Pretraining Recurrent Networks without Recurrence
Authors: Akarsh Kumar, Phillip Isola (MIT)
Paper: https://arxiv.org/abs/2606.06479
Code: https://github.com/akarshkumar0101/smt
Model: N/A
TL;DR
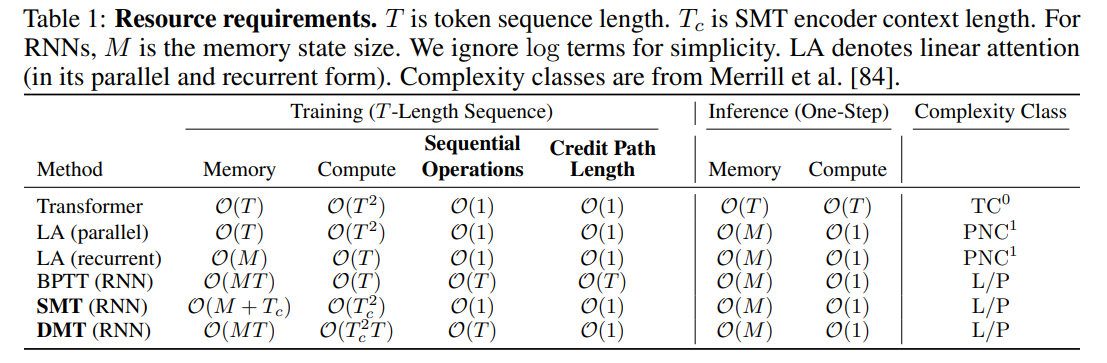
WHAT was done? The authors introduce Supervised Memory Training (SMT) and DAgger Memory Training (DMT), a two-stage paradigm for pretraining nonlinear recurrent neural networks (RNNs) without using standard backpropagation through time (BPTT). SMT uses a Transformer-based teacher to compress the past sequence into predictive state targets, converting sequence-to-sequence training into a series of time-parallelized, one-step supervised learning updates.
WHY it matters? Standard RNN training has long been bottlenecked by the sequential dependencies and unstable O(T) gradient paths of BPTT. By decoupling representational learning (what to remember) from transition dynamics (how to update memory), SMT establishes a stable O(1) gradient path and full time-parallelizability during pretraining, while preserving the O(1) inference-time memory scaling and maximal expressivity of nonlinear RNNs.
Executive Summary: For AI research leaders and sequence modeling architects, SMT provides a practical bridge between the parallelizable training of Transformers and the highly efficient, fixed-memory inference of recurrent networks. By reframing sequence processing as a parallel set-prediction task, it allows developers to pretrain highly expressive nonlinear recurrent architectures on long sequences without experiencing vanishing or exploding gradients.

Details
The Credit Assignment Bottleneck in Recurrent Architectures
In sequence modeling, researchers face a strict trade-off between parallel training efficiency and fixed-resource inference. Recurrent neural networks (RNNs) are theoretically optimal for deployment due to their O(1) inference compute and memory footprint, but training them via standard BPTT requires sequentially unrolling the network over time. This sequential dependency creates a gradient credit assignment path of length O(T), where repeated multiplication of the transition Jacobian leads to vanishing or exploding gradients and a severe recency bias. State Space Models such as Mamba and S4 achieve time-parallel training via associative scans, yet their reliance on strictly linear transition functions limits their representational expressivity. Conversely, Transformers allow highly parallelized training but scale quadratically in compute and linearly in memory during inference, making them unsustainable for continuous, long-horizon sequence tasks. SMT breaks this bottleneck by demonstrating that recurrent pretraining can be reframed as an offline supervised learning problem, completely bypassing the sequential gradient paths of BPTT.