Recursive Self-Aggregation Unlocks Deep Thinking in Large Language Models
Authors: Siddarth Venkatraman, Vineet Jain, Sarthak Mittal, Vedant Shah, Johan Obando-Ceron, Yoshua Bengio, Guillaume Lajoie, Glen Berseth, Brian R. Bartoldson, Bhavya Kailkhura, Nikolay Malkin, Moksh Jain
Paper: https://arxiv.org/abs/2509.26626
Code: https://github.com/HyperPotatoNeo/RSA
TL;DR
WHAT was done? The paper introduces Recursive Self-Aggregation (RSA), a novel test-time scaling method that treats LLM reasoning as an evolutionary process. Instead of refining a single solution or simply picking the best from a batch, RSA maintains a diverse population of candidate reasoning chains. Over multiple sequential steps, it directs the LLM to aggregate random subsets of this population, recursively generating improved solutions by cross-referencing and recombining useful intermediate steps. This hybrid approach combines the breadth of parallel exploration with the depth of sequential refinement. The authors also propose an “aggregation-aware” reinforcement learning (RL) strategy to explicitly train the LLM for this aggregation task, mitigating performance degradation that occurs with standard RL fine-tuning.
WHY it matters? RSA provides a powerful and general mechanism to significantly boost LLM reasoning capabilities without altering model parameters or requiring external verifiers. The key impact is that it allows smaller, more accessible models (e.g., a 4B parameter model) to achieve performance competitive with or even superior to much larger, specialized reasoning models on challenging tasks. This suggests that algorithmic efficiency at inference time is a viable and potent scaling vector, offering an alternative to ever-increasing pre-training compute. Furthermore, the success of aggregation-aware RL highlights a crucial insight: to maximize the potential of advanced inference strategies, LLM training objectives must be co-designed to align with them.

Details
The New Frontier of LLM Scaling: Inference-Time Compute
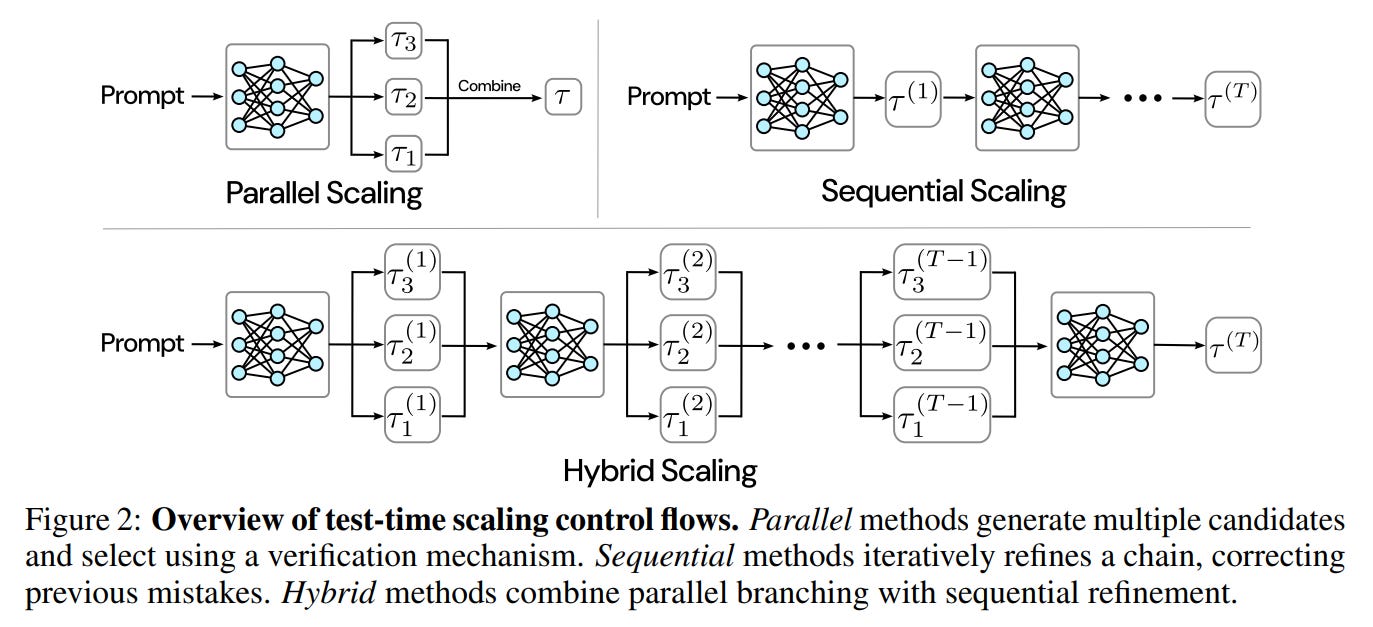
For years, the dominant paradigm for improving Large Language Model (LLM) capabilities has been scaling up: more data, more parameters, more training compute. However, a new frontier is emerging that focuses on more efficiently utilizing compute at inference time. Test-time scaling strategies aim to unlock deeper reasoning by allowing a model to “think” more before producing an answer. These methods typically fall into two camps: parallel scaling, which explores many reasoning paths at once (breadth-first), and sequential scaling, which iteratively refines a single path (depth-first).
This paper introduces Recursive Self-Aggregation (RSA), a novel hybrid framework that elegantly combines the strengths of both paradigms. By framing reasoning as an evolutionary process, RSA enables models to perform a more sophisticated, multi-step deliberation that consistently unlocks superior performance.