Authors: Michael Psenka, Michael Rabbat, Aditi Krishnapriyan, Yann LeCun, Amir Bar
Paper: https://arxiv.org/abs/2602.00475
Code: https://www.michaelpsenka.io/grasp/
Affiliation: Meta FAIR, UC Berkeley, NYU
TL;DR
WHAT was done? The authors introduce GRASP (Gradient RelAxed Stochastic Planner), a parallelized planning algorithm designed specifically for learned world models. Instead of rolling out trajectories sequentially (shooting methods), GRASP treats future states as independent optimization variables (”lifted” states) and optimizes them in parallel using gradient descent. Crucially, it incorporates Langevin dynamics for exploration and a specific stop-gradient mechanism to handle the unstable geometry of learned latent spaces.
WHY it matters? This work appears to be the “reasoning engine” counterpart to Yann LeCun’s Joint Embedding Predictive Architecture (JEPA). While recent work has focused on training world models (V-JEPA, I-JEPA — see review here), effective planning within those non-Euclidean latent spaces has remained brittle due to exploding gradients and local minima. GRASP solves this by decoupling temporal dependencies, offering a robust way to perform long-horizon control in the high-dimensional latent spaces envisioned by the “Autonomous Machine Intelligence” roadmap.

Details
The Inference Gap in World Models
The field has reached a consensus that intelligent agents require world models—internal simulations of external reality. Architectures like the Joint Embedding Predictive Architecture have successfully demonstrated that we can learn abstract representations of the world and predict future states without reconstructing pixels. However, a critical bottleneck remains: Inference. Having a model st+1=Fθ(st,at) is useless if we cannot efficiently find a sequence of actions a0:T that reaches a goal.
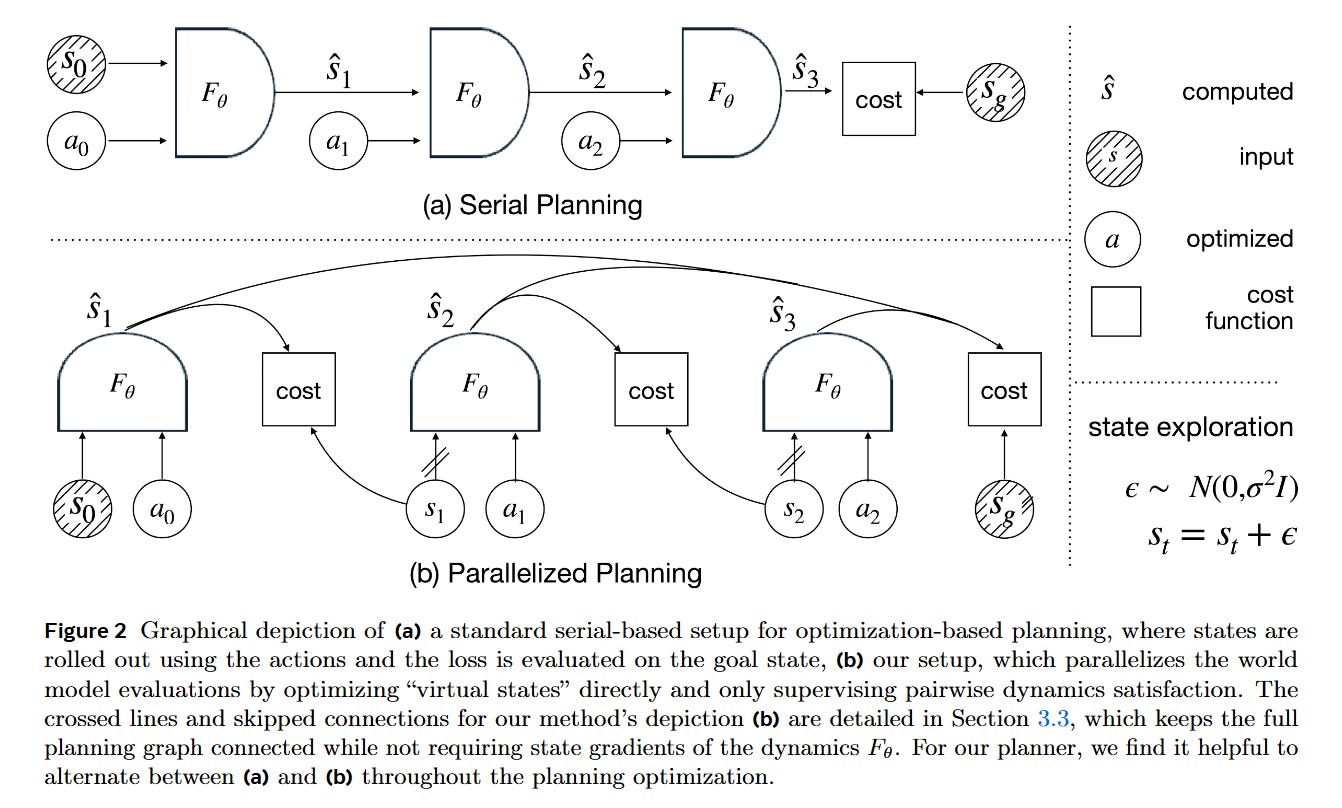
Standard approaches fall into two traps. Zero-order methods like the Cross-Entropy Method (CEM) are robust but computationally wasteful in high dimensions, ignoring the rich gradient information provided by differentiable world models. Conversely, naive gradient-based planning (shooting) attempts to backpropagate through time (BPTT) across long horizons. As the paper highlights, differentiating through a deep neural network composed T times results in chaotic loss landscapes, vanishing gradients, and convergence to poor local minima. GRASP addresses this delta by abandoning the sequential rollout during optimization, instead adopting a “lifted” approach that aligns perfectly with the constraints of learned representations.
First Principles: The Lifted Latent State
To understand GRASP, one must first understand “Lifted Planning” (or collocation). In a standard rollout, the state st is a function of all previous actions. In lifted planning, the intermediate states s1,…,sT are treated as atomic decision variables initialized arbitrarily (e.g., a straight line interpolation between start and goal).
The core mathematical object changes from an unconstrained optimization of actions to a constrained optimization of “virtual states.” The system creates a physics defect constraint. If Fθ is the world model, we aim to minimize the dynamics violation:
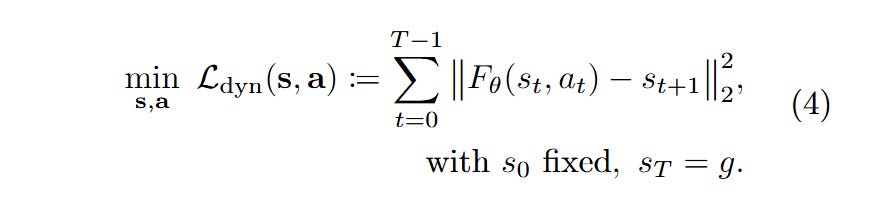
By relaxing the strict equality constraint st+1=Fθ(st,at) into a penalty, the planner can “teleport” through the state space during the early phases of optimization, finding physically valid trajectories that satisfy the dynamics only at convergence. This transforms a deep, sequential computation graph into a shallow, parallel one.