
MiniMax Sparse Attention
Authors: Xunhao Lai, Weiqi Xu, Yufeng Yang, Qiaorui Chen, Yang Xu, Lunbin Zeng, Xiaolong Li, Haohai Sun, Haichao Zhu, Vito Zhang, Jinkai Hu, Jiayao Li, Rui Gao, Zekun Li, Songquan Zhu, Jingkai Zhou and Pengyu Zhao
Paper: https://arxiv.org/abs/2606.13392
Code: https://github.com/MiniMax-AI/MSA
Model: https://huggingface.co/MiniMaxAI/MiniMax-M3
TL;DR
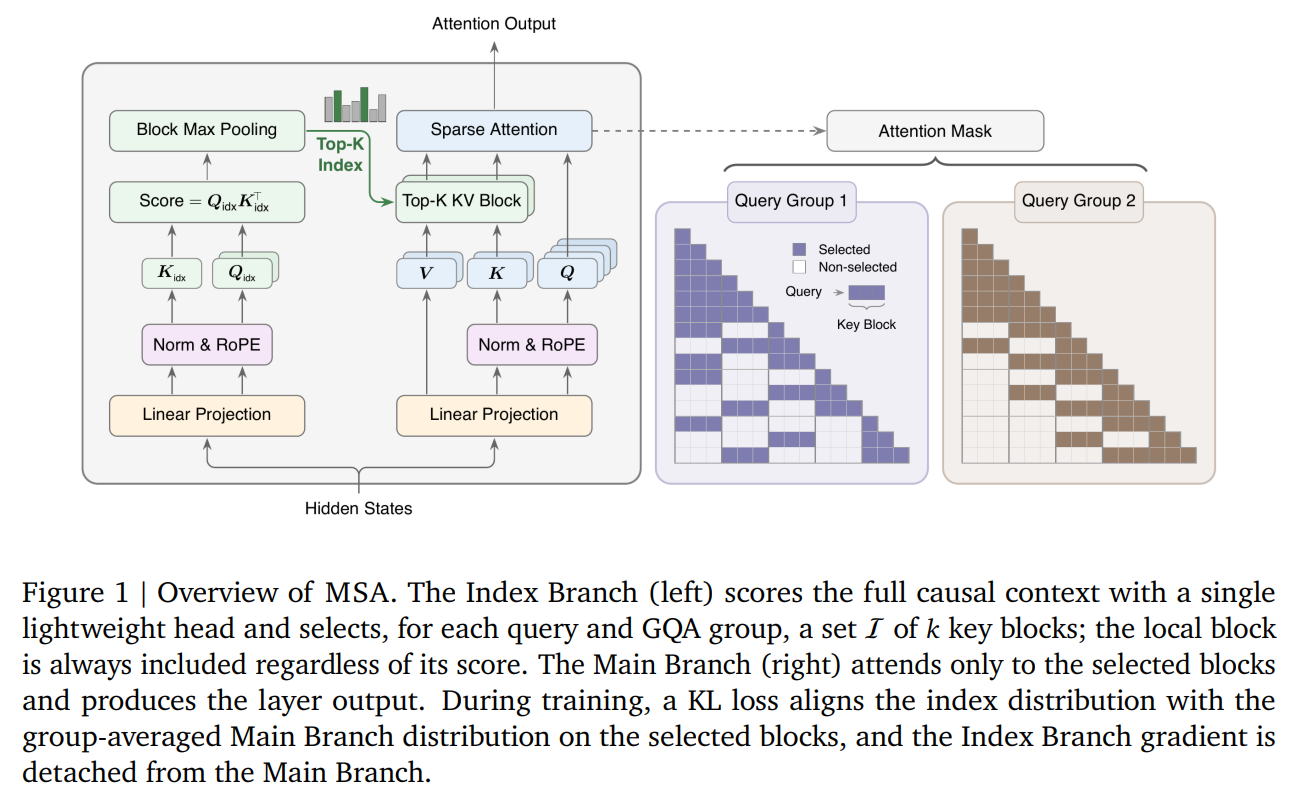
WHAT was done? The authors introduce MiniMax Sparse Attention (MSA), a hardware-algorithm co-designed blockwise sparse attention mechanism built directly on top of Grouped-Query Attention (GQA). MSA leverages a lightweight Index Branch to select a subset of key-value blocks independently per GQA group, and a Main Branch that executes exact block-sparse attention over only the chosen blocks.
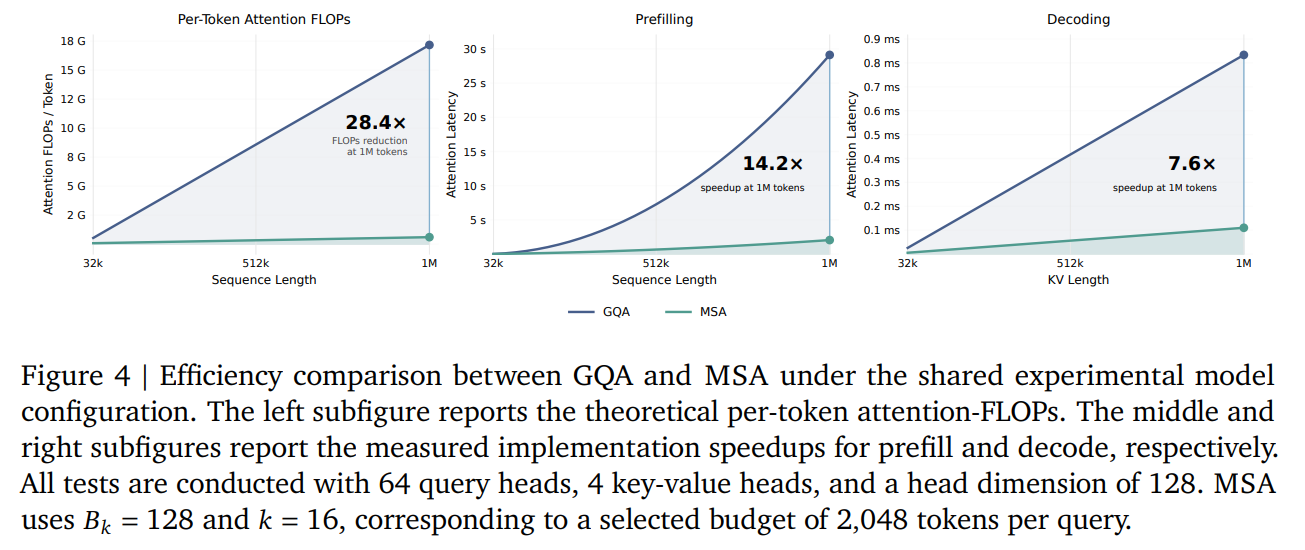
WHY it matters? At ultra-long contexts (up to one million tokens), the quadratic overhead of standard attention creates a severe computational bottleneck. MSA breaks this bottleneck, reducing per-token attention FLOPs by up to 28.4× at 1M context while matching GQA performance on major downstream, agentic, and multimodal benchmarks. Through custom hardware kernels, these theoretical gains translate to a 14.2× speedup in prefill and a 7.6× speedup in decoding on NVIDIA H800 GPUs.

Details
The Ultra-Long Context Efficiency Bottleneck
Frontier large language models increasingly require long-context capability to support complex workflows such as multi-turn agentic planning, multi-file code repository analysis, and massive document synthesis. However, the exact computation of standard softmax attention scales quadratically, O(N2), with respect to the sequence length N. While modern architectures often employ Grouped-Query Attention (GQA) to reduce the memory footprint of the key-value (KV) cache, the computational complexity of the attention operation remains a major bottleneck. The field has explored various mitigations, such as linear and recurrent attention alternatives like Mamba, static sliding-window patterns, and inference-only cache pruning strategies like H2O or SnapKV. While inference-only sparsifiers avoid training costs, they underperform during complex reasoning and do not reduce training-time computation. Conversely, natively trained sparse methods like Native Sparse Attention (NSA) or Mixture of Block Attention (MoBA) introduce high routing overheads or rigid head-dimension constraints. MSA addresses this trade-off by introducing a simple, GQA-group-shared, blockwise selection strategy that aligns perfectly with GPU hardware execution.
MiniMax Sparse Attention First Principles: Group-Shared Block Selection
MSA models the attention operation as a two-stage process consisting of an Index Branch and a Main Branch, operating at GQA-group and block-level granularity. Mathematically, let X∈RN×dmodel represent the input hidden states, where N is the sequence length and dmodel is the model’s hidden dimension.
The Index Branch introduces two lightweight projection matrices to construct index query and key representations, denoted as Qidx=XWqidx∈RN×Hkv×didx and Kidx=XWkidx∈RN×1×didx, where Hkv represents the number of key-value heads (defining the GQA groups) and didx is the index head dimension. For a query at position i and GQA group r, the token-level indexing scores Si,jidx,(r) are computed as:
To transition to block-granular routing, these token scores are compressed using block-level max-pooling. Defining a block partition B1,…,BB of block size Bk, the block-level score Mi,bidx,(r) for block b is computed as:
Using these block scores, the Index Branch selects the top-k block indices:
The Main Branch then performs exact dot-product softmax attention restricted to the gathered blocks. For any query head h within GQA group r, the attention output is:
where dh is the head dimension of the Main Branch, Qi(h) is the query vector, and
K(r)[Ii(r)] and V(r)[Ii(r)] denote the keys and values gathered from the selected block indices. This mechanism ensures that attention is only calculated over k⋅Bk tokens, transforming the linear per-query attention cost of O(N) to a constant O(k⋅Bk) as sequence length increases.
The Algorithm Execution Flow
To understand the operational flow, consider a concrete sequence where the model processes a sequence of length N=131,072 tokens. With a block size Bk=128, the sequence is split into B=1024 blocks. As illustrated in the architecture overview of Figure 1, the process begins when the Index Branch projects the input hidden states to calculate the token-level scores. Instead of executing exponentiations across the entire context, the system runs a custom BlockMaxPool operation, aggregating the scores of the 128 tokens within each block into a single scalar block score. For each query position, the top k=16 blocks are selected. Crucially, the local block containing the current query is always forced into this set to preserve immediate context. The Main Branch then gathers only the keys and values corresponding to these selected blocks, constructing a highly sparse key-value representation. The final attention scores are calculated solely within this restricted set, avoiding the need to process the remaining blocks of the sequence.
Hardware-Software Co-Design and Kernel Optimizations
The authors emphasize that algorithmic sparsity only translates into real-world wall-clock speedups if paired with hardware-optimized execution paths. Standard implementations of top-k selection and sparse gathering often suffer from memory bottlenecks and low Tensor Core utilization on modern GPUs. To solve this, MSA introduces three specialized CUDA kernel designs.
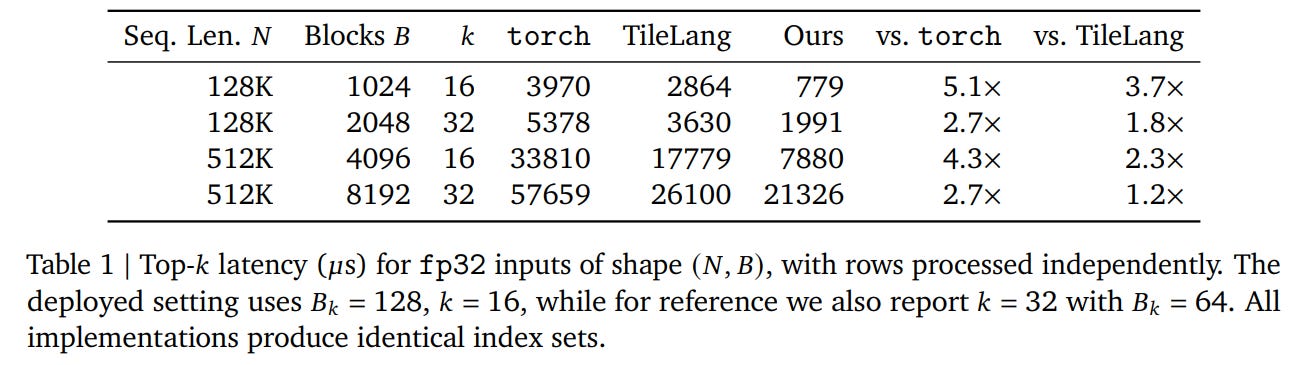
First, because softmax is an order-preserving transformation, the index selection bypasses the exponential, summation, and normalization steps, performing an exp-free top-k selection directly on the raw dot-product scores. The specialized top-k kernel utilizes a per-thread register-cached min-heap combined with a warp-shuffle reduction, which significantly outperforms default implementations, as detailed in Table 1.
Second, MSA organizes the main attention branch in a KV-outer loop order with query gathering instead of a query-outer loop. While a query-outer loop yields a FLOPs-to-IO ratio proportional to the GQA ratio G, the KV-outer loop achieves a ratio of approximately ⅔Bk. Since ⅔Bk≫G in typical setups (e.g., 85≫16), this loop reordering dramatically increases arithmetic intensity and Tensor Core occupancy.
Third, to mitigate the performance impact of highly popular key-value blocks (such as attention sinks) being selected by almost all queries, the GPU scheduler splits each KV tile along its query dimension into chunks of at most ∼2kBk queries (amounting to 4,096 queries under the default configuration of k=16 and Bk=128). This pre-scheduled tile chunking distributes the workload across multiple thread blocks, executing a two-phase combine that merges partial attention outputs in global memory without requiring expensive atomic updates.

Stabilizing Index Branch Training: Gradient Isolation and Warmup
Training a non-differentiable top-k selection mechanism from scratch poses severe optimization challenges. MSA addresses this by utilizing an auxiliary KL-divergence loss to align the Index Branch’s probability distribution with the attention distribution of the Main Branch. The total objective function is defined as:
where LLM is the primary language modeling loss, λ is a balancing coefficient, and the KL loss at each layer is formulated as:
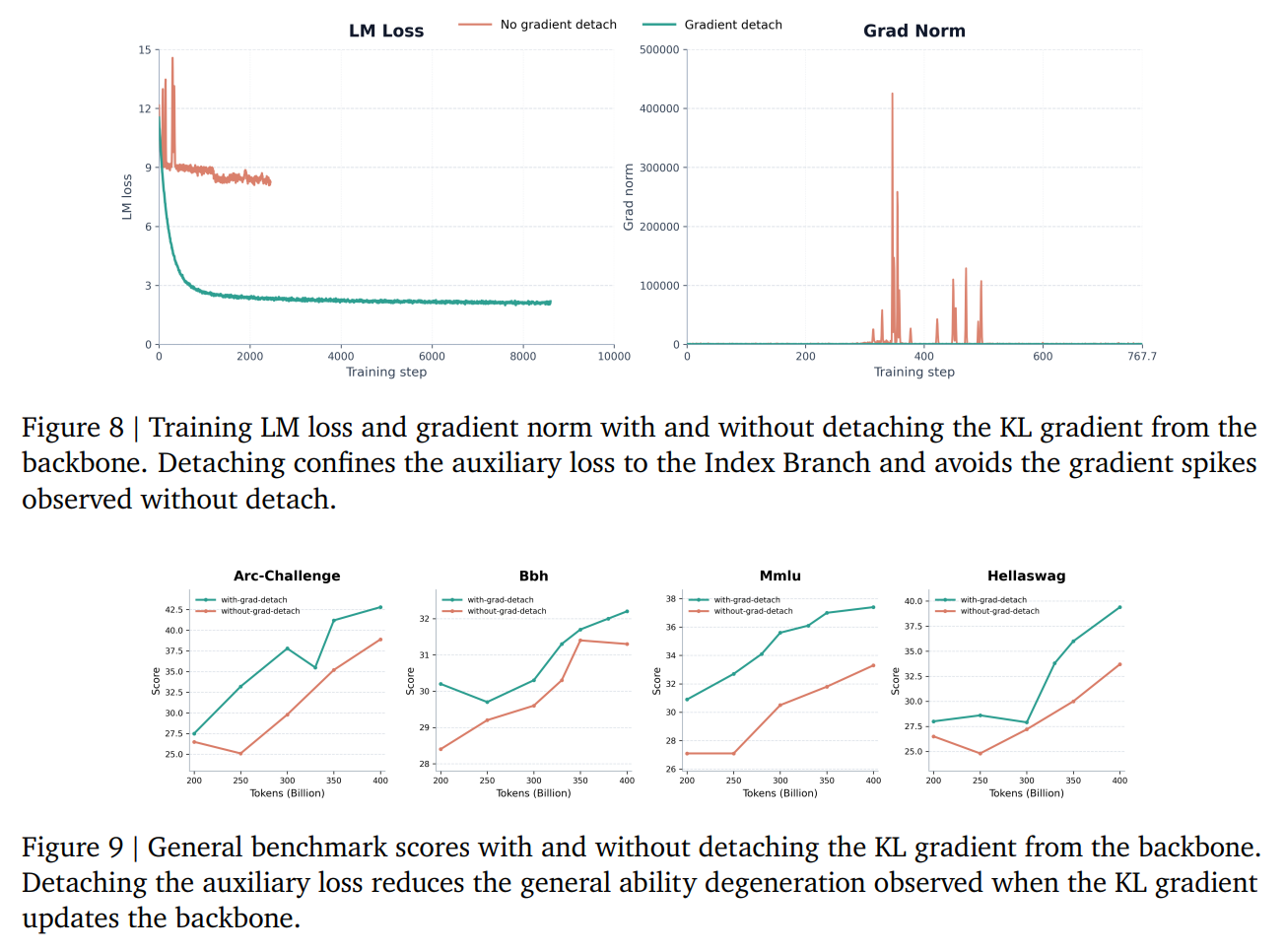
During initial testing, the authors discovered that allowing the KL loss gradients to flow back into the model’s backbone causes extreme gradient-norm spikes and severe degradation on short-context benchmarks. They attribute this to a self-distillation failure mode, where the backbone artificially simplifies the Main Branch attention distribution to minimize the indexing loss. To solve this, MSA implements a strict Gradient Detach strategy:
By detaching the input of the Index Branch from the autograd graph, the auxiliary loss functions as a local supervision signal that updates only the projection parameters Wqidx and Wkidx, leaving the shared backbone untouched. The visual proof of this stabilization is shown in Figure 8 and Figure 9, where detaching the gradient completely eliminates the loss divergence and general performance regression.
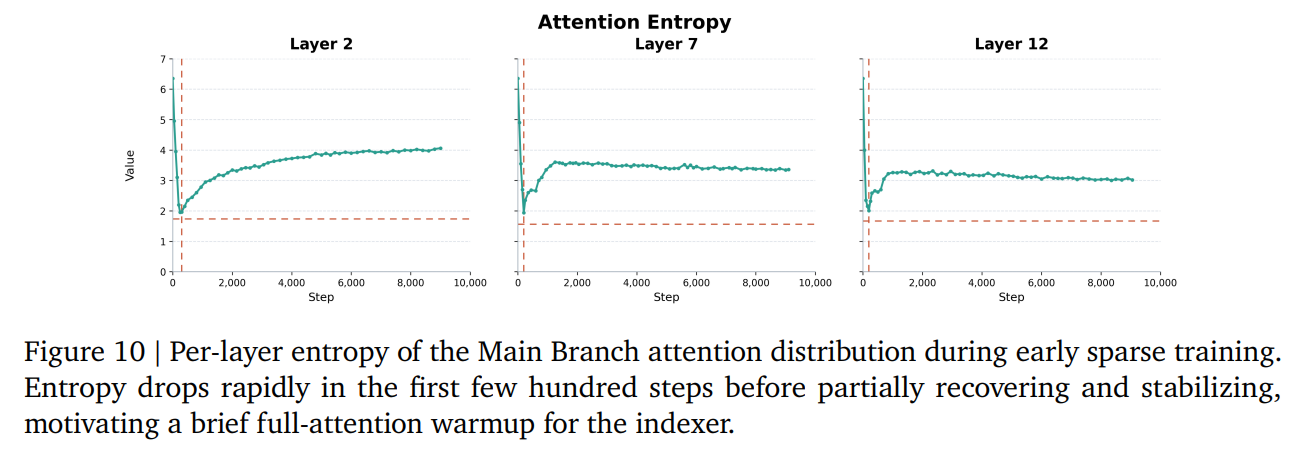
Additionally, MSA uses a two-stage indexer warmup. During the first 40 billion tokens of training, the model runs full attention in both branches to allow the attention patterns to sharpen (Figure 10) before switching to block-sparse attention.
Empirical Validation and Performance Probing
The authors validated MSA on a production-scale 109B parameter Mixture of Experts (MoE) model featuring 41 layers, 64 query heads, and 4 KV heads. They evaluated two primary training routes over a 3-trillion token budget: pretraining from scratch (MSA-PT) and continued pretraining from a full-attention checkpoint (MSA-CPT). As summarized in Table 2, both MSA models remain highly competitive with the Full-Attention GQA baseline across general reasoning, math, coding, and multimodal benchmarks. On MMLU, the Full GQA model scores 67.0, while MSA-PT scores 67.2 and MSA-CPT scores 66.8.
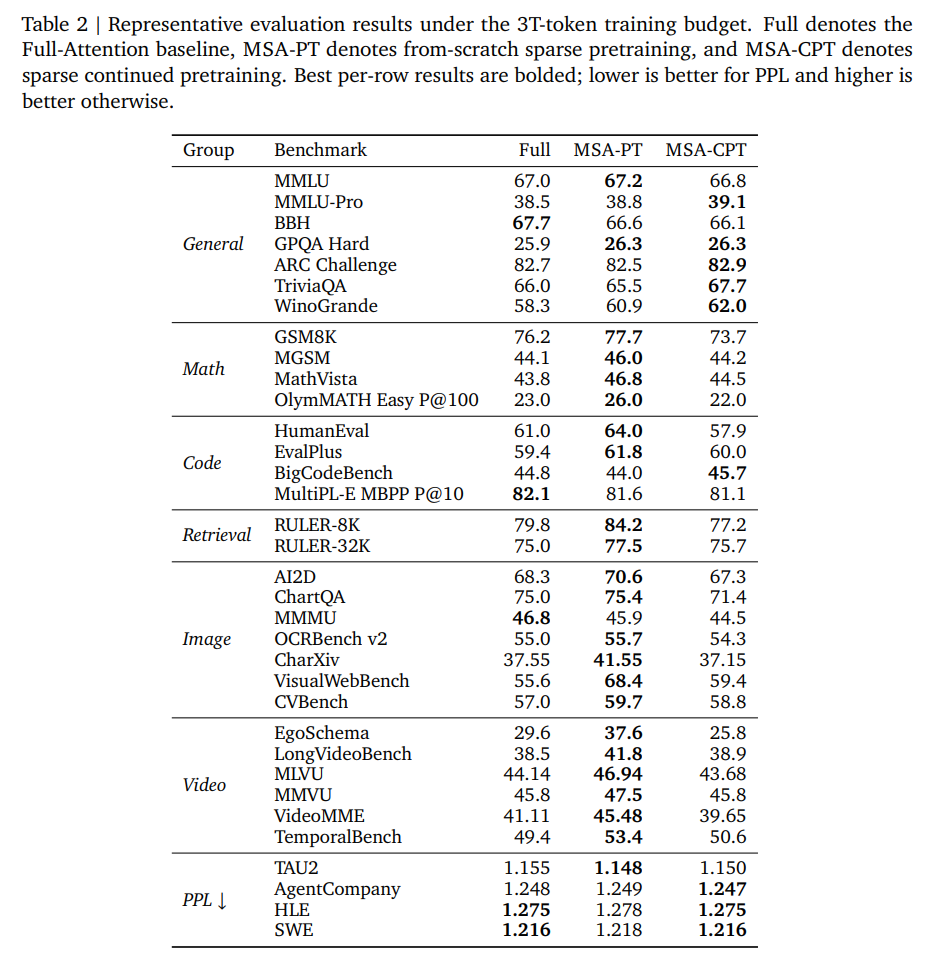
Long-context retrieval evaluations on HELMET-128K and RULER-128K (Table 3) show that MSA-CPT preserves strong retrieval performance under a strict block allocation of k=16.
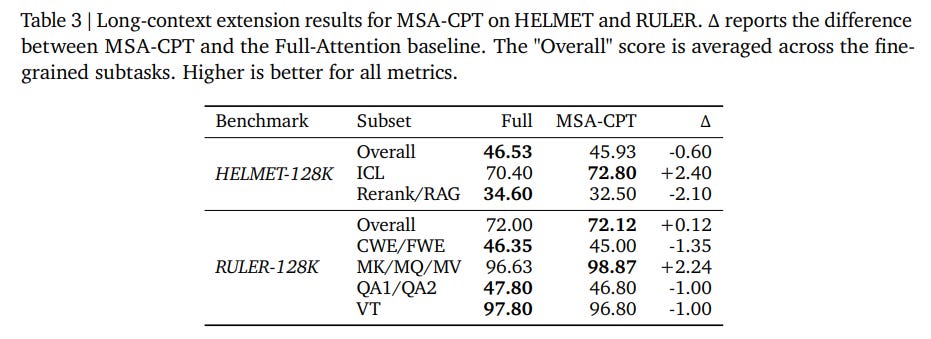
Ablation studies on block sizes (Table 4) confirm that varying the block size Bk from 32 to 128 has a negligible impact on downstream perplexity, demonstrating that larger blocks can be safely utilized to maximize GPU kernel efficiency.
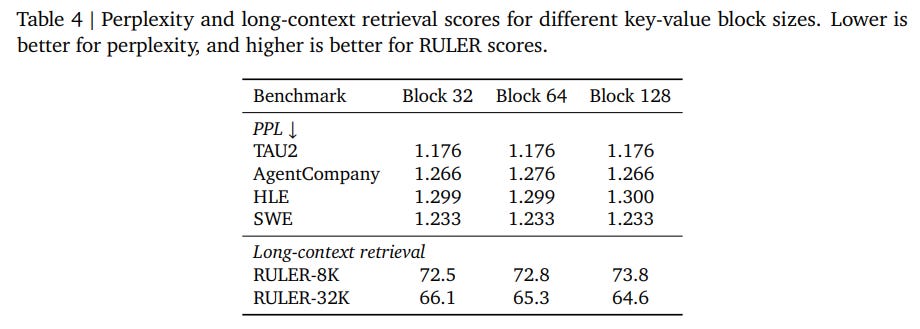
Mechanistic probing of the learned indexer, visualized in Figure 5 and Figure 6, demonstrates that the Index Branch naturally learns to locate the diagonal local context and the initial attention sink tokens.
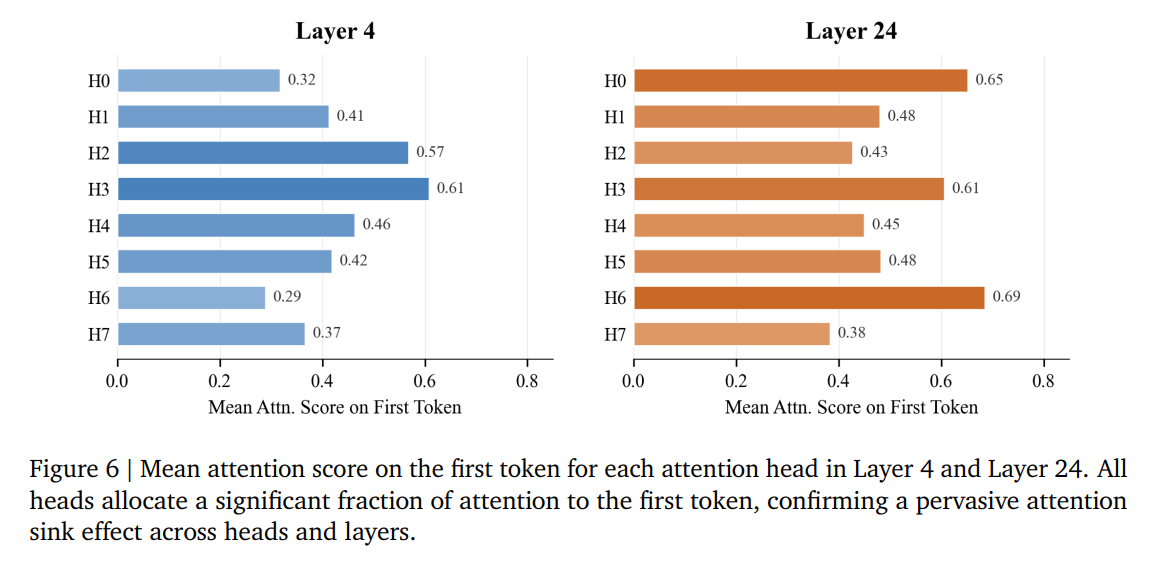
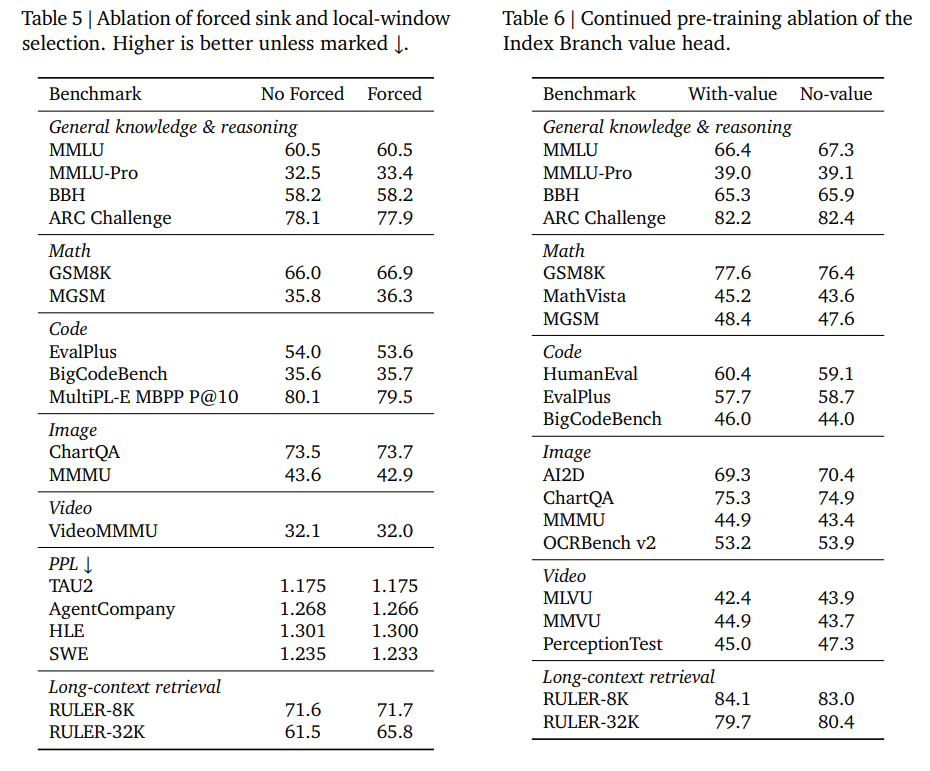
This emergence allows the final design to eliminate hard-coded selection rules (Table 5) and the index value head (Table 6), resulting in a cleaner and more efficient architecture.
Related Paradigms and Architectural Distinctions
MSA occupies a distinct niche in the landscape of long-context attention designs. It maintains exact softmax computation over a dynamically selected support, distinguishing it from linear complexity approximations like Mamba or Gated Delta Networks. Unlike inference-time pruning methods such as H2O or SnapKV, MSA’s indexer is trained end-to-end, which avoids the computational overhead of running full attention during the pretraining phase. When compared to concurrent natively trained sparse methods like NSA or MoBA, MSA is designed to share index decisions across GQA groups rather than relying on per-head routing. This design decision significantly reduces index routing overhead and simplifies memory access, allowing the execution path to utilize contiguous block reads that map efficiently to standard GPU matrix operations.
Limitations and Strategic Outlook
Despite its impressive wall-clock speedups, MSA has a few limitations. First, while the theoretical reduction in attention FLOPs reaches 28.4× at a 1M context length, the actual speedups achieved on H800 GPUs are 14.2× for prefill and 7.6× for decoding. This performance gap is caused by the overhead of index construction, dynamic load balancing, and uncoalesced memory access patterns inherent to sparse operations.
Second, MSA’s rely on a fixed block budget k=16 might struggle on complex tasks that require dense retrieval over a very large percentage of the context. Finally, the deep co-design with specific hardware features, such as NVIDIA’s Tensor Cores and warp-shuffle instructions, means that adapting MSA to alternative accelerator architectures may require substantial kernel rewriting. Looking forward, promising research directions include developing adaptive selection budgets, investigating richer indexing scoring metrics, and expanding the block-sparse architecture to reinforcement learning and agentic post-training scenarios.
