
Multi-Agent Systems are Mixtures of Experts: Who Becomes an Influencer?
Authors: Franka Bause, Jonas Niederle, Martin Pawelczyk, Rebekka Burkholz
Paper: https://arxiv.org/abs/2605.25929
Code: N/A
Model: N/A
TL;DR
WHAT was done? This paper mathematically reframes collaborative multi-agent large language model systems through the lens of social opinion dynamics. The authors demonstrate that when AI agents debate a question, their interaction implicitly implements a task-adaptive Mixture of Experts architecture where influence is dynamically routed to the most confident agents.
WHY it matters? This matters because it provides a rigorous, mathematically grounded explanation for why and when multi-agent AI systems outperform single models. Rather than relying on trial-and-error prompting, developers can now use these mathematical principles to design safer, more effective cooperative AI systems by focusing on how agents calibrate their confidence.

Details
The Discord in the Digital Committee
When we need to solve a complex problem, we often gather a committee of human experts. In the world of artificial intelligence, researchers have tried to replicate this collective intelligence by building multi-agent systems. In these setups, multiple large language models are prompted to behave like different personas—such as a doctor, a mathematician, or a teacher—and iteratively debate their way toward a consensus.
Yet, the empirical benefits of these multi-agent systems compared to single-agent baselines remain frustratingly inconsistent. Sometimes the committee produces a brilliant synthesis; other times, it devolves into a compromised, mediocre average, or worse, lets a loudly confident but incorrect agent hijack the decision. Until now, we lacked a principled mathematical framework to describe how opinions evolve during these digital debates and what determines who gets to be the “influencer.” This paper bridges that gap by connecting the sociology of human networks with the architecture of modern machine learning.
Social Science Meets Machine Learning
To understand the digital committee, the researchers turned to a classic tool from the social sciences: the Friedkin-Johnsen (FJ) model of opinion dynamics. Originally designed to study how human beliefs propagate through social networks, this mathematical framework captures three main forces: an agent’s attachment to its original opinion (stubbornness), its reliance on its own immediately preceding state (belief retention), and its openness to what its peers are saying (peer influence).
The authors realized something profound: when language models deliberate, their parameters are not fixed. An agent might be highly stubborn when answering a question in its apparent area of expertise, but highly suggestible when confronted with a topic it knows little about. Because these conversational parameters shift depending on the specific question being asked, the entire deliberative process behaves exactly like an adaptive Mixture of Experts (MoE) system.
In a traditional machine learning Mixture of Experts, a central mathematical gatekeeper, or router, receives an input and decides which specialized sub-model is best equipped to handle it. In a multi-agent debate, there is no explicit gatekeeper. Instead, the routing is realized implicitly through natural language communication. The debate itself acts as the routing algorithm, dynamically shifting influence toward the agent that is perceived to be the local expert for that specific question. This input-dependent shift in influence is empirically demonstrated in Figure 1, which shows how the deliberation parameters change dramatically from question to question.
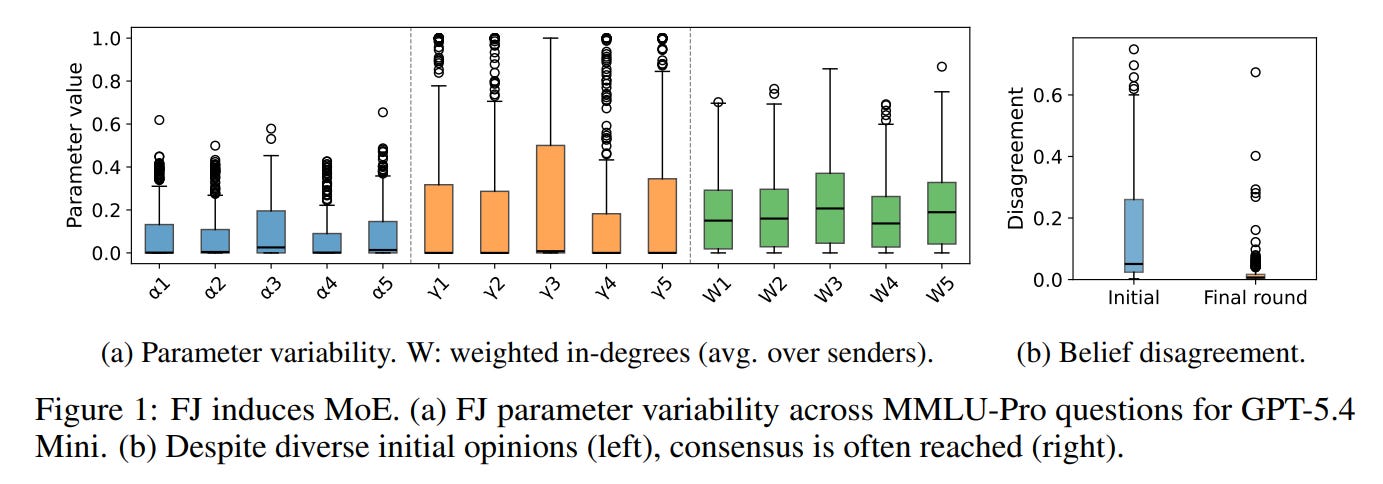
Inside the Chamber of Influence
To see this conversational routing in action, let us trace a single question through a five-agent system, as visualized in the qualitative example in Figure 3. Imagine a committee tasked with solving a tricky science problem. One agent is prompted to be “elaborate,” another “emotional,” another “concise,” and so on. At the beginning of the process, each agent holds an initial belief, which can be thought of as a probability distribution over the possible answers.

The dynamics of how these beliefs update from one turn to the next can be written as a simple balance of forces:
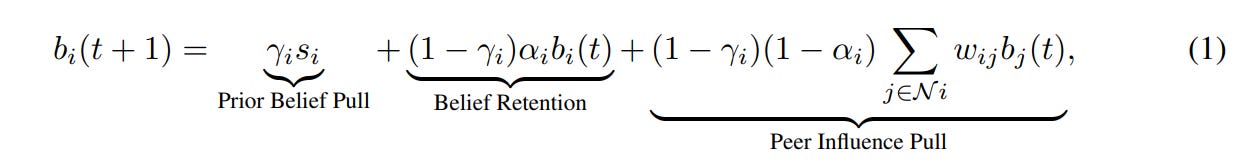
Conceptually, this formula shows that an agent’s updated belief is a combination of its starting belief and the social pull from its peers, mediated by its stubbornness parameter (γi). If an agent’s stubbornness is close to one, it clings tightly to its initial hunch, largely ignoring the conversational peer influence. If its stubbornness is close to zero, it easily drifts toward the group’s average opinion.
In our walkthrough, the “elaborate” agent starts with high confidence in the correct answer, while the other four agents initially agree on an incorrect answer. However, because the elaborate agent is highly confident, its stubbornness parameter is naturally high. Over five rounds of discussion, it holds its ground, explaining its reasoning. The other agents, detecting this relative confidence, lower their own self-retention and allow their beliefs to be pulled toward the elaborate agent’s position. By the final round, the committee reaches a correct consensus. The conversation itself routed the decision-making power to the locally competent expert.
The Math of Persuasion: What the Data Shows
The researchers tested this theory on standard reasoning benchmarks, including the MMLU-Pro dataset and the BBQ bias benchmark, using language models like GPT-5.4 Mini and Qwen2.5-14B-Instruct. They compared the adaptive multi-agent system against two baselines: a simple static average of the models’ initial beliefs, representing the popular Self-Consistency method, and a task-independent ensemble where the influence weights of the agents are fixed and cannot adapt to different questions.
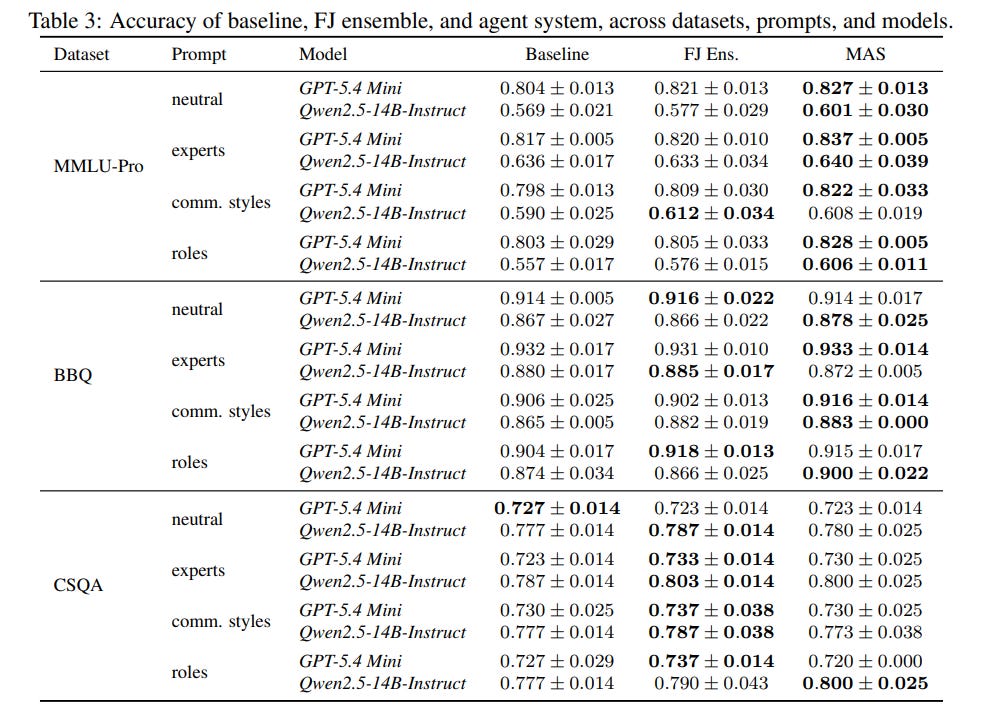
The results, detailed in Table 3, show that the adaptive multi-agent system frequently outperforms both baselines. For example, on MMLU-Pro with GPT-5.4 Mini, the adaptive multi-agent system achieved an accuracy of 0.827 ± 0.013, surpassing the baseline average of 0.804 ± 0.013 and the static ensemble’s 0.821 ± 0.013. Similarly, for Qwen2.5-14B-Instruct on the same benchmark, the multi-agent system boosted accuracy from a baseline of 0.569 ± 0.021 to 0.601 ± 0.030.
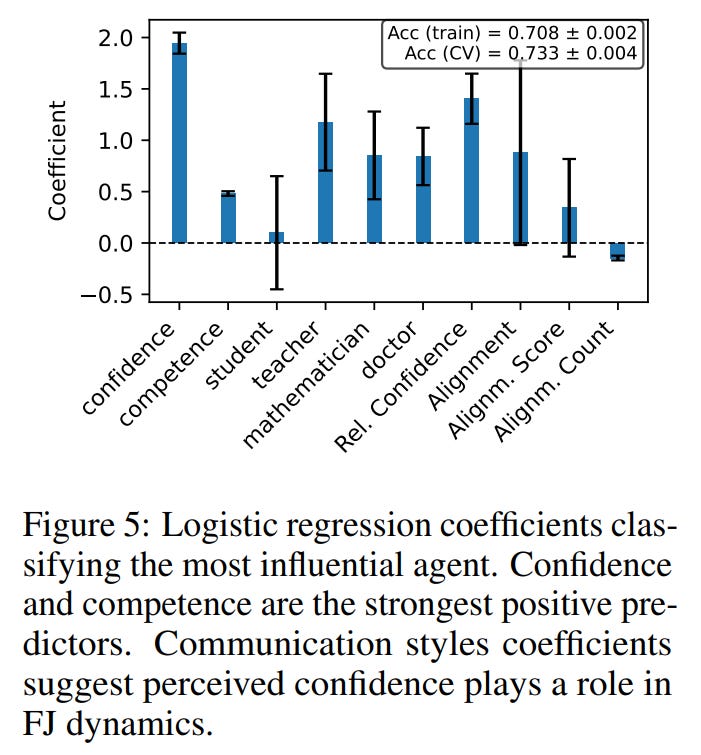
To understand why the agents weighted certain peers more than others, the authors investigated this by training secondary machine learning models to look back and predict which agent would emerge as the most influential. As shown in Figure 5, among the strongest positive predictors of influence was not only the agent’s absolute confidence, but its relative confidence as well—how confident it was compared to the second most confident agent in the room. This social calibration is crucial: an agent’s influence depends entirely on the conversational landscape of its peers.
The Double-Edged Sword of Loud Voices
While this implicit routing is powerful, the authors prove mathematically that it is a double-edged sword. Through their mathematical framework that breaks down performance into distinct factors, they show that a multi-agent system only beats a single expert when the gains from local specialization exceed “routing regret.”
Routing regret is the mathematical price the system pays when it routes decision-making power to the wrong agent. This occurs when an agent exhibits miscalibrated confidence—it is loudly and stubbornly wrong. In these cases, the conversational router fails. Instead of correcting errors, the deliberation process amplifies them, pulling the entire group into a confident but mistaken consensus.
Furthermore, the authors warn against the risk of “shared bias.” If multiple agents suffer from the same underlying bias, they will initially align on the wrong answer. During deliberation, they will mistakenly interpret this alignment as independent corroboration, boosting their confidence and leading the system into an incorrect consensus. This highlights why high group agreement is beneficial only when it reflects genuinely independent, calibrated reasoning.

Designing Smarter Collectives
This research shifts the design of multi-agent AI systems away from trial-and-error prompt engineering toward rigorous system design. Rather than simply trying to make agents as diverse as possible, the mathematical proofs in this paper show that the true key to unlocking collective intelligence is calibration.
If we want multi-agent committees to consistently beat single models, we must design agents that are not just smart, but self-aware. They must be capable of accurately assessing their own limitations and signaling low confidence when they are out of their depth, allowing the conversational routing mechanism to gracefully hand the reigns to a more competent peer. By viewing multi-agent deliberation as a dynamic, emergent routing process over a mixture of experts, AI developers have a new mathematical map to guide the creation of collaborative AI.