
Nested Learning: The Illusion of Deep Learning Architectures
Authors: Ali Behrouz, Meisam Razaviyayn, Peiling Zhong, Vahab Mirrokni
Paper: https://abehrouz.github.io/files/NL.pdf
Blog: https://research.google/blog/introducing-nested-learning-a-new-ml-paradigm-for-continual-learning/
Code: The authors plan to provide data and code via Github after the paper is made publicly available (however, they promised the same for Titans, but haven’t published yet).
TL;DR
WHAT was done? The paper introduces Nested Learning (NL), a new theoretical paradigm that reframes machine learning models and their training procedures as an integrated system of nested, multi-level optimization problems. Each component in this hierarchy operates with its own “context flow”—such as a stream of data samples or gradients—and a distinct update frequency. This “white-box” view reveals that existing deep learning methods learn by compressing context. The authors use this framework to make three core contributions: (1) Deep Optimizers, which reinterprets optimizers like SGD with Momentum as learnable, multi-level memory modules that compress gradients; (2) the Continuum Memory System (CMS), which generalizes long- and short-term memory into a hierarchy of memory blocks updating at different time scales; and (3) HOPE (or Self-Modifying Titans), a new self-modifying sequence architecture that combines these principles and achieves state-of-the-art performance.
WHY it matters? Nested Learning offers a principled, neuro-inspired solution to one of the biggest challenges in AI: the static nature of Large Language Models (LLMs). By moving beyond the “illusion” of simply stacking layers, NL provides a mathematical blueprint for designing models capable of continual learning, self-improvement, and higher-order in-context reasoning. This work transitions AI design from heuristic architecture stacking to the explicit engineering of multi-timescale memory systems. The resulting HOPE architecture demonstrates superior performance over strong baselines like Transformers and its predecessor, Titans, pointing toward a future of more adaptive, efficient, and robust AI systems that can overcome the “amnesia” that plagues current models.

Details
Introduction: Beyond the Illusion of Deep Architectures
For the past decade, progress in AI has been largely synonymous with scaling up deep learning architectures. We stack more layers, add more parameters, and train on more data. Yet, despite their remarkable capabilities, today’s Large Language Models (LLMs) suffer from a fundamental limitation: they are largely static after their pre-training phase. Like a patient with anterograde amnesia, they can leverage past knowledge and adapt within a short-term context window, but they cannot form new, lasting memories or skills.
A new paper from Google Research, “Nested Learning: The Illusion of Deep Learning Architectures,” argues that overcoming this static nature requires more than just scaling; it requires a new paradigm. The authors propose Nested Learning (NL), a framework that recasts deep learning models not as a simple stack of layers, but as a coherent system of nested, multi-level optimization problems. This perspective provides a powerful new lens to understand, unify, and ultimately redesign the core components of AI.
The Core Idea: Nested Learning and Multi-Timescale Updates
The central thesis of Nested Learning is that any machine learning model, from a simple MLP to a complex Transformer, can be represented as a hierarchy of interconnected optimization problems (Figure 2).
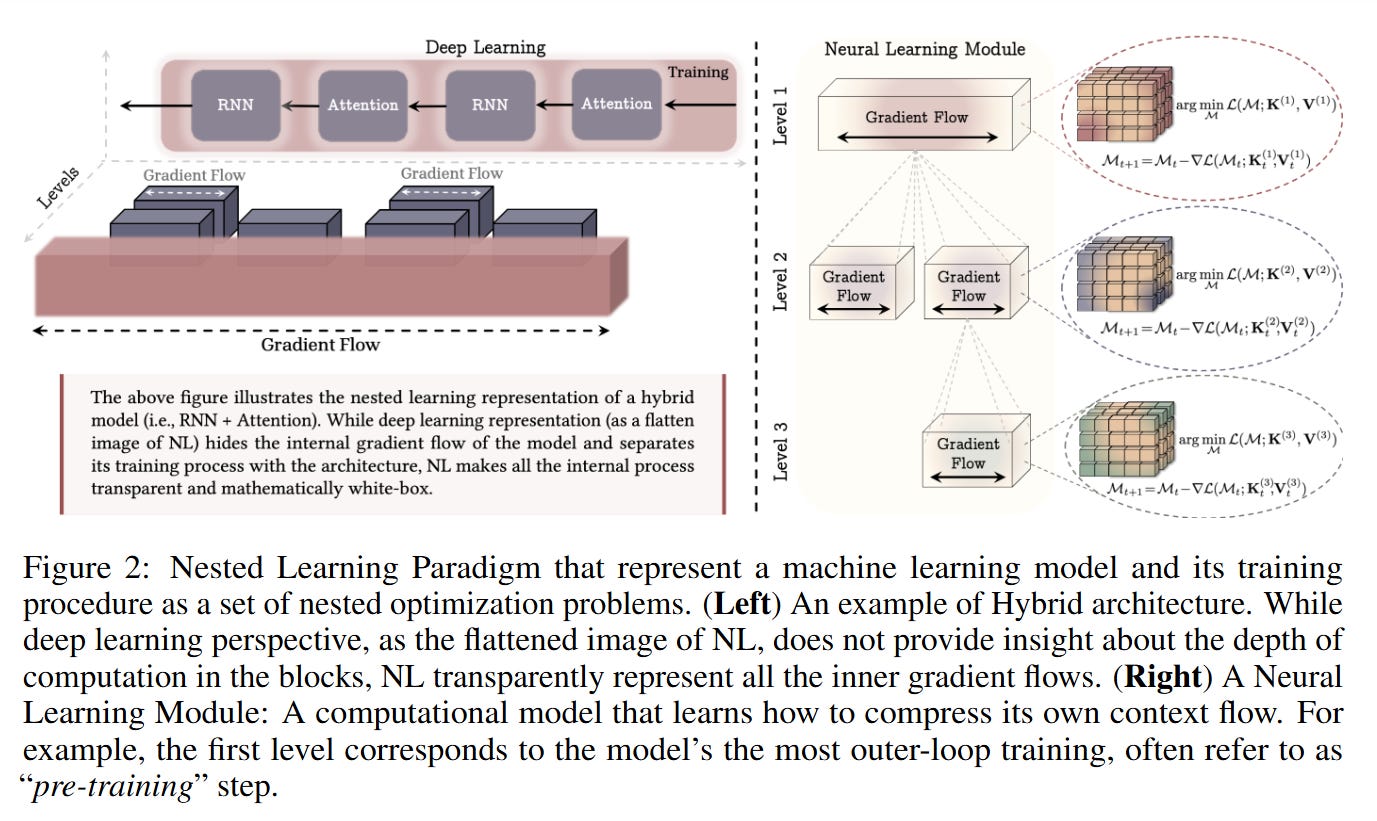
Each component in this hierarchy—be it a memory module, a projection layer, or even an optimizer’s momentum term—is an associative memory system that learns by compressing its own specific “context flow.” This context flow varies depending on the component: for a feed-forward layer, the context is the stream of data samples; for an optimizer’s momentum term, it’s the stream of gradients.
Crucially, this hierarchy is organized by update frequency. Drawing inspiration from the human brain, where different neural circuits operate at different speeds (e.g., delta, theta, gamma waves), NL assigns each component a specific update rate (Figure 1). We touched the history of similar ideas here.

High-frequency components react quickly to immediate data, while low-frequency components integrate information over longer periods. This provides a mathematically transparent, “white-box” view that makes the internal dynamics of learning explicit. Unlike the conventional view of a model as a static graph where gradients flow only during a separate “training” phase, NL represents the model and its training as a single, dynamic system where learning happens at multiple levels and speeds, even during inference.
From Theory to Practice: Three Key Innovations
The NL paradigm isn’t just a theoretical exercise; it yields concrete tools for building better models. The paper highlights three core contributions stemming from this new perspective.
1. Deep Optimizers: When the Optimizer Becomes the Model
Perhaps the most surprising insight from NL is its reinterpretation of standard optimization algorithms. The paper shows that gradient descent with momentum is not a simple update rule but a two-level nested optimization process. The momentum term itself is an associative memory module that learns to compress the history of gradients. Formally, the update for momentum, mₜ₊₁, can be seen as the solution to its own inner optimization problem:
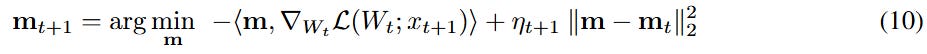
This reveals that momentum is a simple, linear memory. The logical next step is to make it more powerful. The authors propose Deep Momentum Gradient Descent (DMGD), where this linear memory is replaced by a multi-layer perceptron (MLP).
The optimizer itself becomes a deep learning model, capable of learning complex, non-linear dynamics of the loss landscape.
2. Continuum Memory System (CMS): A Spectrum of Memory
NL challenges the rigid dichotomy of “short-term memory” (like attention) and “long-term memory” (like FFN weights). Instead, it proposes a Continuum Memory System (CMS), a chain of MLP blocks, each operating at a different frequency. The parameters of the 𝑙-th block, θ⁽ᶠˡ⁾, are updated only once every C⁽ˡ⁾ steps:
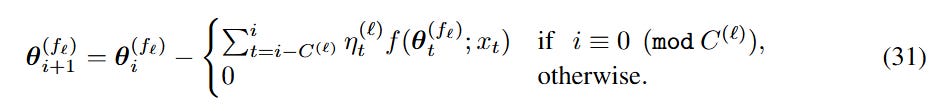
This structure allows the model to store and process information at multiple levels of temporal abstraction simultaneously, providing a more robust mechanism for continual learning and memory consolidation. The conventional Transformer block is simply a special case of this system where there is only one memory frequency.
3. HOPE: A Self-Modifying Architecture
The culmination of these ideas is HOPE, a new sequence architecture that combines a self-modifying mechanism with the Continuum Memory System. This “self-modifying” property means the model learns its own update rules, allowing it to adapt its learning process in response to the data it sees at test time. HOPE is explicitly designed with different frequency levels for its components (Figure 3), allowing it to dynamically manage its memory and even learn its own update rules in response to the data.
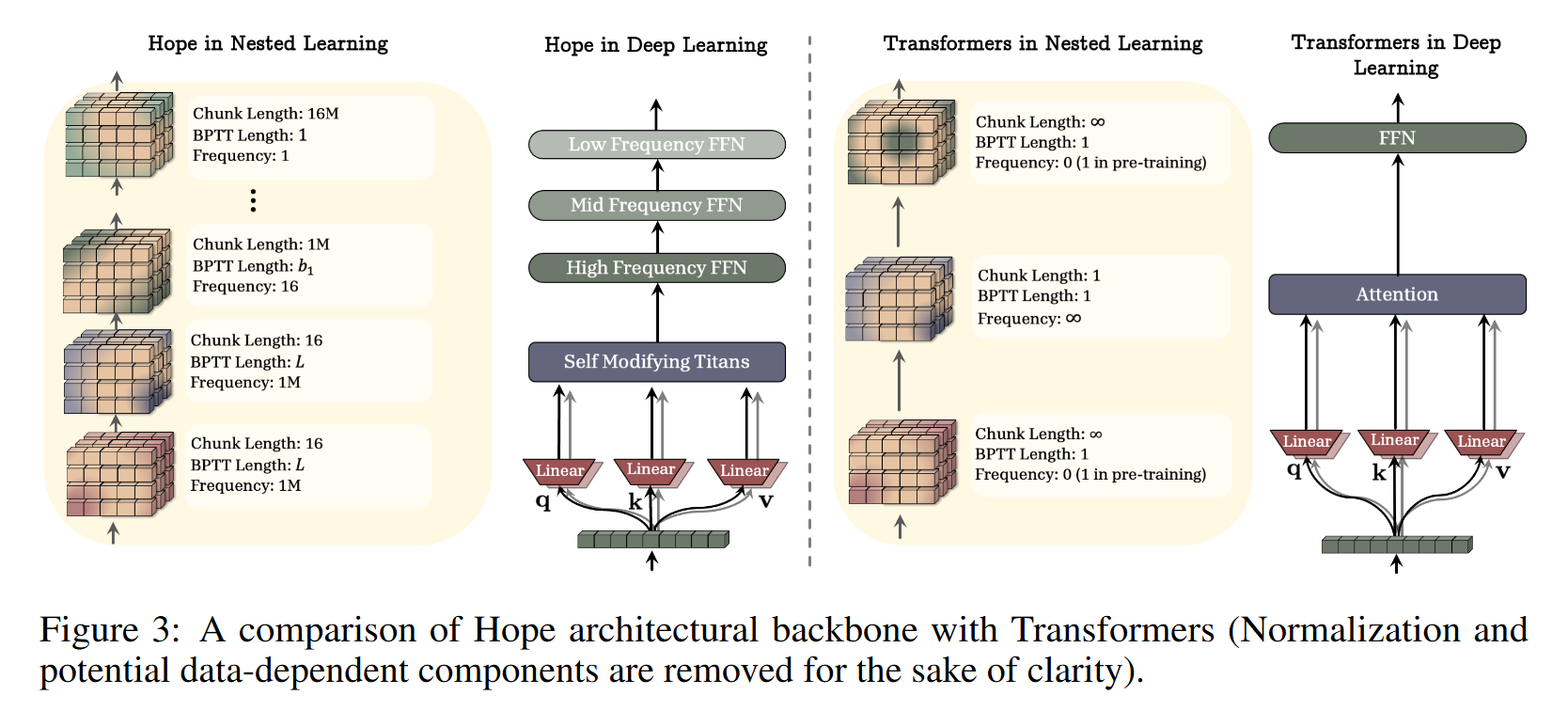
From Titans to a Unified Theory
This work is a direct and significant evolution of the authors’ previous paper on the Titans architecture. While Titans introduced the groundbreaking concept of a neural memory module that learns to update itself at test time, Nested Learning provides the overarching theoretical framework that explains why such systems are effective and how to generalize them.

The key evolution is the move from a single specialized Long-Term Memory Module in Titans to the multi-level Continuum Memory System (CMS) in HOPE. Furthermore, NL goes a step beyond by applying its principles to the optimizer itself, leading to the concept of Deep Optimizers. In essence, Titans was an innovative proof-of-concept; Nested Learning is the unifying theory that formalizes, expands, and generalizes its principles, creating a common language to describe everything from optimizers to memory layers.
Experimental Validation
The HOPE architecture, built on NL principles, demonstrates impressive empirical results. In extensive comparisons on language modeling and common-sense reasoning tasks, HOPE consistently outperforms strong baselines, including Transformer++, RetNet, DeltaNet, and even its direct predecessor, Titans (Table 1).
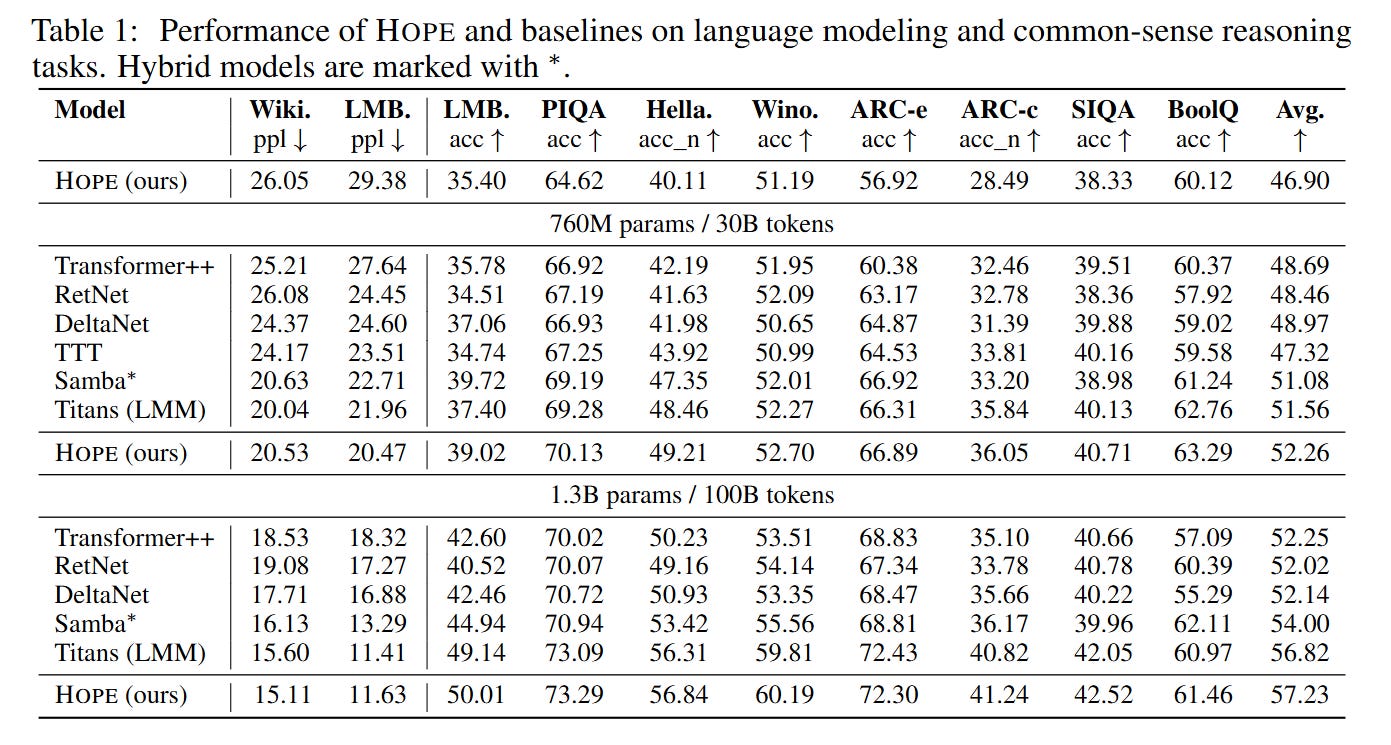
At the 1.3B parameter scale, HOPE achieves the highest average accuracy (57.23%) on reasoning tasks and the lowest perplexity on the Wiki benchmark (15.11). This confirms that dynamically changing key-value projections and employing a deep, multi-frequency memory system leads to superior performance.
Limitations and Future Outlook
The authors are transparent about the paper’s limitations, noting that its condensed format moves many experimental details to an appendix. The primary unspoken challenge for this line of research will be managing the computational complexity of nested, multi-frequency updates as models scale to hundreds of billions of parameters.
However, the future directions unlocked by NL are vast. The framework provides a clear path for designing models with more “levels” of nested optimization to achieve higher-order reasoning, developing more sophisticated Deep Optimizers, and rigorously benchmarking continual learning in large-scale settings.
Conclusion
“Nested Learning” is more than just another paper with a new architecture; it is a conceptual reset. By revealing the “illusion” of traditional deep learning architectures, it offers a more fundamental, mathematically grounded, and neuro-inspired paradigm (another recent neuro-inspired paradigm was the HRM). The work provides a powerful toolkit for designing the next generation of AI systems—ones that can learn continuously, manage memory across time scales, and perhaps finally overcome the static limitations that hold back today’s models. This paper presents a compelling blueprint for a future where AI systems don’t just know, but actively learn.