
[NeurIPS 2025] Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free
NeurIPS 2025 Best Paper Award
Authors: Zihan Qiu, Zekun Wang, Bo Zheng, Zeyu Huang, Kaiyue Wen, Songlin Yang, Rui Men, Le Yu, Fei Huang, Suozhi Huang, Dayiheng Liu, Jingren Zhou, Junyang Lin (Qwen Team)
Paper: https://arxiv.org/abs/2505.06708, NeurIPS submission
Code: https://github.com/qiuzh20/gated_attention
Model: https://huggingface.co/collections/Qwen/qwen3-next
Visual TL;DR

TL;DR
WHAT was done? The authors introduce Gated Attention, a mechanism that applies a learnable, input-dependent sigmoid gate immediately after the Scaled Dot-Product Attention (SDPA) output. By modulating the attention output Y with a gate σ(XWθ), the method introduces element-wise sparsity and non-linearity before the final output projection.
WHY it matters? This simple architectural modification yields profound stability improvements for large-scale training (eliminating loss spikes) and consistently improves perplexity on 15B MoE and 1.7B dense models. Crucially, it mechanistically eliminates the “Attention Sink” phenomenon and “Massive Activations” without requiring heuristic fixes like “sink tokens,” thereby significantly improving long-context extrapolation.

Details
The Linearity Bottleneck and Stability Traps
The standard Transformer architecture, despite its dominance, suffers from specific theoretical and practical limitations that become acute at scale. A core theoretical bottleneck lies in the linearity between the Value projection (WV) and the Output projection (WO). In a standard attention head, the operation is essentially a linear composition XWV⋅AttentionMatrix⋅WO. Because both projections are linear, they can be conceptually merged into a single low-rank mapping, limiting the expressiveness of the attention block.
Practically, this manifests as training instability in large-scale models, particularly Mixture-of-Experts (MoE), which are prone to severe loss spikes. Furthermore, standard Softmax attention forces a probability sum of 1.0, leading to the “Attention Sink” phenomenon where models dump unnecessary attention mass onto the first token (or “sink tokens”) simply to satisfy the Softmax constraint when no relevant information exists in the context. Previous attempts to fix this, such as StreamingLLM, relied on manual heuristics. The authors of this paper propose that a learnable gating mechanism naturally resolves these issues by decoupling the routing of information from the modulation of its magnitude.
Gated Attention First Principles: The Mechanism
To understand the contribution, we must define the atomic units of the modified attention layer. In standard Multi-Head Attention (MHA), the output Y is a linear combination of values weighted by the attention scores. The authors introduce a modulation gate that operates on the hidden states X (the input to the layer, post-normalization).
The core update rule for the Gated Attention output Y′ is defined as:
Y′=Y ⊙ σ(XWθ).
Here, Y∈Rn×d is the output of the SDPA, ⊙ represents element-wise multiplication, and σ is the sigmoid activation function. The term XWθ represents a learnable linear projection of the input X into a gating score. While the authors experimented with various positions (gating Values, Keys, or the final Dense output), they identified that element-wise, head-specific gating applied specifically to the SDPA output yields the optimal balance of performance and parameter efficiency.
From Input to Gated Output
Consider a concrete example of how a single token, say the word “Apple” in a sentence, flows through this mechanism. In standard attention, “Apple” (Xapple) queries the sequence and retrieves a context vector Ycontext (perhaps related to “pie” or “fruit”). Even if the retrieved context is noisy or irrelevant, standard attention passes this vector forward, potentially amplified by the subsequent Feed-Forward Network (FFN).
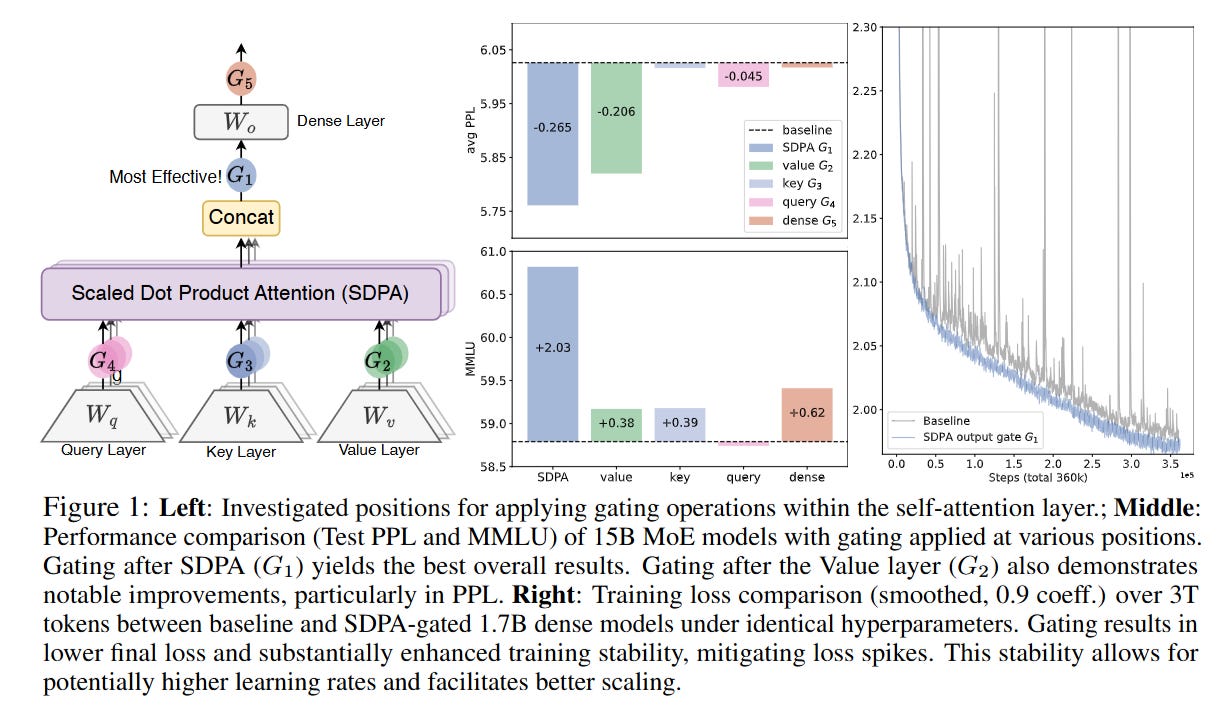
In the Gated Attention regime shown in Figure 1, the system performs a parallel check. While the attention mechanism computes Ycontext, the gating projection Wθ independently analyzes the original representation Xapple to determine how much of the attention output should be preserved. If the gate computes a score vector near 0, it suppresses the attention output effectively to zero. This acts as a non-linear filter: even if Softmax forces the attention weights to sum to 1.0 (finding a “sink”), the gate can simply multiply that “sink” output by zero, effectively allowing the head to output “nothing.” This capability introduces a multiplicative interaction that standard Transformers lack (see also this).
Training Stability and Scale
From an engineering perspective, the impact of this gate on training dynamics is substantial. Validated on 1.7B dense models and 15B MoE models trained on up to 3.5 trillion tokens, the authors demonstrate that Gated Attention significantly stabilizes the optimization landscape.
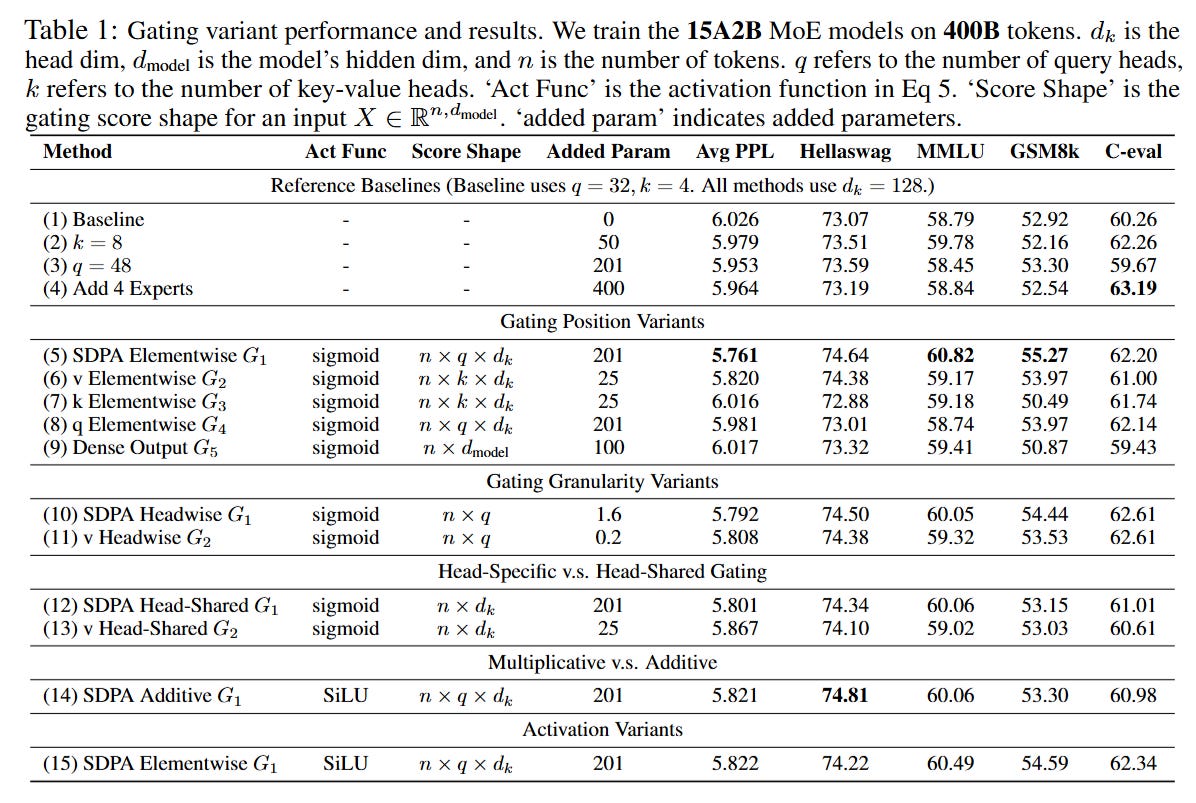
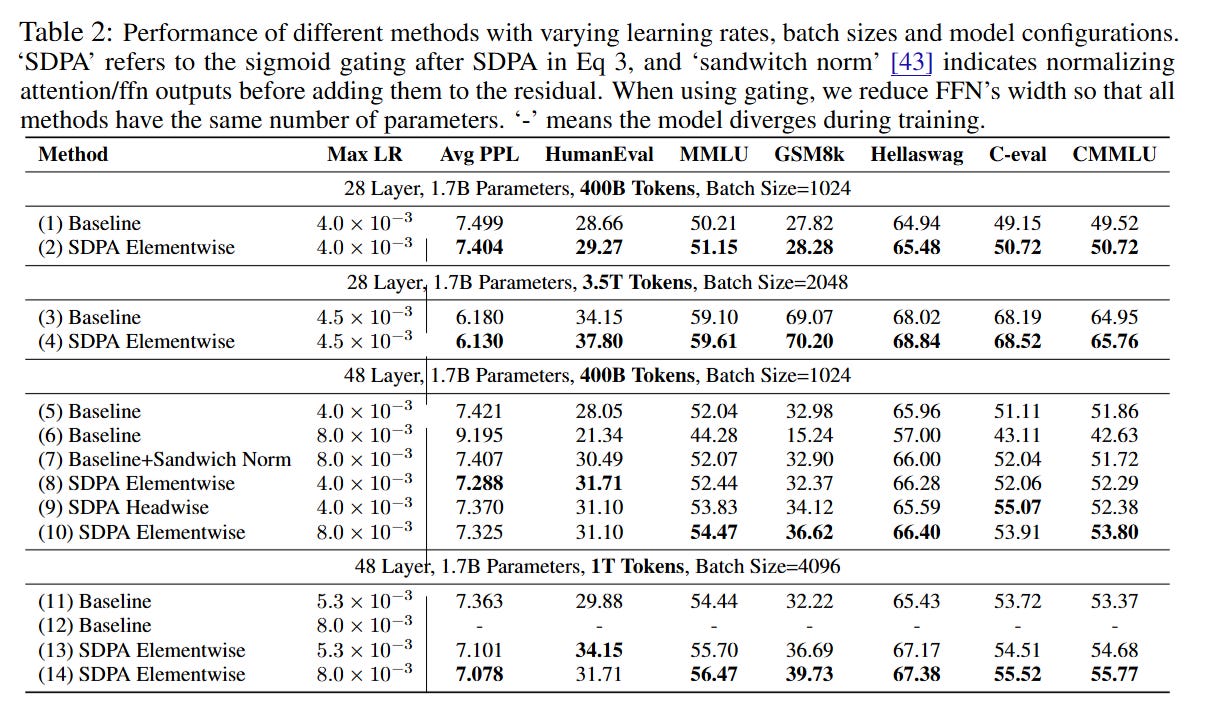
As illustrated in the loss curves (Figure 1, Right), baseline models frequently suffer from loss spikes—sudden divergences that require restarting training or rolling back checkpoints. The Gated Attention models exhibit smooth convergence curves. This stability allows for the use of larger learning rates (e.g., increasing max LR from 4.0×10−3 to 4.5×10−3), which in turn facilitates faster convergence and better final scaling laws. The computational overhead is negligible (less than 2% wall-time latency) because the gating operation introduces minimal FLOPs compared to the quadratic cost of attention or the massive matrices of the FFN.
Analysis: The Death of the Attention Sink
The most compelling insight of the paper is mechanistic: why does this work? The authors utilize probing to reveal that Gated Attention naturally eliminates the “Attention Sink” and “Massive Activation” phenomena identified in prior work like Massive Activations.
In standard models, specific channels in the hidden states accumulate massive values (outliers), and the model attends heavily to the first token to manage the Softmax distribution. The authors show in Figure 2 that while baselines allocate ~46.7% of attention to the first token, Gated Attention models reduce this to ~4.8%.
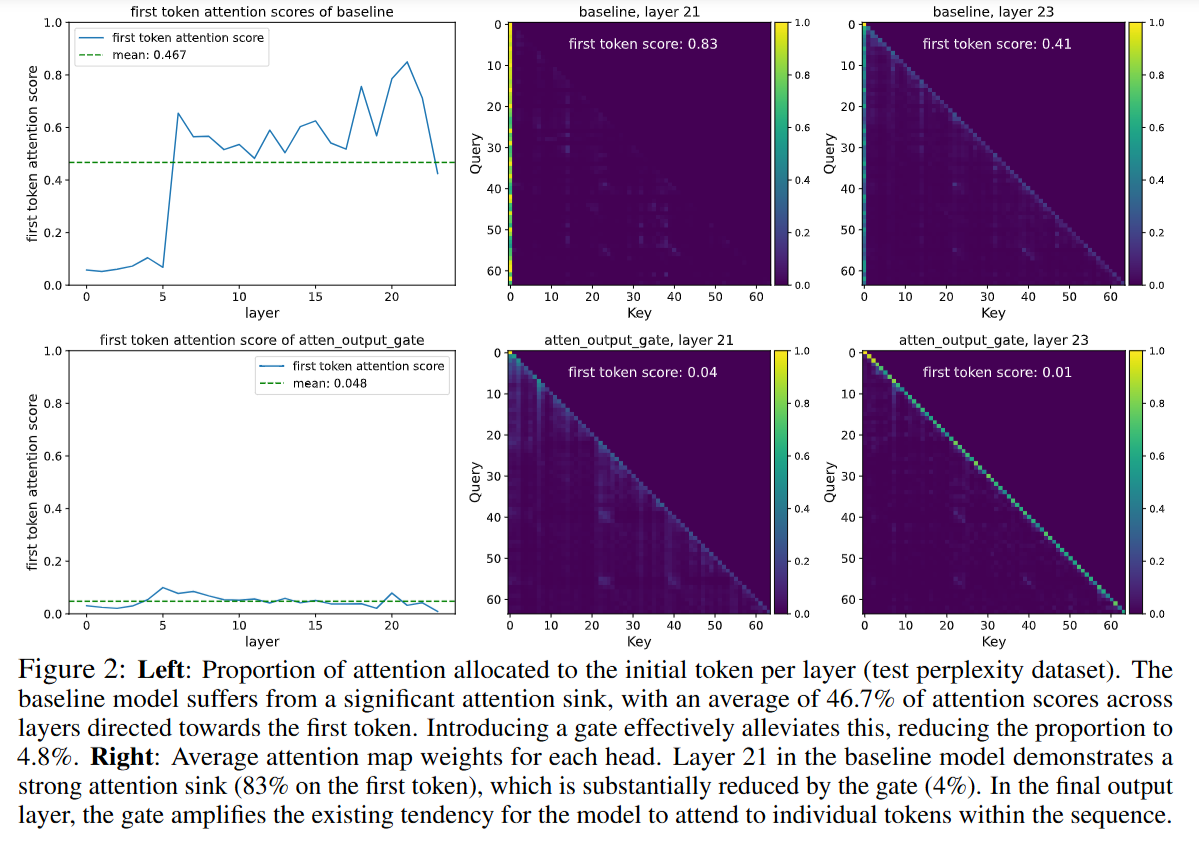
The mechanism works via Input-Dependent Sparsity. The sigmoid gate frequently saturates near zero, creating a sparse mask over the value vectors. This allows the model to “reject” the output of the attention mechanism when it is uninformative. Consequently, the model no longer relies on the first token as a “trash can” for probability mass. This sparsity also prevents the propagation of massive activation outliers through the residual stream, which is the root cause of the numerical instabilities (loss spikes) observed in BF16 training.
Limitations
While the results are robust, the paper primarily relies on empirical validation rather than a rigorous theoretical proof connecting non-linearity to length generalization. The authors note that while Gated Attention aids in context extension (extrapolating from 32k to 128k length using YaRN), there is a performance degradation, albeit smaller than in baselines. Additionally, this is an architectural modification, meaning it cannot be retroactively applied to existing checkpoints (like LLaMA-3) without continued pre-training or fine-tuning that accommodates the new parameters.
Impact & Conclusion
The authors present a convincing case that the “Attention Sink” is an artifact of insufficient architectural expressivity—specifically, the inability of the attention head to output a zero vector due to Softmax normalization. By restoring this capability via Gated Attention, the Qwen Team has engineered a solution that solves three problems at once: training stability, representation sparsity, and attention pathology.
This method is already integrated into the Qwen3-Next architectures, signaling its viability for frontier models. For researchers designing next-generation architectures, this paper underscores the necessity of non-linear modulation within the mixing layers, suggesting that the era of purely linear value pathways in Transformers may be ending.