
On the Fundamental Limits of LLMs at Scale
Authors: Muhammad Ahmed Mohsin, Muhammad Umer, Ahsan Bilal, Zeeshan Memon, Muhammad Ibtsaam Qadir, Sagnik Bhattacharya, Hassan Rizwan, Abhiram R. Gorle, Maahe Zehra Kazmi, Ayesha Mohsin, Muhammad Usman Rafique, Zihao He, Pulkit Mehta, Muhammad Ali Jamshed, John M. Cioffi
Paper: https://arxiv.org/abs/2511.12869
TL;DR
WHAT was done? The authors present a unified theoretical framework identifying five immutable boundaries to Large Language Model (LLM) scaling: hallucination, context compression, reasoning degradation, retrieval fragility, and multimodal misalignment. By synthesizing proofs from computability theory, information theory, and statistical learning, they demonstrate that these failure modes are not merely transient data artifacts but intrinsic properties of the transformer architecture and the next-token prediction objective.
WHY it matters? This work challenges the prevailing “scale is all you need” orthodoxy by mathematically proving that specific error classes—such as those arising from undecidable problems or long-tail distribution estimation—cannot be resolved simply by adding parameters or compute. It suggests that achieving reliability requires architectural paradigm shifts, such as neuro-symbolic integration or bounded-oracle retrieval, rather than just larger models.
Details
The Theoretical Ceiling of Scale
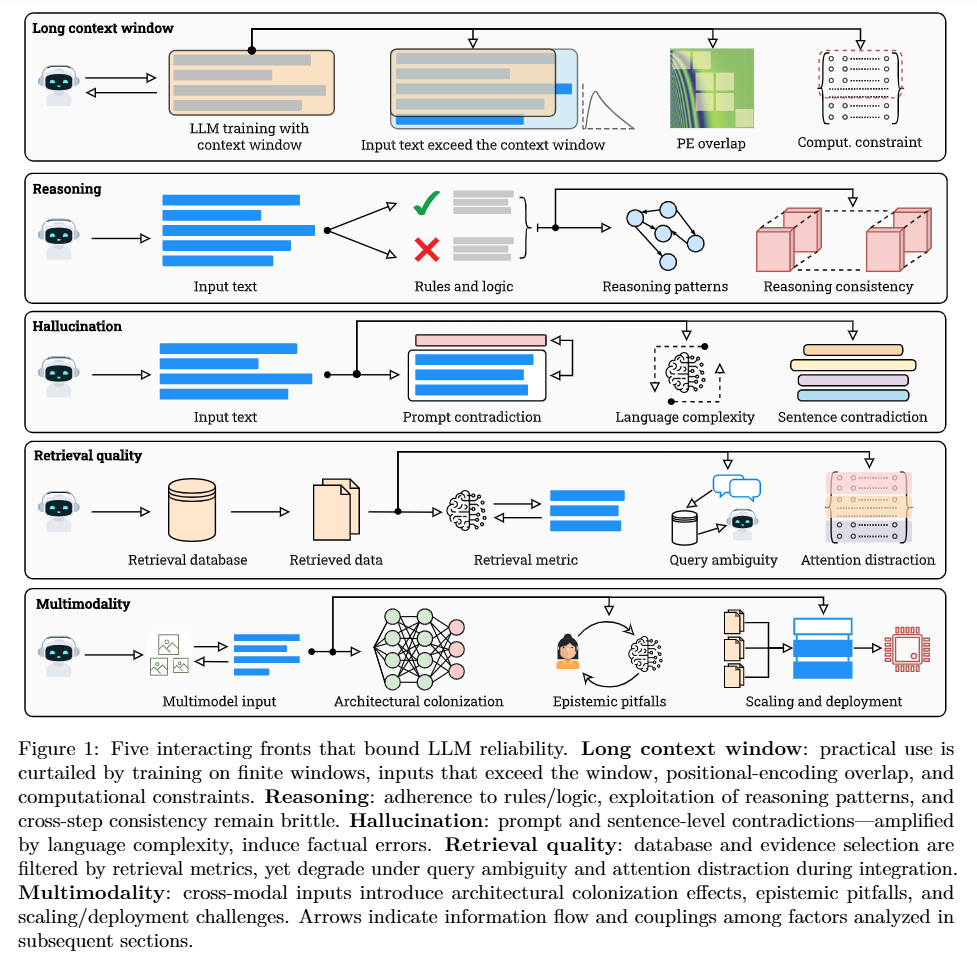
The dominant narrative in current AI research suggests that sufficient scaling of parameters, data, and compute will eventually reduce error rates to zero. Mohsin et al. counter this by framing LLM limitations not as engineering hurdles, but as mathematical certainties derived from the foundational limits of computation and information. They categorize these limits into a “triad of impossibility”: computational undecidability, statistical sample insufficiency, and finite information capacity. As illustrated in Figure 1, these theoretical roots branch into five distinct practical failures—ranging from hallucination to multimodal misalignment. The authors argue that while scaling improves performance on the “decidable” and “head” of the data distribution, it asymptotically saturates against these hard theoretical walls. This represents a significant shift from empirical scaling laws to a proof-based understanding of where deep learning must inevitably fail.
The Inevitability of Hallucination
Keep reading with a 7-day free trial
Subscribe to ArXivIQ to keep reading this post and get 7 days of free access to the full post archives.