earlier), which acts as a "fast weight programmer" integrated into a standard Transformer-style backbone (Figure 1).
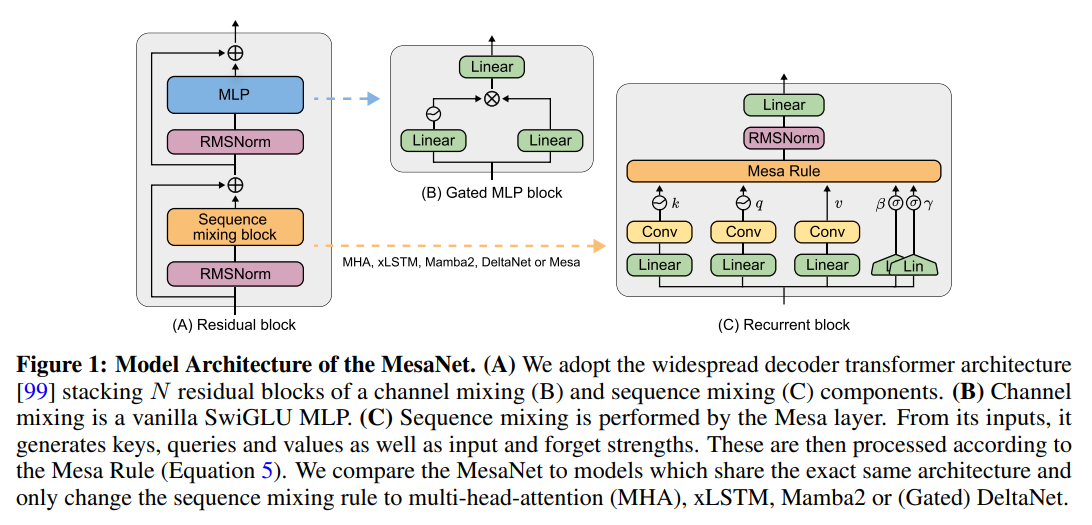
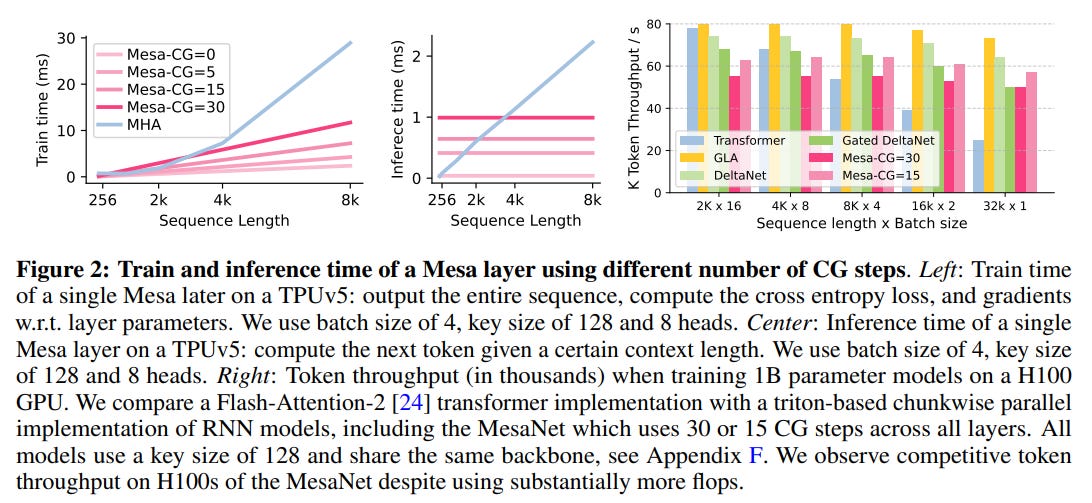
These "fast weights" form a linear model that is dynamically programmed by the context. The choice of the conjugate gradient (CG) method to solve for these weights is not arbitrary. The authors show that the most compute-intensive part of a CG iteration can be expressed in a form identical to Gated Linear Attention. This clever observation allows them to leverage existing, highly-optimized parallel algorithms, making the iterative solver practical to run on modern accelerators during training (Figure 2).
Experimental Results: A Nuanced Picture of Performance
MesaNet's performance is evaluated across a comprehensive suite of synthetic and natural language tasks, painting a picture of both its strengths and the remaining challenges for recurrent models.
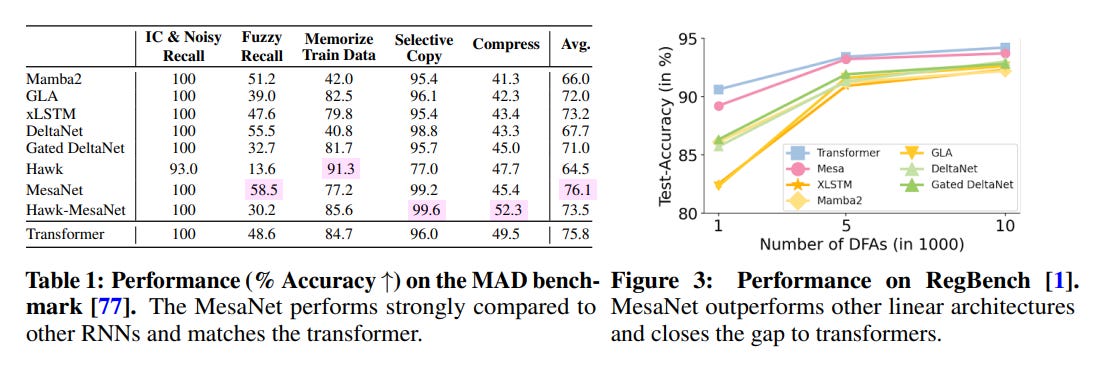
On synthetic benchmarks like MAD and RegBench, which test for in-context learning and token manipulation, MesaNet excels. It achieves the highest average performance on the MAD benchmark and is the first linearized transformer to match the performance of a full Transformer on RegBench, a task where other recurrent models have traditionally lagged (Table 1, Figure 3). This highlights the power of its optimal in-context solving capability.
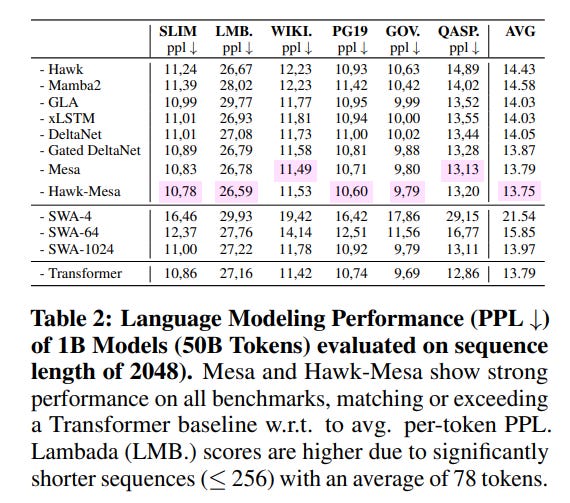
In large-scale language modeling on the SlimPajama dataset, MesaNet models (up to 940M parameters) achieve lower validation perplexity than strong baselines like Mamba2, xLSTM, and even a comparable Transformer (Table 2).
However, a deeper analysis reveals a fascinating dynamic: like other RNNs, MesaNet performs better than Transformers on early tokens in a sequence, but Transformers retain an edge on later tokens (Figure 4).
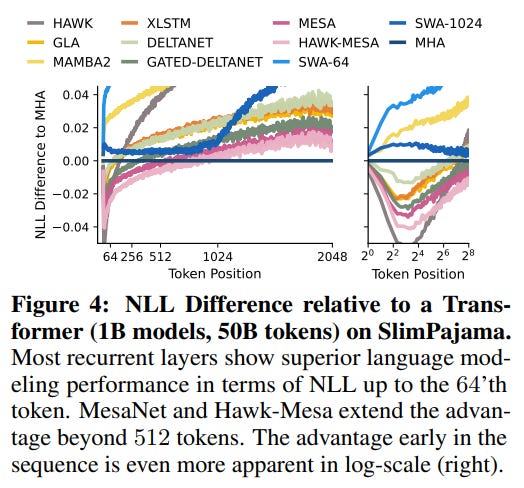
This suggests that while MesaNet pushes the boundaries of recurrent models, there may be fundamental architectural differences in how information is aggregated over very long distances.
This nuance is further reflected in downstream benchmarks. MesaNet consistently outperforms other RNNs on tasks like zero-shot reasoning and in-context recall. Yet, a performance gap to Transformers persists on "global" benchmarks that require understanding the full context (Figure 6). This finding raises important questions about the suitability of current RNN architectures for tasks demanding true long-range, global reasoning, and suggests that perplexity alone may not be a complete measure of this capability.
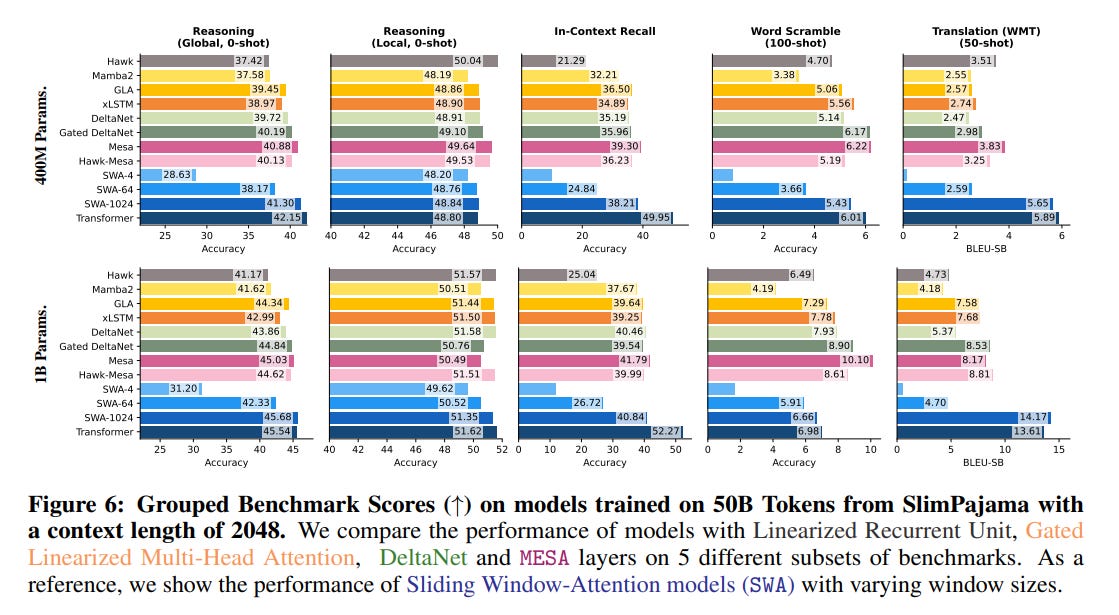
Impact and Future Directions: Dynamic Compute and In-Network Optimization
Perhaps the most impactful contribution of MesaNet is its principled approach to dynamic compute allocation. Because the CG solver's convergence depends on the complexity of the input, the number of iterations—and thus the computational cost—can adapt to the sequence at hand. The authors show that by using a dynamic stopping criterion, MesaNet can achieve nearly the same performance as a model with a fixed, high number of CG steps while significantly reducing the average compute (Figure 7). This moves away from the static compute graph of most neural networks and toward a more adaptive, input-dependent processing model.
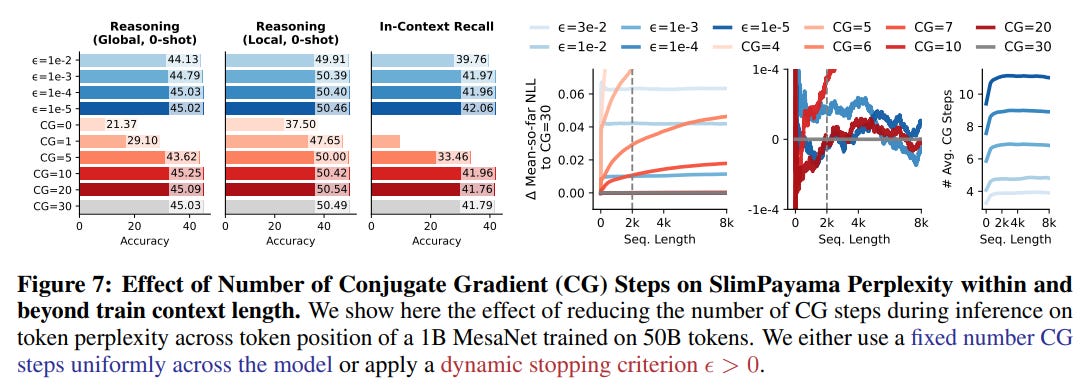
This work is a powerful embodiment of mesa-optimization (https://arxiv.org/abs/1906.01820), a concept where a base learning algorithm discovers a meta-optimizer. Here, backpropagation discovers the right setup for the Mesa layer, which in turn executes an explicit optimization algorithm during inference. This also connects to the broader trend of "optimization as a layer," seen in models like Deep Equilibrium Models (https://arxiv.org/abs/1909.01377), where solving an optimization problem is part of the network's forward pass. MesaNet offers a new, sequential application of this powerful paradigm.
The authors identify several promising directions for future work. The most critical is improving test-time efficiency, potentially by warm-starting the CG solver or developing hybrid models. Another intriguing avenue is learning the optimization algorithm itself or backpropagating through the unrolled CG process to train the model to be more efficient.
Limitations and Overall Assessment
The primary limitation of MesaNet is its increased inference cost compared to other RNNs. The "optimal" solution comes at the price of additional FLOPs, scaling with the number of CG steps. This dynamic cost, while a conceptual strength, could also introduce variable latency, a potential issue for real-time applications. Furthermore, despite its advancements, the paper honestly portrays that a performance gap with Transformers remains on tasks requiring true global context integration, suggesting that the problem of long-range dependencies in RNNs is not yet fully solved.
In conclusion, "MesaNet: Sequence Modeling by Locally Optimal Test-Time Training" is a significant and high-quality contribution to the field. It introduces a powerful new paradigm for sequence modeling where recurrent networks actively solve optimization problems during inference. While not a definitive "Transformer-killer" due to the compute trade-offs and remaining limitations, MesaNet provides a compelling glimpse into a future where neural networks are not just static function approximators but dynamic, adaptive problem solvers. This work is a thought-provoking read that pushes the boundaries of recurrent architectures and will likely inspire a new wave of research into in-network optimization.